# Workopia - Complete Documentation
This file contains all documentation concatenated into a single file for easy consumption by LLMs.
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
## Table of Contents
This document includes all content from this project.
Each section is separated by a horizontal rule (---) for easy parsing.
---
# Account-setting
URL: https://workopia.io/account-setting
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Applications
URL: https://workopia.io/applications
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Ai-resume-tailor-every-job
URL: https://workopia.io/blog/ai-resume-tailor-every-job
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Best-free-mcp-servers-job-search-2026
URL: https://workopia.io/blog/best-free-mcp-servers-job-search-2026
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# How-to-search-jobs-with-ai-using-mcp
URL: https://workopia.io/blog/how-to-search-jobs-with-ai-using-mcp
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Workopia-vs-career-ops-ai-job-search
URL: https://workopia.io/blog/workopia-vs-career-ops-ai-job-search
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Career-pivot
URL: https://workopia.io/career-pivot
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Case-strategy
URL: https://workopia.io/case-strategy
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Keys
URL: https://workopia.io/dashboard/keys
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Future-vision
URL: https://workopia.io/future-vision
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Interview-vault
URL: https://workopia.io/interview-vault
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Jobs
URL: https://workopia.io/jobs
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Library
URL: https://workopia.io/library
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Workopia
URL: https://workopia.io
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Payment-success
URL: https://workopia.io/payment-success
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Pricing
URL: https://workopia.io/pricing
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Privacy
URL: https://workopia.io/privacy
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Profile
URL: https://workopia.io/profile
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# David-jones
URL: https://workopia.io/resources/interview-tips/christmas-casuals/david-jones
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# David-jones-logistics
URL: https://workopia.io/resources/interview-tips/christmas-casuals/david-jones-logistics
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# How-to-ace-christmas-casual-job-interviews-in-australia
URL: https://workopia.io/resources/interview-tips/christmas-casuals/how-to-ace-christmas-casual-job-interviews-in-australia
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Hugo-boss
URL: https://workopia.io/resources/interview-tips/christmas-casuals/hugo-boss
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Jb-hi-fi
URL: https://workopia.io/resources/interview-tips/christmas-casuals/jb-hi-fi
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Lululemon
URL: https://workopia.io/resources/interview-tips/christmas-casuals/lululemon
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Muji
URL: https://workopia.io/resources/interview-tips/christmas-casuals/muji
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Myer
URL: https://workopia.io/resources/interview-tips/christmas-casuals/myer
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Christmas-casuals
URL: https://workopia.io/resources/interview-tips/christmas-casuals
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Ralph-lauren
URL: https://workopia.io/resources/interview-tips/christmas-casuals/ralph-lauren
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Walk-in-job-hunting-guide-australia
URL: https://workopia.io/resources/interview-tips/christmas-casuals/walk-in-job-hunting-guide-australia
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# David-jones-christmas-casual
URL: https://workopia.io/resources/interview-tips/david-jones-christmas-casual
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# David-jones-logistics-christmas-casual
URL: https://workopia.io/resources/interview-tips/david-jones-logistics-christmas-casual
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Anz-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/anz-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Bhp-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/bhp-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Commbank-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/commbank-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Deloitte-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/deloitte-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Ey-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/ey-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Kpmg-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/kpmg-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Macquarie-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/macquarie-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Nab-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/nab-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Finance-strategy
URL: https://workopia.io/resources/interview-tips/finance-strategy
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Pwc-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/pwc-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Telstra-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/telstra-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Westpac-finance
URL: https://workopia.io/resources/interview-tips/finance-strategy/westpac-finance
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Atlassian
URL: https://workopia.io/resources/interview-tips/graduate-interns/atlassian
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Canva
URL: https://workopia.io/resources/interview-tips/graduate-interns/canva
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Commonwealth-bank
URL: https://workopia.io/resources/interview-tips/graduate-interns/commonwealth-bank
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Deloitte
URL: https://workopia.io/resources/interview-tips/graduate-interns/deloitte
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Deloitte-consulting
URL: https://workopia.io/resources/interview-tips/graduate-interns/deloitte-consulting
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Deloitte-data
URL: https://workopia.io/resources/interview-tips/graduate-interns/deloitte-data
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# How-to-ace-graduate-program-interviews-australia
URL: https://workopia.io/resources/interview-tips/graduate-interns/how-to-ace-graduate-program-interviews-australia
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Macquarie
URL: https://workopia.io/resources/interview-tips/graduate-interns/macquarie
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Graduate-interns
URL: https://workopia.io/resources/interview-tips/graduate-interns
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Pwc-audit
URL: https://workopia.io/resources/interview-tips/graduate-interns/pwc-audit
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Pwc-consulting
URL: https://workopia.io/resources/interview-tips/graduate-interns/pwc-consulting
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Pwc-technology
URL: https://workopia.io/resources/interview-tips/graduate-interns/pwc-technology
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Telstra
URL: https://workopia.io/resources/interview-tips/graduate-interns/telstra
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Telstra-government
URL: https://workopia.io/resources/interview-tips/graduate-interns/telstra-government
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Ubs
URL: https://workopia.io/resources/interview-tips/graduate-interns/ubs
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Hugo-boss-christmas-casual
URL: https://workopia.io/resources/interview-tips/hugo-boss-christmas-casual
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Jb-hi-fi-christmas-casual
URL: https://workopia.io/resources/interview-tips/jb-hi-fi-christmas-casual
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Lululemon-christmas-casual
URL: https://workopia.io/resources/interview-tips/lululemon-christmas-casual
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Muji-christmas-casual
URL: https://workopia.io/resources/interview-tips/muji-christmas-casual
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Myer-christmas-casual
URL: https://workopia.io/resources/interview-tips/myer-christmas-casual
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Ralph-lauren-christmas-casual
URL: https://workopia.io/resources/interview-tips/ralph-lauren-christmas-casual
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Afterpay-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/afterpay-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Airwallex-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/airwallex-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Anz-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/anz-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Atlassian-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/atlassian-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Bhp-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/bhp-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Canva-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/canva-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Carsales-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/carsales-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Coles-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/coles-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Commbank-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/commbank-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Domain-group-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/domain-group-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Domain-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/domain-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Macquarie-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/macquarie-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Nab-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/nab-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Tech-interviews
URL: https://workopia.io/resources/interview-tips/tech-interviews
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Rio-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/rio-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Rio-tinto-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/rio-tinto-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Seek-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/seek-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Seek-tech-interview-v2
URL: https://workopia.io/resources/interview-tips/tech-interviews/seek-tech-interview-v2
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Telstra-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/telstra-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Westpac-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/westpac-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Woolworths-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/woolworths-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Xero-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/xero-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Zip-co-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/zip-co-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Zip-tech-interview
URL: https://workopia.io/resources/interview-tips/tech-interviews/zip-tech-interview
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Resources
URL: https://workopia.io/resources
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Resume-lab
URL: https://workopia.io/resume-lab
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Sign-in
URL: https://workopia.io/sign-in
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Terms
URL: https://workopia.io/terms
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Trends
URL: https://workopia.io/trends
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# Workflow
URL: https://workopia.io/workflow
> AI-powered job search, resume builder, resume tailor, cover letter generator, and career advice. Free MCP server for Claude Desktop, ChatGPT, OpenClaw, Cursor, and any MCP-compatible AI assistant.
---
# The Modern ML Engineer: 2026 Market Analysis, Skill Blueprint, and Career Pivot Guide (part 2)
Source: articles/career-pivot/da-to-ml-engineer-career-switch.mdx
Machine Learning Engineering has become the most critical — and most compensated — bridge role in enterprise technology.
As AI moves from research labs into production infrastructure, organisations no longer just need people who can train models.
They need engineers who can deploy them, monitor them, scale them, and keep them running at 24/7 reliability.
Market Snapshot 2026:
- $187,500: US median ML Engineer salary
- 78%: of postings are mid-level roles
- 43%: of US jobs in California + New York
- $350K+: senior / principal total compensation
Figure 1: Comparison of market demand and salary growth projected through 2026.
5. The Pivot Playbook: Data Analyst to ML Engineer
The path from Data Analyst to ML Engineer is one of the most structurally logical career pivots in technology.
The analytical foundations are directly transferable. The gap is specific and learnable.
And the compensation uplift — from a typical analyst range of $70K–$100K to mid-level ML Engineer rates of $150K–$220K — is among the highest available in a single career transition.
| ✓ What You Already Bring |
→ What You Need to Build |
| Data cleaning, preprocessing, and feature engineering fundamentals |
SQL fluency for pipeline construction and data querying |
| Statistical reasoning: probability, hypothesis testing |
MLOps stack: Docker, Kubernetes, AWS SageMaker |
| Exploratory data analysis (Tableau / Power BI) |
GenAI stack: LLMs, RAG architectures, Prompt Engineering |
6. A Structured 12-Month Pivot Timeline
Months 1–3 — Production Python
Move from notebook scripting to production-grade code. Learn testing (pytest) and Git.
Months 3–6 — MLOps Foundations
Docker, Kubernetes basics, and one cloud ML platform (AWS/Azure).
Months 6–12 — GenAI & Portfolio
Build a working RAG application. Prepare for system design interviews.
This article is part of the Career Pivot Navigator series from HéraAI.
---
# From Intern to Principal: The Complete Data Science Career Playbook for 2026
Source: articles/career-pivot/data-scientist-cheatsheet-2026.mdx
The data science job market in 2026 is defined by a paradox: unprecedented demand for talent, yet increasing barriers to entry for newcomers. This playbook breaks down exactly what you need at each career stage.
The 2026 Landscape
According to industry reports, the data science field continues to evolve at a rapid pace. Companies are seeking professionals who can bridge the gap between technical implementation and business impact.
34%
Projected growth through 2034
$112,590
Median annual wage
Career Progression Framework
Career Progression Framework
Junior Data Scientist (0-2 years)
- Focus on technical fundamentals
- Master Python, SQL, and core ML algorithms
- Build a strong portfolio with end-to-end projects
- Expected salary range: $75K - $95K
Senior Data Scientist (3-5 years)
- Lead cross-functional projects
- Develop business acumen
- Mentor junior team members
- Expected salary range: $130K - $180K
Principal Data Scientist (5+ years)
- Define technical strategy
- Influence company-wide data culture
- Drive organizational decision-making
- Expected salary range: $200K - $280K+
Key Skills for 2026
Technical Skills
- • LLM fine-tuning and prompt engineering
- • MLOps and deployment pipelines
- • Causal inference and experimentation
- • Cloud platforms (AWS, GCP, Azure)
Business Skills
- • Domain expertise in specific industries
- • Stakeholder communication
- • Project management
- • Strategic thinking
The path forward: The journey from intern to principal requires not just technical growth, but also the development of business intuition and leadership skills. Focus on measurable impact and continuous learning to accelerate your career progression.
```
---
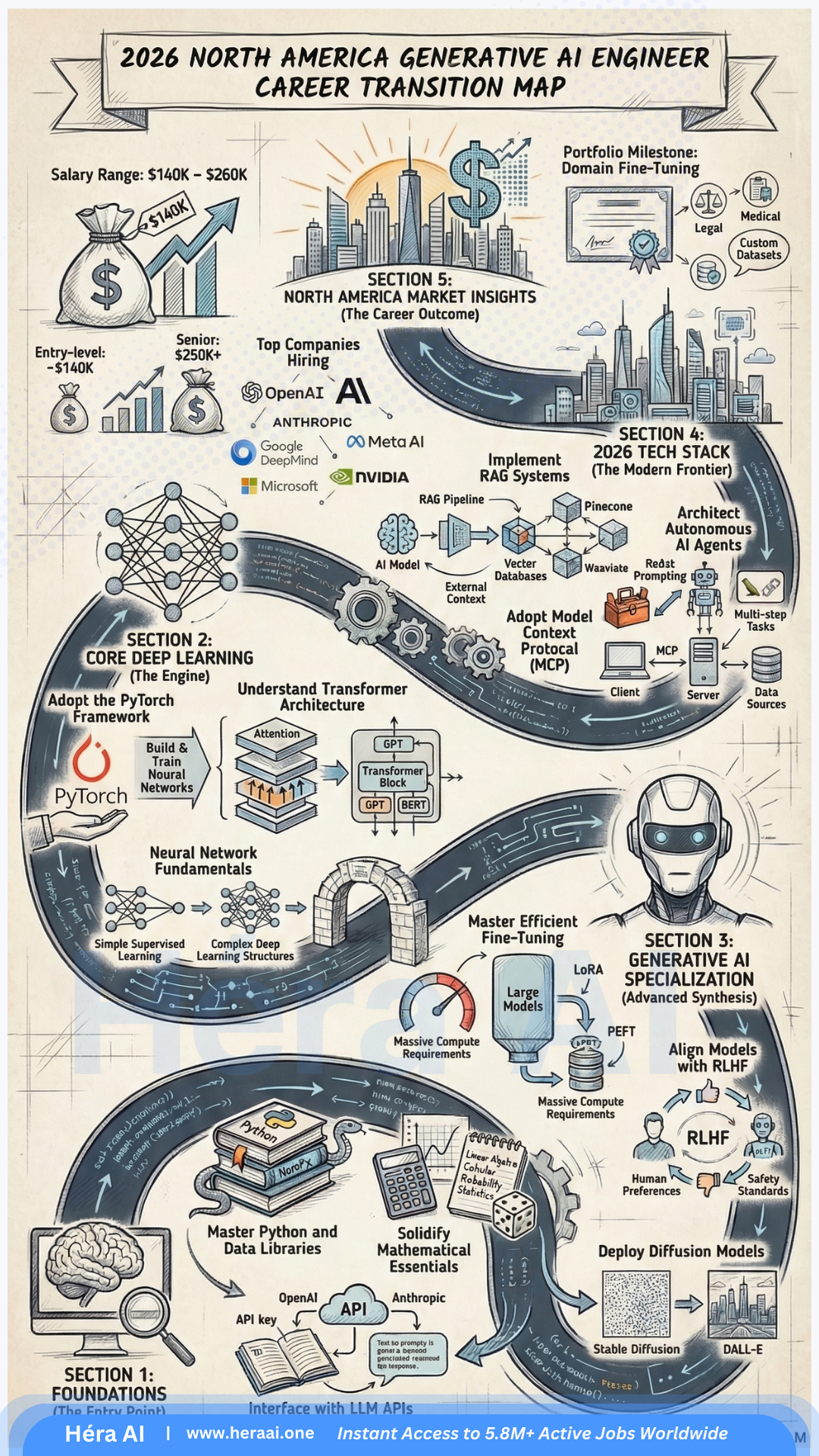
# The $200K Pivot: GenAI Engineer Career Guide 2025
Source: articles/career-pivot/genai-engineer-career-pivot.mdx
General software hiring is cautious. AI engineer demand is at fever pitch. The gap between those two sentences is the largest career opportunity in the current market — and it is accessible without a PhD.
By Carrie Yu · HéraAI · March 18, 2025
The current conversation about AI is dominated by displacement anxiety. The data tells a different story. What is happening in the labour market is not job erasure — it is job evolution, and the demand curve for engineers who can implement AI in production has effectively decoupled from the rest of the software hiring market. General tech hiring remains cautious. AI engineer hiring is accelerating.
The $200,000 average salary for Generative AI Engineers in 2025 reflects a genuine scarcity of talent that can move beyond API wrappers into production-grade AI systems — engineers who understand RAG architecture, context engineering, orchestration frameworks, and AI safety. The market is pricing that combination at a premium because it is structurally rare, and because the demand for it is arriving from every industry simultaneously.
{/* Stats Cards */}
$200K
average Generative AI Engineer salary in 2025 — range $140K–$260K
+90%
projected role growth over the next decade — one of the steepest demand curves in tech
6–18mo
realistic pivot timeline from backend, QA, or BI foundations to deployable AI engineer
RAG
Retrieval-Augmented Generation — the architecture that separates wrappers from real applications
{/* Image placeholder — replace filename */}
AI Researcher vs. AI Engineer: The Distinction That Opens the Market
The most persistent barrier to entering AI engineering is a misconception: that the field requires the ability to invent new neural architectures. It does not. A fundamental distinction has emerged in the 2025 market between the AI Researcher — who trains models from scratch — and the AI Engineer, who builds production applications using pre-trained models and existing AI tooling. These are different professions with different entry requirements.
| Dimension |
AI / ML Researcher |
AI Engineer ✓ The Pivot Path |
| Primary output |
Novel model architectures, academic papers, SOTA benchmark improvements |
Production applications that deliver measurable business value using existing models |
| Relationship to models |
Designs and trains models from scratch; requires deep mathematical foundations |
Selects, integrates, and optimises pre-trained models; focuses on application architecture |
| Typical background |
PhD or research Master's in ML, mathematics, or computational statistics |
Strong engineering fundamentals; Python proficiency; API and system integration experience |
| Market demand (2025) |
Concentrated at frontier labs (OpenAI, Anthropic, Google DeepMind, Meta AI) |
Broad demand across every industry sector integrating AI into products and workflows |
| Compensation ceiling |
$350K–$500K+ at frontier labs; highly concentrated and competitive supply |
$140K–$260K average; $200K median; rapidly expanding demand across non-frontier employers |
| Accessible via pivot? |
No — requires multi-year research training from foundational principles |
Yes — engineers with strong backend, QA, or BI foundations can pivot within 6–18 months |
The reframe that changes the calculus for every mid-career engineer: You are not tasked with reinventing the wheel. You are building the vehicle that uses the wheel to deliver enterprise value. The AI Engineer's job is implementation: selecting the right model for the task, building the architecture that feeds it the right data, ensuring it operates safely at production scale, and connecting its outputs to the business workflow that creates value. This is an engineering problem, not a research problem — and it is accessible to anyone with strong engineering fundamentals.
The Trojan Horse Strategy: Your Existing Skills Are the Entry Ticket
Strategic career switchers understand that they are not starting from zero. The IT skills that define competency in traditional engineering roles — Python, API integration, SQL, automation thinking, system architecture — are the same skills that underpin AI engineering at the implementation layer. The pivot is not a restart; it is a horizontal extension into a new application domain.
Backend Developer
→ AI Implementation Engineer / ML Infrastructure Engineer
Backend architecture experience maps directly to the service layer of AI applications: API orchestration, model endpoint management, latency optimisation, and the infrastructure that serves AI outputs to end users at scale.
QA / Test Engineer
→ AI Test Engineer / LLM Evaluation Specialist
The discipline of edge case thinking that defines good QA work is precisely what AI safety and model evaluation require. Adversarial testing, prompt injection detection, output regression testing, and hallucination rate monitoring are all extensions of QA methodology into a new domain.
BI / Data Analyst
→ Data Science / AI Analytics Engineer
SQL and data modelling skills transfer directly into the feature engineering and vector database query layer that underlies modern AI applications. A BI analyst who adds Python, vector database fluency, and RAG architecture knowledge has a complete profile for AI analytics roles.
DevOps / Platform Eng.
→ MLOps Engineer / AI Platform Engineer
The operationalisation of ML models — model versioning, deployment pipelines, A/B testing infrastructure, drift monitoring, and rollback mechanisms — is an extension of DevOps principles into the ML lifecycle. MLOps is one of the fastest-growing sub-specialisations within the AI engineering market.
Product Manager
→ AI Product Manager / AI Strategy Lead
The most in-demand non-engineering AI role in the 2025 market. PMs who understand AI capabilities and limitations — and can define product requirements that are technically achievable with current AI tooling — are structurally scarce. The pivot does not require coding fluency; it requires AI literacy deep enough to separate feasible from speculative.
The guiding principle for 2025 career pivot strategy: If you can debug a script, you can debug a model. The cognitive pattern of isolating a failure, forming a hypothesis about its cause, testing against edge cases, and iterating toward a fix is identical in both contexts. The domain knowledge is different. The engineering discipline is the same. The market is currently paying a $60K–$100K premium over general software engineering salaries to engineers who have made this connection and built the AI-specific skills on top of their existing foundation.
Wrappers vs. Real Applications: The Context Engineering Stack
The compensation gap between a $100K entry-level AI role and a $200K–$260K senior AI engineering role maps almost exactly onto one technical distinction: the ability to build a context engineering stack rather than an API wrapper. The market is oversupplied with engineers who can call an LLM API. It is structurally undersupplied with engineers who can build the retrieval, orchestration, and safety layers that make an AI application enterprise-deployable.
API Wrapper (Entry Level)
- ✗ Direct OpenAI / Anthropic API calls with no intermediate layer
- ✗ Static system prompts with no dynamic context injection
- ✗ No retrieval layer — model relies on training data alone
- ✗ No memory management — context window fills and truncates
- ✗ No safety layer — raw model output sent directly to users
This is the starting point, not the destination. API wrappers are buildable by anyone with basic Python knowledge. They command entry-level salaries and are immediately replicable by the next developer.
Context Engineering Stack (Elite Tier)
- ✓ RAG architecture: vector database retrieval injects private enterprise data into model context
- ✓ Orchestration layer (LangChain / LlamaIndex) manages multi-step reasoning and tool calls
- ✓ Context compaction: summarisation strategies prevent context window overflow
- ✓ Context isolation: role-based access control determines which data each user's context receives
- ✓ Safety layer: prompt injection detection, output filtering, adversarial testing protocols
This is what enterprises pay $200K–$260K for. The engineer who can build this stack is not building a chatbot — they are building an AI system that handles private enterprise data safely, reasons across multiple information sources, and maintains accuracy at production scale.
AI Safety: The Competitive Moat That Justifies the Top-Tier Premium
As enterprises move from AI pilots to AI production systems, the risk calculus changes. A chatbot prototype that occasionally produces incorrect output is an inconvenience. An enterprise AI system that handles HR records, financial data, or customer PII and occasionally produces incorrect or leaked output is a liability event. The engineers who can build safety into the architecture — not as an afterthought but as a foundational design constraint — are the ones who unlock the enterprise contracts that pay at the top of the market range.
Prompt Injection Attacks
What it addresses: Malicious inputs embedded in user queries that attempt to override system instructions or extract private data
An enterprise AI application that handles HR data, financial records, or customer PII is a direct target for prompt injection. An engineer who cannot demonstrate injection detection and mitigation in their portfolio is not deployable in regulated enterprise environments — which represent the majority of high-value AI implementation contracts.
Bias and Fairness Auditing
What it addresses: Systematic evaluation of model outputs across demographic, geographic, and categorical subgroups to identify differential treatment
The EU AI Act and emerging US AI regulation require documented bias assessments for high-risk AI applications. Engineers who can perform and document fairness audits are a regulatory compliance asset — not just an ethical preference. This skill has direct financial value in regulated industries.
Adversarial Testing
What it addresses: Structured attempts to break the system: edge case inputs, out-of-distribution queries, jailbreak attempts, and stress testing of safety constraints
Production AI systems encounter adversarial users by default. An engineer who has only tested their application on well-formed inputs has not tested their application. Adversarial testing methodology is the QA discipline applied to AI safety — and it is the skill that converts a functional prototype into a deployable enterprise product.
Context Isolation
What it addresses: Architectural controls that ensure each user or role only receives model context appropriate to their access level
In a multi-tenant enterprise RAG application, a junior analyst must not receive context that contains executive compensation data, even if that data exists in the same vector database. Context isolation is not a security afterthought — it is the foundational architectural requirement that makes enterprise RAG legally deployable.
Output Monitoring
What it addresses: Logging, sampling, and automated evaluation of model outputs in production to detect drift, hallucination rates, and policy violations
A model that performed well at launch will degrade over time as the world changes and its training data becomes stale. Output monitoring is the mechanism that surfaces this degradation before it becomes a business incident. Engineers who build monitoring into their systems from day one are demonstrating production maturity that justifies the senior-tier compensation premium.
The principle that defines the AI engineering opportunity in 2025: The barrier to entry is lowering for engineers with strong logical foundations. The rewards are increasing for engineers who can direct the machine's intent — who understand not just how to call an API, but how to build the context, safety, and orchestration architecture that makes an AI system trustworthy at enterprise scale. In a world where AI can write the code, the engineers who decide what the code should do, what data it should see, and what it must never do are the ones the market is paying $200K for. That is the pivot.
This article is part of the Career Pivot Navigator series from HéraAI — Instant Access to 5.8M+ Active Jobs Worldwide.
---
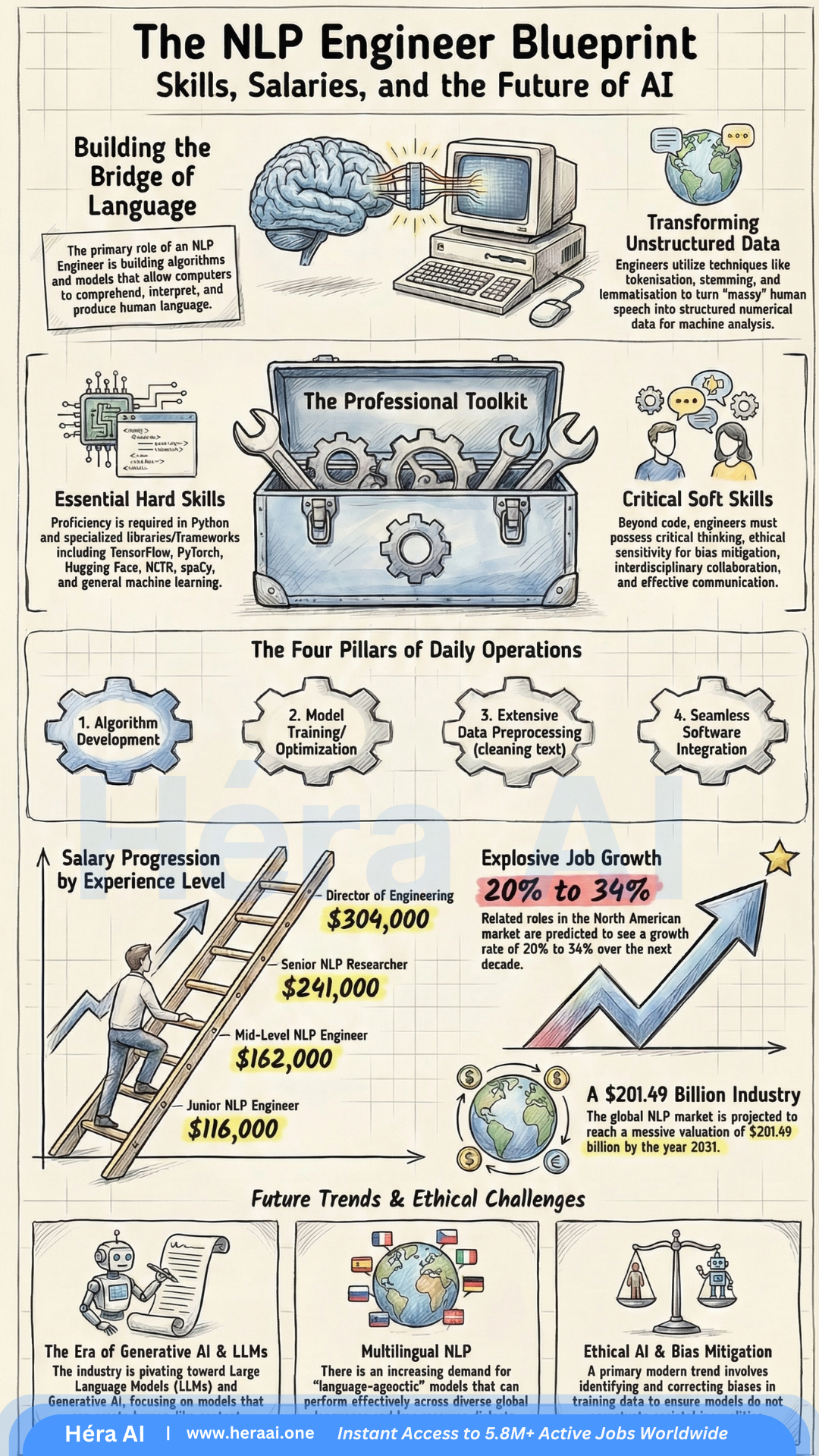
# The NLP Gold Rush: 5 Truths About the 2026 Job Market Every Candidate Needs to Know
Source: articles/career-pivot/nlp-blueprint-career-guide.mdx
The global NLP market is projected to surpass $201 billion by 2031. The opportunity isn't scarce — the talent to seize it is.
By Carrie Yu · HéraAI · March 15, 2026
The AI boom has created a landscape defined by equal parts immense opportunity and real confusion. While 'AI' has become a corporate buzzword, the most lucrative and stable career opportunities are concentrating within a specific discipline: Natural Language Processing.
NLP is the engine behind the Generative AI revolution — the technology allowing machines to grasp, interpret, and generate human language. And right now, the market is desperately short on people who can build it well. Surviving the 2026 hiring cycle requires more than a certificate. It requires a strategic understanding of how the technical and economic pieces actually fit together. Here are five truths that will change how you approach this market.
{/* Stats Cards */}
$201B
projected global NLP market by 2031
$116K
median salary for Junior NLP Engineers
$304K
ceiling for Director of Engineering roles
{/* Image — replace filename with actual image */}
1. The 'Junior' Label Is a Misnomer — And the Salary Floor Reflects That
One of the most persistent myths in tech hiring is that 'Junior' roles in AI are low-paying entry points. In the NLP world, that label describes what is, in practice, a high-impact engineering role with a salary floor most industries reserve for senior staff.
The reason the floor is this high comes down to one thing: human ambiguity. Even a baseline NLP role requires the ability to teach machines to parse the messiness of human intent — sarcasm, context shifts, cultural inference, contradictory phrasing. That's not a skill that scales easily.
Junior NLP Engineer
$116,000
median base salary
Senior NLP Researcher
$241,000
median base salary
Director of Engineering
$304,000
reported ceiling
What this means for you: These figures aren't just attractive compensation data — they reflect genuine talent scarcity. Companies are paying this much because they can't find enough people who can bridge computational linguistics and deep learning. That gap is your leverage.
2. Linguistic Intuition Is the Differentiator That Separates Good Candidates from Hired Ones
Thousands of candidates can list PyTorch and TensorFlow on their resume. Far fewer can explain why a model fails to handle sarcasm — or what it would take to fix it.
That distinction is linguistic intuition: the ability to reason about the gap between what a model processes and what a human actually means. It's not a soft skill. It's a technical design capability. The most effective NLP engineers understand the structural difference between syntax (how language is arranged) and semantics (what it actually means). That understanding directly shapes model architecture decisions — which training signals to weight, which evaluation metrics to trust, and where the model is likely to fail silently.
What Linguistic Intuition Looks Like in Practice
Failure diagnosis
Identifying why a model underperforms on negation, irony, or code-switching between languages.
Architecture decisions
Choosing the right tokenization and embedding strategy based on the linguistic properties of your data.
Evaluation design
Knowing which benchmark metrics actually reflect real-world language behavior versus those that reward overfitting.
Cross-cultural sensitivity
Understanding how idioms, humor, and register shift across demographics and languages.
Interview signal: When asked about model limitations, don't just describe the technical failure. Explain the linguistic phenomenon behind it. That's the answer that gets offers.
3. Bias Mitigation Is Now a Hard Engineering Skill — Not an Ethics Elective
The industry has moved from 'pure tech' to 'responsible tech.' In the 2026 hiring landscape, if you can't speak concretely to bias mitigation, you're a liability — particularly for roles in hiring, law enforcement, healthcare, and customer service, where biased model outputs carry legal and operational consequences.
The framing shift that matters: stop treating debiasing as an ethical consideration and start treating it as a technical requirement embedded in your engineering pipeline.
Bias Mitigation: The Technical Toolkit
Active Annotation
Auditing training data to systematically identify and flag prejudiced or unrepresentative language before model training begins.
Data Scrubbing
Removing or re-weighting data points that encode societal inequalities, with documented methodology that can be reviewed by stakeholders.
Evaluation Loops
Building detection metrics into the pre-deployment pipeline specifically designed to catch biased outputs across demographic subgroups.
Counterfactual Testing
Evaluating whether model outputs change when protected attributes (race, gender, age) are swapped in otherwise identical inputs.
The hiring reality: Senior hiring managers increasingly treat bias mitigation fluency as a minimum bar, not a bonus. Candidates who can walk through a concrete debiasing pipeline — with specific tools and metrics — stand out immediately.
4. Transformer Architecture Is the Baseline — Know It Beyond the Buzzwords
The 2026 interview room has moved past recurrent neural networks. The baseline expectation is a genuine understanding of the Transformer architecture: not just that it works, but why it outperforms earlier approaches and what its actual limitations are.
The key insight: Transformers solved the long-range dependency problem that made RNNs unreliable for complex language tasks. The self-attention mechanism allows the model to evaluate all tokens in a sequence simultaneously, rather than processing them sequentially and losing context over distance.
Core Transformer Concepts for 2026 Interviews
Self-Attention Mechanisms
How the model assigns importance weights across all tokens in a sequence simultaneously, enabling parallel processing and long-range context capture.
Bidirectional Context (BERT)
Why reading left-to-right and right-to-left simultaneously produces richer contextual representations than unidirectional models.
Cross-lingual Transfer Learning
Applying knowledge from a high-resource language to improve performance in a lower-resource one — increasingly required for global product deployments.
Fine-tuning vs. Pretraining trade-offs
When to adapt an existing model versus train from scratch, and how to justify that decision under compute and data constraints.
💡 Expert Tip — The Lemmatization vs. Stemming Question
This question appears in production-level interviews to test whether you understand linguistic accuracy versus computational efficiency trade-offs.
Stemming
Faster but rule-based — it often produces non-standard roots (e.g., 'comput' from 'computing') that create noise in downstream tasks.
Lemmatization ✓
Uses morphological analysis to return a valid dictionary form (e.g., 'run' from 'running') — the only defensible choice for high-stakes applications where output quality is non-negotiable.
The answer that wins the room: state the trade-off explicitly, then defend lemmatization with a specific production context.
5. Portfolios Are the New Resume — Build Projects That Prove Production Readiness
Theoretical knowledge is a commodity. In 2026, what separates shortlisted candidates from the rest is demonstrated ability to build systems that handle real-world messiness — not clean benchmark datasets.
The rise of Shadow AI (employees using AI tools outside official IT channels) and AI Democratization means hiring managers are increasingly evaluating whether you can build the tools others are already using. Your portfolio is where you prove that.
Project 1
Sentiment Analysis with edge case handling
Specifically addressing negation ('not bad'), sarcasm, and mixed-sentiment documents. Shows you've thought beyond the tutorial.
Project 2
Conversational Agent using LangChain
Demonstrates you can build the exact infrastructure driving enterprise AI adoption — and that you understand multi-turn context management.
Project 3
Named Entity Recognition (NER)
Structured data extraction from unstructured text. Highly valued in legal, healthcare, and finance applications.
Project 4
Cross-lingual model evaluation
Testing a multilingual model on a low-resource language shows awareness of the next frontier in NLP deployment.
🎯 Interview Tactic — The Out-of-Vocabulary (OOV) Problem
A major red flag for hiring managers is a candidate who can't articulate a strategy for handling words the model has never seen. The answer interviewers are looking for:
Byte Pair Encoding (BPE)
Breaks unknown words into subword units, enabling the model to construct a reasonable representation from familiar components.
FastText
Uses character n-grams to build word representations, making it robust to misspellings and morphological variations.
Mentioning either approach, with a clear explanation of when you'd choose one over the other, signals genuine production experience.
The portfolio principle: Every project you include should answer one question for the hiring manager: 'Can this person handle the failures that don't appear in documentation?' Show the edge cases you solved, not just the pipelines you built.
The Future Belongs to Engineers Who Ensure AI Truly Understands Language
As AI Democratization accelerates, the number of people who can use the tools will grow rapidly. The number who can ensure those tools are accurate, ethical, and genuinely language-aware will remain scarce.
The engineers who define this next phase won't just generate text. They'll be part linguist, part engineer, part strategist — capable of navigating the boundary between what a model outputs and what a user actually needs. The field is moving toward multilingual embeddings, complex discourse analysis, and real-time adaptive systems. The candidates who thrive will be the ones who understand not just how these systems work, but why they sometimes don't — and what it takes to fix them.
At HéraAI, that's the level of strategic clarity we help engineers develop. The NLP market in 2026 rewards engineers who combine technical depth with linguistic intuition — and who can prove it through shipped projects, not just credentials.
This article is part of the Career Pivot Navigator series from HéraAI — Instant Access to 5.8M+ Active Jobs Worldwide.
---
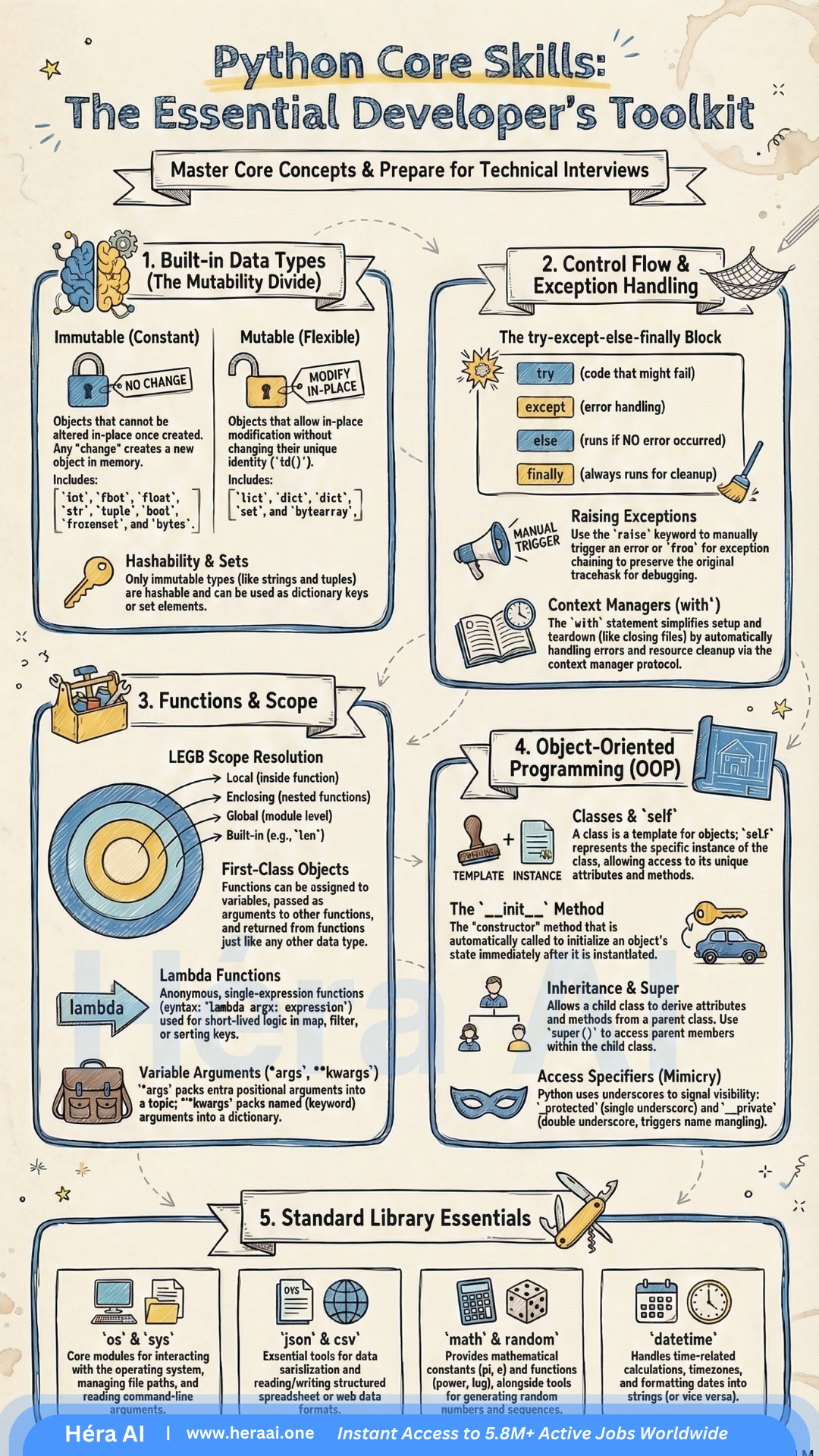
# The 5 Python Skills That Actually Get You Hired in 2026
Source: articles/career-pivot/python-core-skills-toolkit-2026.mdx
Most candidates know Python. Fewer can explain their code under pressure. Here's the difference — and how to close it before your next technical screen.
By Carrie Yu · HéraAI · March 14, 2026
Recruiters are not impressed by GitHub repos, bootcamp certificates, or the phrase 'strong Python skills.' What passes a technical screen in 2026 is something more specific: the ability to explain your reasoning under pressure. Why did you choose that data structure? What happens if this function receives an unexpected type? What does Python actually do with that try-except block?
The five skill areas below are not exhaustive Python knowledge — they are the specific domains that separate candidates who fumble under questioning from those who don't. Each one has a surface-level answer that gets you partway through a screen, and a deeper answer that actually gets you hired.
{/* Stats Cards */}
5
core Python skill areas that determine interview outcomes
else
the try-except block most candidates don't know exists
LEGB
the scope resolution rule that decides every closure question
__
double underscore — the OOP concept that filters senior candidates
{/* Image — replace filename with actual image */}
{/* Overview Table */}
The Five Skills at a Glance — What's Really Being Tested
Before going deep on each skill, it's worth mapping what interviewers are actually evaluating. The questions aren't about definitions. They're designed to expose whether you understand trade-offs, can predict behaviour, and have built things that work in the real world.
| # |
Skill Area |
The Real Interview Trap |
What's Actually Being Tested |
| 01 |
Built-in Data Types |
Why can't a list be a dictionary key? |
Predicting behaviour from mutability rules — not reciting type lists |
| 02 |
Control Flow & Exceptions |
Do you know the else block in try-except? |
Writing intentional, production-aware error handling — not reactive patching |
| 03 |
Functions & Scope |
Trace this closure: what value does the nested function return? |
LEGB mastery + first-class functions + API design instincts |
| 04 |
Object-Oriented Design |
Why would you use inheritance here, and what are the risks? |
Systems thinking — encapsulation, extension, and trade-off reasoning |
| 05 |
Standard Library Fluency |
Which stdlib modules did you use in your last project, and why? |
Engineering maturity — using what exists before building from scratch |
The meta-skill beneath all five: Technical interviews in 2026 are judgment tests, not memory tests. The strongest candidates don't just answer the question — they volunteer the trade-off. 'I used a tuple here because it's immutable and hashable, which matters because...' That instinct to lead with why signals the engineering maturity that senior tracks are looking for.
01 — Built-in Data Types: It's About Mutability, Not Memorisation
Most candidates can list Python's built-in types. Fewer can predict what happens when those types interact with the language's fundamental mechanisms — and that distinction is exactly what interviewers are probing when they ask about data types.
The core question is always some version of: 'Can you reason about behaviour from first principles?' The most commonly used probe is the dictionary key question, because it requires understanding the relationship between mutability, hashability, and Python's internal dictionary implementation.
✓ Immutable (hashable → valid dict key)
- • int, float, complex
- • str
- • tuple
- • frozenset
- • bytes
- • bool
✗ Mutable (not hashable → invalid dict key)
- • list
- • dict
- • set
- • bytearray
- • Custom objects (default)
- • array.array
Interview principle: Immutable types are hashable because their value cannot change after creation — so a consistent hash is always producible. Mutable types cannot guarantee a stable hash, which would break dictionary lookup integrity. The reasoning chain interviewers want to hear: mutable types can change their content after creation → a consistent hash cannot be guaranteed → Python's dict requires stable hashes for key lookup → mutable types cannot be dictionary keys.
Career hack from HéraAI analysis: In interviews, always lead with why you chose a data structure — not just what it does. 'I used a frozenset here because the collection won't change and I need to use it as a dictionary key later' signals the kind of forward-thinking that distinguishes a mid-level candidate from a senior one.
02 — Control Flow & Exception Handling: Stop Writing Fragile Code
The try-except block is one of the most underused tools in a junior developer's arsenal, and one of the most incorrectly used in a mid-level one. The pattern most candidates know — try and except — is the minimum. The full four-block structure is what interviewers use to filter candidates who write intentional code from those who write reactive code.
try
Code that might raise an exception
Keep this block narrow — wrap only the specific operation that can fail, not the entire function body.
except
Handles the error if one is raised
Always catch specific exception types (except ValueError:), never bare except:. Catching everything hides bugs and makes debugging production incidents significantly harder.
else
Runs only if no exception was raised ⭐
The filter block most candidates don't know exists. Use it for logic that should only run on success — separating the 'happy path' from error handling makes intent explicit.
finally
Always runs — exception or not
Resource cleanup: closing files, releasing locks, terminating connections. Equivalent to using a context manager (with statement), which is the preferred pattern for resource management.
The context manager signal: In behavioral interviews, describing a time you used a with statement for resource cleanup — file handles, database connections, network sockets — signals production awareness. The with statement implements the context manager protocol (__enter__ and __exit__), which guarantees cleanup even if an exception is raised. This is the preferred pattern over try/finally for resource management.
03 — Functions & Scope: The One Most Candidates Skip
LEGB is four letters that appear in more Python interview questions than any other single concept. Python resolves variable names in exactly one order: Local → Enclosing → Global → Built-in. If you can't trace through a closure and explain precisely which value a nested function will use — without running the code — you will fail live coding screens at the mid-level and above.
Functions & Scope — What Strong Candidates Know
LEGB in practice
Python looks for a variable name in the local scope first, then in any enclosing function scopes (for closures), then at the module level, then in Python's built-in namespace. The first match wins. If no match is found, a NameError is raised.
First-class functions
In Python, functions are objects. They can be passed as arguments, assigned to variables, stored in data structures, and returned from other functions. This is the foundation of decorators, callbacks, and every functional programming pattern in Python.
Lambda functions
Single-expression anonymous functions (lambda x: x * 2). Know when to use them — sort keys, map/filter, short callbacks — and when not to. Anything requiring more than one expression, a docstring, or meaningful readability should be a named function.
*args and **kwargs
Not just syntax — a signal that you understand flexible API design. *args collects positional arguments into a tuple; **kwargs collects keyword arguments into a dict. Demonstrating them in an interview shows you can build APIs that don't break when requirements change.
Closures and the nonlocal keyword
A nested function that references a variable from its enclosing scope creates a closure. The nonlocal keyword allows the nested function to rebind that variable. This is the mechanism behind many factory functions and stateful decorators.
Interview technique: When asked to write a function, proactively mention scope and argument design. 'I'm using **kwargs here to keep the API flexible — callers can pass any additional parameters without breaking the function signature' signals the kind of API-level thinking that senior interviewers reward.
04 — Object-Oriented Programming: Think in Systems, Not Scripts
OOP questions in Python interviews are not about knowing what a class is. Every candidate knows what a class is. The interview is probing whether you understand why OOP exists — what problems it solves, when it creates more complexity than it resolves, and what the specific Python implementation details mean for how you design systems.
| Concept |
What It Is |
What the Interview Is Actually Probing |
| self |
The instance reference |
self is the specific object being operated on — not the class. Every instance method receives it as the first argument automatically. Candidates who can't articulate this distinction haven't built enough with classes under pressure. |
| __init__ |
The constructor |
Called automatically when a class is instantiated. Sets up the object's initial state. Confusing __init__ with __new__ (which creates the object before __init__ runs) is a common senior-level probe. |
| super() |
Parent class accessor |
Calls the parent class method without hardcoding the parent's name. Critical for clean inheritance chains — especially in multiple inheritance where Method Resolution Order (MRO) determines which parent is called. |
| _name |
Protected convention |
Signals 'internal use' to other developers. Not enforced by Python — it's a documentation convention. The underscore says 'you can access this, but you shouldn't unless you know what you're doing.' |
| __name |
Name mangling |
Becomes _ClassName__name internally. Prevents accidental override in subclasses. This is the one interviewers use to separate candidates who've read about access control from those who've debugged it in production. |
Design instinct that interviewers notice: When asked to design a system in an interview, default to OOP and explain your encapsulation decisions explicitly. 'I'm keeping this attribute private with a double underscore because it should only be modified through the update() method — direct access would bypass the validation logic' demonstrates exactly the architectural awareness that distinguishes a systems designer from a script writer.
05 — Standard Library Fluency: The Mark of a Self-Sufficient Developer
Knowledge of Python's standard library is a proxy for production experience. Candidates who reach for the right built-in module before writing a custom implementation signal two things: they've built enough real systems to know what already exists, and they understand that shipping fast and reliably matters more than writing everything from scratch.
os / sys
System + file operations
File path construction, environment variable access, command-line argument parsing. Essential for scripting, DevOps tooling, and any automation role. Know os.path.join() vs. pathlib.Path — the latter is now the preferred modern pattern.
json / csv
Data serialization
Parse and emit structured data. Every API integration and data pipeline uses these. Know the difference between json.loads() (string → object) and json.load() (file → object). Confusing them in a live screen is a red flag.
datetime
Time and date handling
Date arithmetic, timezone conversion, formatting with strftime() and strptime(). Underestimated until you're debugging a production incident at 2am caused by timezone-naive datetime objects in a UTC system.
math / random
Numerical and probabilistic
Mathematical constants (pi, e), power and log functions, random sampling and shuffling. Appears in ML-adjacent roles, simulation tasks, and anywhere approximation or stochastic behaviour is required.
collections
Specialised data structures
Counter, defaultdict, deque, OrderedDict, namedtuple. Candidates who reach for these instead of reimplementing them from scratch signal strong library awareness and production instincts.
Portfolio documentation signal: In your portfolio projects, document which standard library modules you used and why you chose them over third-party alternatives. 'I used pathlib.Path instead of os.path because the object-oriented interface is cleaner for complex path operations and it's the recommended modern pattern' demonstrates engineering maturity in a way that raw code does not.
Judgment, Not Memory
The five skill areas in this article share a common thread: they are all domains where the surface-level answer is easy to produce and insufficient to pass. Knowing that a tuple is immutable is the entry point. Understanding why that immutability matters for hashability, dictionary keys, and memory behaviour — and being able to articulate that reasoning without prompting — is what gets you hired.
Mastering these five areas doesn't just prepare you for interviews. It changes how you write code in practice: with more deliberate data structure selection, more intentional error handling, more thoughtful API design, and a clearer instinct for when to use what the language already provides rather than building it again. At HéraAI, the Interview Cheatsheet Vault is built to develop exactly this kind of depth — not just answers to specific questions, but the reasoning fluency that holds up when the interviewer pushes back.
This article is part of the Interview Cheatsheet Vault series from HéraAI — Instant Access to 5.8M+ Active Jobs Worldwide.
---
# Case 1 - Strategy Consulting Practice
Source: articles/case-strategy/case-1.mdx
#### Case 1: PE Portfolio Strategy — A Positive NPV Does Not Automatically Mean Go
Day 1 of 30. An AT Kearney-style private equity case in the automotive sensor market. The math is the starting point. The investment recommendation requires three layers of thinking that the NPV model cannot provide.
Case 1 establishes the foundational principle that runs through every case in this 30-day series: data supports the recommendation; it does not make it. The case is a PE portfolio strategy decision — whether to invest in a business operating in the automotive sensor market. The surface question is whether the NPV is positive at a 10% cost of capital. The real question is what a positive NPV means for an actual investment decision.
The automotive sensor market is growing at approximately 5% annually, driven by structural factors — electrification, autonomous driving requirements, and OEM safety mandates. The market is fragmented, meaning no single player has locked up a dominant position. These two facts — structural growth and fragmentation — make the market attractive on a surface read. The deeper analysis requires three layers of thinking that sit above the financial model.
PE strategy cases test a specific analytical maturity: the ability to move from 'the NPV is positive' to 'here is what the NPV means, here are the assumptions that drive it, here are the conditions under which the investment thesis holds, and here is what would have to be true for the investment to succeed.' That sequence — calculation to interpretation to recommendation — is the consulting skill that Day 1 is designed to introduce.
### Three Layers of Thinking Above the NPV Model
The NPV calculation is the starting point of the analysis, not the conclusion. Every PE strategy case requires three distinct analytical layers, each answering a different question about the investment decision.
The principle that Day 1 establishes for the entire 30-case series: 'Running an NPV analysis is relatively straightforward. Explaining what the result means for a real investment decision is not. Consulting is not about perfect calculations — it is about using data to support a clear, defensible recommendation. The NPV tells you whether the investment creates value under your assumptions. Strategy tells you whether the assumptions are right and whether the investment fits the broader portfolio. Both are required.'
### What PE Strategy Cases Are Really Testing
### The 5-Step Framework
The meta-lesson that Case 1 is designed to establish — foundational for every case in this series: A positive NPV does not automatically mean go. Especially in PE-style investment cases, the real value comes from asking: Does this opportunity fit the firm's broader strategy? What risks matter most in a fragmented competitive landscape? What would have to be true for this investment to succeed? Those questions do not live in a financial model — they come from structured thinking. This is the principle that governs every case that follows in this 30-day series.

---
# Case 10 - M&A Due Diligence
Source: articles/case-strategy/case-10.mdx
#### Case 10: Airlines and the Channel Tunnel — When a Superior Substitute Changes the Rules
The Channel Tunnel did not enter the London–Paris market on price. It entered on convenience, productivity, and total journey time — dimensions where airlines are structurally disadvantaged. The strategic response is not a fare war. It is a segmentation.
Case 10 is a competitive strategy case with a framing trap. The obvious response to a new competitor is defensive pricing — cut fares, increase frequency, match the threat. In this case, that response is wrong. The Channel Tunnel entered the London–Paris market not as a cheaper alternative but as a superior alternative on the dimensions that business travellers value most: door-to-door convenience, in-transit productivity, and schedule reliability. Competing on price against a structurally superior product on those dimensions destroys value without restoring share.
The more important analytical move is recognising that this is not a winner-takes-all market. Airlines and rail serve meaningfully different customer segments with meaningfully different deciding factors. City-centre point-to-point business travellers prefer rail. Passengers connecting to onward long-haul flights need airlines. Loyal corporate frequent flyers can be retained through programme investment. Leisure travellers split by price and preference. A single strategic response applied to all of these segments simultaneously is a strategy for none of them.
The case tests whether candidates can identify the correct competitive metric (door-to-door time, not in-air speed), segment the market before recommending, name the price war trap, and identify the durable advantages that rail cannot replicate. These four analytical moves — in sequence — produce a recommendation that is both credible and actionable.
### Competitive Dimension Analysis: Who Wins — and Why
The first analytical step is to map every relevant competitive dimension and determine where each mode holds a genuine advantage. The instinctive framing — airlines are faster — holds for in-air time only. On every other dimension that business travellers value, the picture is more complex.
The metric reframe that defines the entire case: 'Airlines are faster in the air. But the customer does not experience the journey as time in the air. They experience it as time from leaving their office to sitting in their meeting. On that metric — door-to-door — rail is competitive or superior on the London–Paris route. The strategic implication follows directly: airlines cannot defend their position by emphasising flight duration. They must defend it by emphasising what happens at the edges of the journey that rail cannot replicate — specifically, the connection to an onward global network.'
### Customer Segmentation: Five Segments, Five Different Outcomes
The London–Paris route is not a single market. It is five overlapping markets with different deciding factors, different competitive outcomes, and different implications for airline strategy. A recommendation that treats all passengers identically will be wrong for all of them.
### Strategic Response Options: What Works and What Destroys Value
The case offers several possible airline responses. Not all of them are viable — and the most tempting one (aggressive fare competition) is the one that interviewers are specifically testing whether candidates will recommend. The table below evaluates each option against the structural realities of the competitive situation.
The price war analysis that separates strong answers from average ones: 'Fare competition looks like an obvious response, but it is a structural trap. Both airlines and rail carry high fixed costs and low marginal costs — which means neither side can absorb sustained price reductions without significant margin erosion, and neither can easily exit capacity in the short term. A fare war initiated by airlines would force rail to respond, eroding profitability on both sides without changing the fundamental competitive position. Rail would still win on convenience; airlines would have simply paid a large financial cost to confirm that. The recommendation should name this dynamic explicitly and explain why differentiation — not price matching — is the correct response.'
### The 5-Step Framework
The meta-lesson that Case 10 is designed to teach — applicable to every substitute threat case: Competition is rarely about who is faster or cheaper. It is about which value proposition best fits each customer's definition of convenience. When a substitute enters on non-price dimensions — comfort, reliability, productivity, friction reduction — the incumbent's response cannot be purely defensive or purely price-based. The correct response is to identify which customer segments the substitute cannot serve well, concentrate the incumbent's advantages on those segments, and stop subsidising the segments where the structural disadvantage is permanent. Strong responses focus on differentiation and segmentation. Weak responses focus on defending everything with a price cut.

---
# Case 11 - Pricing Strategy
Source: articles/case-strategy/case-11.mdx
#### Case 11: Test Equipment Manufacturer — Redesigning the System That Creates Inventory
183 days of inventory. A best-in-class benchmark of 39 days. A 4-week delivery promise. And a 9-month custom component lead time. The inventory problem is visible — but the root cause is structural, and most candidates miss it entirely.
Case 11 is an operations case with a structural trap. The surface problem — 183 days of inventory versus a best-in-class benchmark of 39 days — looks like an operational efficiency problem. The actual problem is a supply chain architecture problem: the client holds this much inventory because the system was designed in a way that makes it rational to do so. The path from 183 days to the management target of 85 days requires system redesign, not inventory management optimisation.
The case is long (30–45 minutes) and rewards candidates who resist the urge to propose solutions before understanding the system. The first move is always to map the supply chain end-to-end: what is held, where it is held, why it is held there, and what constraints prevent it from being held further upstream or not held at all. Only after that mapping is complete does the root cause analysis become possible.
Three structural features of the supply chain explain the 183-day inventory level: 26,000 possible product configurations driven by subassembly combinatorics, a 9-month custom component lead time with low flexibility, and a 4-week delivery promise that mechanically pushes inventory upstream of demand. None of these can be resolved by better demand forecasting. Each requires a deliberate strategic choice.
### Understanding the Supply Chain: Mapping Before Solving
The first analytical requirement in this case is a complete supply chain map — from customer order to component procurement. Without this map, any proposed solution risks conflicting with a hard constraint that the candidate has not yet identified. The table below traces the full chain and identifies the strategic implication at each stage.
The operational question that reveals whether a candidate has mapped the supply chain correctly: 'If I wanted to hold zero subassembly inventory, what would have to be true about lead times and delivery promises?' The answer forces the candidate to calculate: custom component procurement (9 months) + subassembly manufacturing (1–2 weeks) + final assembly (1–2 weeks) = a delivery promise of approximately 10 months. The current 4-week promise is only possible because inventory is pre-built across the entire product range. This calculation makes the relationship between the delivery promise and the inventory level explicit — and it is the foundation of the recommendation.
### Why Inventory Is So High: Three Structural Root Causes
The 183-day inventory level is not a management failure. It is the rational output of a supply chain designed around three structural features. Understanding each one — and why forecasting improvement alone cannot resolve any of them — is the analytical core of Case 11.
### Reduction Levers: What Works, What Doesn't, and Why
Not all inventory reduction levers are viable within the case's hard constraints. The table below evaluates each lever against the structural realities of the supply chain — distinguishing genuine solutions from attractive-sounding ideas that conflict with the binding constraints.
The lever evaluation principle that interviewers are testing: 'Every proposed solution must be tested against the hard constraints before it is recommended. A lever that works in the abstract but conflicts with the 4-week delivery promise or the 9-month custom component lead time is not a viable recommendation — it is a wish. The discipline of testing each lever against the constraints is what distinguishes structured operational thinking from surface-level brainstorming. Name the constraint each lever is working with or around, and the recommendation becomes credible.'
### The 5-Step Framework
The meta-lesson that Case 11 is designed to teach — applicable to every operations and supply chain case: Inventory is rarely the root problem. It is the visible outcome of earlier strategic choices — product design architecture, delivery promise commitments, and supply chain structure. Great consultants do not just reduce inventory. They redesign the system that creates it. In Case 11, the system was designed to promise 4-week delivery on 26,000 configurations while holding 9-month custom component lead times. Reducing inventory to 85 days without changing any of those parameters is not feasible at the recommended level. A strong recommendation names which parameter must change — and quantifies what becomes possible when it does.

---
# Case 12 - Customer Segmentation
Source: articles/case-strategy/case-12.mdx
#### Case 12: Disaster Remediation — Should We Enter the Residential Cleaning Market?
A profitable disaster services company. A $50B adjacent market. Attractive math on paper. The real test: separating operational synergies from go-to-market reality — and knowing which one determines whether the entry succeeds.
Case 12 is a market entry case with a specific structural trap. The surface-level analysis — large market, feasible margins, some transferable capabilities — points toward 'yes.' The deeper analysis reveals that the capabilities that would make entry difficult are precisely the ones the client does not have. Adjacent market cases are rarely risky because the market is unattractive. They are risky because companies overestimate how much of their advantage actually transfers.
The case follows a natural four-step sequence: size the market, validate unit economics, assess the competitive landscape, and evaluate capability transfer. The sequencing matters — candidates who jump to capability assessment before doing the math are working without the permission structure that makes the recommendation credible. The market size and unit economics establish that entry is worth considering; the capability transfer analysis determines whether entry is viable.
The analytical distinction that separates strong answers from average ones in this case is the difference between operational capabilities (which transfer) and go-to-market capabilities (which do not). The work of residential cleaning is similar to disaster remediation. The business model is not. A candidate who conflates these two levels of analysis has missed the case.
### Step 1 — Market Sizing: The $50B Foundation
Market sizing is not a formality in this case — it is the first analytical gate. If the market were small or structurally unattractive, the entry question would be resolved before capability assessment begins. The top-down sizing approach below walks through each assumption and explains why it matters for the credibility of the final estimate.
The sizing principle that interviewers are testing: Interviewers are not evaluating whether you arrive at exactly $50B. They are evaluating whether your assumptions are defensible, whether the steps connect logically, and whether you can explain what would change the estimate if the assumptions shifted. A candidate who arrives at $45B through a clearly articulated approach scores higher than a candidate who states $50B without showing the work.
#### Step 2 — Unit Economics: What the Math Shows and What It Misses
The per-job unit economics check is straightforward: $75 revenue, $55 in direct costs, $20 gross margin per job (27%). The more important analytical move is naming what the gross margin calculation excludes — because those excluded costs are what determine whether the business is actually profitable at scale.
### Step 3 — Competitive Landscape and Positioning
The residential cleaning market is fragmented across three tiers: national players (approximately 10% share, quality-focused), regional players (approximately 20%, mixed positioning), and individual/informal operators (60–70%, price-driven). The positioning question is not whether the client can enter the market — the market is large enough to absorb new entrants. The question is where to play and why the client can win there.
The positioning answer that demonstrates strategic clarity: 'The client cannot compete on price with individual operators — their cost structure and overhead are categorically different. The natural competitive position is quality-focused, competing with national players on trust, reliability, and service consistency. The client's disaster remediation heritage is a genuine differentiator in a market where the primary purchase criterion is whether you can trust a stranger in your home. The positioning should make that heritage explicit.'
### Step 4 — Capability Transfer: The Make-or-Break Analysis
The most important analytical step in Case 12 is the rigorous separation of what transfers from the existing business and what does not. Most candidates identify some transferable capabilities and some gaps. The insight that separates strong answers is understanding that the go-to-market gap — not the operational gap — is the determinant of whether entry succeeds.
The insight that turns a competent answer into a strong one: 'The key analytical distinction is between the work and the business model. The work of residential cleaning is operationally similar to disaster remediation — the same physical capabilities, the same service standards, the same commitment to quality. But the business model is completely different. Disaster remediation customers are acquired through insurance companies; residential cleaning customers must be acquired directly. That single difference changes the marketing model, the unit economics, and the operational infrastructure required. Operational synergies are real but not sufficient. The go-to-market gap is the risk that determines the recommendation.'
### The 5-Step Framework
The meta-lesson that Case 12 is designed to teach — applicable to every adjacent market entry case: Adjacent expansion is seductive because it looks like growth with reduced risk — familiar capabilities, similar customers, related markets. The risk is not market attractiveness. It is capability overestimation. Good consultants validate the math. Great consultants question the assumptions underneath it — specifically, which capabilities will actually transfer and which ones will need to be built from scratch. Building from scratch costs time and money that the market size estimate never accounts for. The recommendation should acknowledge this gap explicitly and propose a sequenced approach that builds the missing capabilities before committing to full-scale entry.

---
# Case 13 - Supply Chain Optimization
Source: articles/case-strategy/case-13.mdx
#### Case 13: The Prestige Trap — When Brand Dilution Meets Operational Decay
A 25-year premium brand. A growth strategy that chased volume into the wrong segments. A distribution decision that destroyed the channel relationship that made the business viable. This is a two-front war — and it requires a two-front recovery.
Case 13 is one of the more demanding cases in the series — not because the individual analytical steps are complex, but because the problem has two independent root causes that must both be diagnosed before any recovery plan can be constructed. A candidate who focuses on costs misses the revenue diagnosis. A candidate who focuses on brand dilution misses the operational decay. The case is designed to test whether you can hold both problems in your analytical frame simultaneously.
The client is a premium bicycle manufacturer with a 25-year legacy in the Racing segment. Five years ago, facing a maturing Racing market, management made the decision to extend into Mainstream and Children's bike categories to capture volume. This decision — in itself — was not wrong. The execution was catastrophic.
The two failures are distinct and require separate diagnoses. First, the company attempted to sell its elite Racing bikes through the same mass distributors used for its Children's bikes — destroying the specialty retailer relationships that are the only viable channel for premium racing products. Second, while competitors invested in automation and modern maintenance practices, the client chose to 'maximise equipment life' through deferred maintenance, creating a self-inflicted 10% year-over-year cost spiral. Neither problem caused the other. Both problems must be fixed.
### Product Mix: Why Volume Growth Destroyed Profitability
The first analytical step is to quantify the product mix destruction — establishing that the Mainstream and Children's segment entries could not mathematically compensate for the Racing segment losses, regardless of the volume achieved. This calculation is the foundation of the recommendation to prioritise Racing segment recovery over further mass-market expansion.
The product mix arithmetic that the interviewer is listening for: 'To replace the profit from one Racing unit at $300, the client would need to sell six Children's units at $50 each. As Racing market share declined from 60% to 30%, the Children's segment would have needed to grow by six units for every Racing unit lost — just to break even on profit. In practice, the new segments did not grow at this rate, and Racing volume continued to decline. The expansion created a negative profit mix shift that compounded over five years.'
#### The Distribution Blunder: How One Channel Decision Destroyed a 25-Year Relationship
The Racing segment's market share decline is not a product failure. The Racing bike remained competitive on specification, quality, and performance. The cause was a single distribution decision that made it impossible for specialty retailers — the only credible channel for premium racing bikes — to continue selling the client's product.
The channel conflict principle that applies to every premium brand case: 'Channel decisions are brand decisions. Where a product is sold tells consumers and channel partners what the product is worth and who it is for. A premium product in a discount channel does not maintain its premium positioning — it loses it. And the loss is not contained to the discount channel: it contaminates every other channel where the same brand appears. The specialty retailer's response was rational. The only available protection for their own premium positioning was to replace the contaminated brand with a competitor's product. The client created the incentive for its own displacement.'
### Operational Decay: The Self-Inflicted Cost Spiral
The cost side of the profit decline is independent of the brand and channel problems — but it is equally structural. The 10% year-over-year cost increase is not driven by input price inflation or volume-driven overhead; it is driven by two management decisions that converted manageable costs into compounding liabilities.
### Recovery Levers: Sequenced by Priority
The recovery plan must address both the revenue problem (channel repair and brand protection) and the cost problem (maintenance and automation) in the correct sequence. Some actions are prerequisites for others — specifically, Racing must be removed from discount channels before any specialty retailer re-engagement can be attempted. The table below sequences the six recovery levers by timeline and priority.
### The 5-Step Framework
The meta-lesson that Case 13 is designed to teach — applicable to every brand extension and premium segment case: Growth for the sake of growth is a death trap when the growth strategy requires compromising the conditions that make the core business viable. The client's Racing segment was the golden goose — the highest-margin product, sold through a channel that required brand exclusivity to function. The growth strategy did not just fail in the new segments; it killed the golden goose. Strategy is as much about deciding what not to do as it is about where to grow. A candidate who articulates this principle — and names the specific decision that violated it — has demonstrated the strategic maturity that Case 13 is designed to test.


---
# Case 14 - Brand Strategy
Source: articles/case-strategy/case-14.mdx
#### Case 14: The Private-Label Peril — Defending Your Brand Against the Store Brand Surge
A branded cookie leader. A flat market. A private label growing from 0% to 20% in five years. This is not a case with one right answer — it is a case that tests whether you can take a position and defend it under conditions that are deliberately ambiguous.
Case 14 is a grey-area case — a category designed not to test whether the candidate can find the correct answer, but whether they can commit to a defensible position when the data supports more than one conclusion. The client is a leading U.S. branded cookie manufacturer whose sales have declined from $600M to $560M over the past two and a half years, in a market that has been flat for five years. The cause is clear: private label cookies have grown from zero to 20% market share in that time. The question is what to do about it.
The case has two strategic options — supply private labels yourself (Option A) or defend the branded position through innovation and marketing (Option B) — and the data supports both. What makes this case genuinely difficult is that the same piece of competitor data that seems to argue against Option A also reveals the conditions under which Option A can work. Candidates who read the data at surface level miss the synthesis that the case is designed to test.
The other key analytical layer is the value chain. Most candidates focus on the consumer price sensitivity dimension of the private label trend. The more important driver is retailer economics: retailers earn higher net margins on private label products when co-op advertising and promotional costs are factored in. Understanding that retailers are actively pushing private labels — not simply responding to consumer demand — reframes the strategic problem from 'how do we retain consumer loyalty' to 'how do we maintain retailer shelf space allocation.'
### Value Chain Economics: Why Retailers Are Driving This Shift
The instinctive diagnosis of the private label trend is consumer price sensitivity — recessionary conditions are making the $1.00 premium for branded cookies harder to justify. This is true but incomplete. The more powerful driver is retailer economics. Understanding the full value chain — what each participant gains and what they risk — is the foundation of any credible strategic recommendation.
The analytical reframe that most candidates miss — and that changes the strategic recommendation: The client's primary strategic audience is not the end consumer — it is the retailer. Retailers are actively allocating more shelf space to private labels because it improves their economics. A branded defence strategy that focuses entirely on consumer marketing and product quality, without addressing the retailer's economic incentive to shift shelf space, is incomplete. Any credible Option B recommendation must include a retailer-facing component: what does the client offer retailers to maintain premium shelf placement? Exclusive terms, co-branded promotions, or guaranteed sell-through rates are the levers — not consumer advertising alone.
### The Strategic Crossroads: Option A vs. Option B
Neither option is obviously correct. The right choice depends on two judgements that the data does not definitively resolve: whether the private label trend is structural or cyclical, and whether the client has the manufacturing efficiency to compete as a private label supplier without contaminating its brand. The table below maps the six dimensions of the choice.
### The Critical Synthesis: Reading the Competitor Data Correctly
The case provides one piece of data that most candidates either ignore or misread: competitors who entered private label supply saw their own branded sales decline more than the client's. This is the key synthesis challenge in Case 14 — extracting the conditional insight from this data rather than using it as a simple argument against Option A.
The insight that separates a strong candidate from an average one — say it in exactly these terms: 'Private labels thrive on commodity thinking. If our product is just another cookie, we lose on price every time — because a $2.50 alternative that is noticeably but acceptably different will always win on value in a cost-conscious environment. The brand's only sustainable defence is to make the quality difference impossible to ignore, not just claim it in advertising. That means innovation that is genuinely difficult to copy, distributed through channels where the brand has exclusivity, and priced at a level that the retailer has an incentive to maintain on shelf.'
### The 5-Step Framework
The meta-lesson that Case 14 is designed to teach — applicable to every grey-area competitive response case: Grey-area cases are not testing whether you can find the right answer. They are testing whether you can take a position and defend it under ambiguity — while simultaneously demonstrating that you understand the conditions under which the other option would be correct. The ideal answer to Case 14 is not 'Option B is clearly better.' It is: 'I recommend Option B under the assumption that the trend has a cyclical component and brand equity remains intact for the core consumer. If private label market share growth continues above X% for Y consecutive years, the strategy requires reassessment. If we were to pursue Option A, brand contamination prevention would be the non-negotiable condition. Here is why I believe the current data favours Option B.' Commitment plus conditionality plus competitor data synthesis. That is the full answer.


---
# Case 15 - Innovation Strategy
Source: articles/case-strategy/case-15.mdx
#### Case 15: Should We Drop $700M on a Wind Turbine Company?
The math says $750M. The asking price is $700M. On paper it looks like a deal. What the model does not show is everything that can make $750M become $500M — and why the $50M buffer is thin.
Case 15 is an M&A valuation case set in the renewable energy sector — a category that combines quantitative rigour with geopolitical judgement in a way that tests both the financial modelling instincts and the strategic awareness of the candidate. The client is a U.S. energy conglomerate evaluating an acquisition of EnerForce, a publicly traded wind turbine manufacturer with production facilities in China and Vietnam. The asking price is $700M. The question is whether to pay it.
The case contains two traps and one decisive insight. The first trap is the unit conversion: 1 gigawatt equals one million kilowatts, and a candidate who misses this conversion when sizing the addressable market will produce a revenue estimate that is off by a factor of one thousand. The second trap is the market assumption: treating Asia and Western markets as equivalent addressable opportunities when they are, in fact, fundamentally different competitive environments with different share potential for EnerForce's product.
The decisive insight is the market differentiation between Asia and the U.S./Europe. Asia competes on cost per kilowatt-hour generated — a metric where EnerForce, manufacturing in China and Vietnam, cannot compete with domestic producers who benefit from local subsidies and lower structural costs. The U.S. and Europe, by contrast, value turbine aesthetics, supplier reliability, and Western manufacturing credibility — dimensions where EnerForce's 100 KW turbine has a genuine and defensible advantage. This insight determines the market share assumptions, which determine the revenue projection, which determines the valuation.
### Due Diligence: What to Ask Before the Valuation Model
An M&A valuation is only as reliable as the due diligence that validates its inputs. In Case 15, the perpetuity model rests on three numbers: production capacity, profit margin, and discount rate. Each of these has a due diligence question behind it — and answering those questions before building the model is the move that separates a structured M&A analysis from a calculation exercise.
The question that must be asked before any revenue assumption is made: 'What is EnerForce's historical track record of operating at or near full production capacity?' A valuation built on 5,000 units per year is only valid if EnerForce has demonstrated the ability to actually sell and deliver 5,000 units. If the historical utilisation rate is 70–80%, the revenue base and the resulting valuation should reflect that — not the theoretical maximum.
### The Market Insight: Asia vs. Western Markets Are Not Equivalent
The 'aha' moment in Case 15 is recognising that the two available markets for EnerForce's turbine respond to entirely different value propositions — and that the strategic implication is counter-intuitive: despite having manufacturing in Asia, EnerForce's most attractive market is the West. The table below maps the six dimensions that distinguish the two markets.
The counter-intuitive market insight that the case is designed to surface: Having manufacturing in China and Vietnam might suggest that Asia is EnerForce's natural primary market. The correct analysis reverses this assumption: Asia is where EnerForce manufactures, not where it will win market share. The domestic competition in Asia is too intense, and the purchase criteria (cost per output) favour local producers with subsidised cost structures. The Western market — where EnerForce's manufacturing origin is less visible and its product quality and aesthetics are more valued — is where the 40–50% share assumption is defensible. This is the market insight that distinguishes a candidate who reads the data from one who understands the dynamics.
### The Perpetuity Valuation: Building the Model from First Principles
The valuation methodology for Case 15 is a perpetuity model — appropriate for a going-concern business in a growth sector where cash flows are expected to continue indefinitely. The model has three inputs: annual profit, and the discount rate that converts annual profit into a present value. Each input is derived from an assumption that should be named, not assumed.
The perpetuity formula — and why the $50M buffer deserves scrutiny: Valuation = Annual Profit ÷ Discount Rate = $75M ÷ 10% = $750M. The $50M gap between this figure and the $700M asking price looks like a comfortable margin of safety. It is not. A single-point reduction in the margin assumption — from 15% to 10% — reduces annual profit to $50M and the valuation to $500M, which is $200M below asking. A valuation with this level of sensitivity to a margin assumption that has not been stress-tested is a valuation that should not be trusted at face value.
### Sensitivity Analysis: What Breaks the Deal
The base-case perpetuity valuation is $750M. But a valuation is not a fact — it is a model output that is only as reliable as its assumptions. The sensitivity analysis below tests four realistic downside scenarios against the base case and shows how quickly the $50M buffer can disappear.
### The 5-Step Framework
The meta-lesson that Case 15 is designed to teach — applicable to every M&A valuation case: A valuation is a confidence interval, not a number. The $750M figure is the output of a base-case model with optimistic assumptions — 100% capacity utilisation, stable 15% margins, and full Western market pricing sustained in perpetuity. The stress tests show that three of four downside scenarios produce a valuation below the $700M asking price. The recommendation to proceed is not wrong — but it is conditional. The $50M buffer is not a safety net; it is the cost of the residual risk. A candidate who presents the $750M figure as a confident 'yes' without naming the conditions under which it becomes a 'no' has completed the calculation without completing the analysis.



---
# Case 16 - Financial Modeling
Source: articles/case-strategy/case-16.mdx
#### Case 16: The "One More Passenger" Trap — Why Simple Math Still Fails Interviews
The question is trivial. The traps are everywhere. Every wrong assumption compounds — and the interviewer is watching you decide whether to validate them first.
Case 16 is an estimation case with a simple question and a sophisticated scoring rubric. 'What is the financial impact of adding one extra passenger per flight?' The question takes thirty seconds to read and three years of structured thinking to answer well. Most candidates begin calculating within two minutes. Most candidates fail the case within those two minutes — not because their arithmetic is wrong, but because the assumptions they are calculating with have never been validated.
The case is a trap for candidates who have learned that speed signals competence. In a guesstimate or estimation case, the interviewer is not timing how fast you produce a number. They are watching how you decide which questions to ask before you produce any number at all. The candidate who asks for a weighted route mix before requesting a ticket price has already outperformed the candidate who requests 'the average ticket price' and moves immediately to multiplication.
There are four distinct decision points in this case where the structured candidate separates from the fast one: the ticket price approach, the fleet utilisation adjustment, the flight frequency derivation, and the marginal cost insight. Getting all four right — or even three of four — with clear reasoning produces a strong performance regardless of whether the final number is precise.
### Two Candidates, Same Question: Where They Diverge
The table below maps the six key decision points in Case 16 and shows what the fast candidate does versus what the structured candidate does. The difference at each step is not mathematical — it is a choice about whether to validate an assumption before using it.
The single most important question in the entire case — and why it must come first: 'Before I calculate a ticket price, can you tell me what the route mix looks like — specifically the proportion of short, medium, and long-haul flights?' This question does three things simultaneously: it signals that you know a simple average will be wrong; it establishes that you understand the revenue calculation requires a weighted average; and it gives you the data to compute that weighted average correctly. The candidate who asks this question unprompted has already passed the first filter.
#### Step 1: Weighted Ticket Price — Why a Simple Average Is Wrong
The interviewer provides a route mix of 60% short-haul, 20% medium-haul, and 20% long-haul — and ticket prices that differ significantly across these categories. Using a simple average of the three prices produces a number that is materially different from the correctly weighted result. The table below illustrates the calculation with illustrative price assumptions.
Why the simple average error matters more than the arithmetic: A candidate who uses the simple average ($317) instead of the weighted average ($250) has introduced a 27% overestimate into the revenue calculation — before any other assumption has been applied. At scale, this compounds: a $41M estimate becomes a $52M estimate, not because of a calculation error but because of an assumption error. The interviewer is watching whether you catch this. The question 'what's the route mix?' is the catch.
### Steps 2–4: Fleet Utilisation, Flight Frequency, and Total Annual Flights
Once the weighted ticket price is established, the revenue calculation requires two more derived inputs: the number of aircraft available on a given day (adjusted for maintenance downtime) and the number of flights each aircraft completes per day (derived from operating hours and route-length mix). Neither of these numbers should be guessed — both should be derived from stated assumptions.
#### Step 5: The Marginal Cost Insight — The One Sentence That Changes Everything
After calculating the revenue impact, the case requires a cost assessment. Most candidates discuss fuel, crew, catering, and airport fees as costs that would increase with an additional passenger. This is the final trap. The correct insight requires understanding which costs are fixed for the flight (committed the moment the aircraft departs) and which are truly marginal (incurred only because of the additional passenger).
The one sentence that demonstrates consultant-level cost thinking: 'Fuel and crew costs are committed the moment the flight departs — they do not change for one additional passenger. The only meaningful marginal cost is catering, approximately $8–15 per passenger. This means the net incremental contribution of one extra passenger is approximately 95–99% of the ticket price — the additional revenue is almost entirely pure profit.' Say this sentence. It signals that you understand the difference between fixed costs and marginal costs in an operational context.
### What Interviewers Are Actually Scoring
Case 16 is not scored on the accuracy of the final revenue estimate. It is scored on five observable behaviours — each of which demonstrates a different dimension of consulting readiness. The table below translates each scoring criterion into the specific behaviour the interviewer is watching for.
The meta-lesson that Case 16 is designed to teach — and that applies to every estimation case: Consulting interviews are not exam simulations. They are executive conversation simulations. An executive does not want a number — they want a structured assessment of a business question, with clearly stated assumptions, a range of defensible outcomes, and an identification of which variables matter most. A candidate who produces a precise number from unvalidated assumptions has given the executive a false sense of certainty. A candidate who produces a range from explicitly stated assumptions has given the executive something they can actually use — and has demonstrated exactly the analytical posture that makes consulting work trustworthy.

---
# Case 17 - Organizational Design
Source: articles/case-strategy/case-17.mdx
#### Case 17: When Share Price Falls — Think Like the Market, Not the Company
A military aircraft manufacturer's stock is declining. The instinct is to look at operations. The answer is in investor expectations — and there is only one move that changes them.
Case 17 is a share price case — a category that trips up candidates precisely because it sounds like a profitability case and is not. The presenting problem is a falling stock price. The instinctive response is to examine the income statement: find the revenue shortfall or the cost overrun, fix it, and the share price recovers. This logic is wrong, and the case is designed to expose it.
Share price does not reflect current-period profitability. It reflects the market's assessment of expected future profitability, discounted to the present. A company can be profitable today and still have a falling share price — if the market has concluded that future profitability will be lower than previously expected. The correct analytical starting point is not 'what is wrong with operations now' but 'what has the market revised in its forecast of this company's future earnings — and why?'
In Case 17, the answer is structural: the military aircraft market is contracting. Government defence budgets are being reduced. The number of aircraft programmes being funded is declining. With five players competing for a shrinking pool of contracts, the forward revenue outlook for every participant has deteriorated — and the market has repriced all of them accordingly. The share price is not wrong. It is a correct reflection of a worse expected future. The question is what the company can do to improve that expected future, and the answer is not a cost efficiency programme.
### Reframing the Problem: Investor Expectations, Not Operations
The single most important analytical move in Case 17 is the reframe: establishing that a share price case requires thinking from the perspective of the capital market, not the operating manager. The table below makes the distinction explicit across the six dimensions that determine where the analysis should begin.
The sentence that signals correct framing to the interviewer — say it in the first 60 seconds: 'Share price reflects the market's expectation of future profitability. Before examining internal operations, I'd like to understand what has changed about the market's expectation of this company's future earnings — specifically, what is happening at the industry level that might have caused investors to revise their forecast.' This one sentence demonstrates capital market literacy, redirects the analysis to the right starting point, and signals that you will not be trapped by the operational framing the case presents.
### Revenue Diagnostic: Why the Ceiling Is Structural
In a standard profitability case, the revenue diagnostic asks: which product lines are underperforming, which customer segments are churning, and which pricing decisions are compressing margin? In a contracting defence market, these questions have a different character — because the revenue problem is not a mix or execution issue, it is a structural demand decline that no internal action can reverse.
The pivot that the industry context forces — and that most candidates are slow to make: When the interviewer confirms that the military aircraft market is contracting due to government budget reductions, this is not background information — it is the analytical signal to pivot from revenue optimisation to cost management and strategic positioning. Continuing to discuss revenue levers after this signal has been given suggests the candidate has not understood that the revenue ceiling is structural. The strongest response names the pivot explicitly: 'Given that industry demand is structurally contracting, the revenue opportunity is constrained. The analysis should shift to identifying the cost levers that can protect margin under lower volume — and then the strategic options for improving long-term competitive positioning in a consolidating market.'
### Cost Structure Analysis: Beyond Materials and Labour
Cost reduction in a defence aerospace manufacturer is a systems problem, not a line-item problem. The candidates who distinguish themselves in this section are those who move beyond the obvious cost lines — direct materials and direct labour — and identify the structural cost levers that produce durable margin improvement in a declining-volume environment.
### The Strategic Move: Consolidation as the Investor Confidence Lever
Internal cost reduction can improve current-period margin — but it does not change the investor narrative. Investors watching a company in a contracting market implement efficiency programmes are not reassured: they see a company managing its own decline. What changes the narrative is a strategic move that demonstrates the company is positioning to be the survivor in a consolidating market, not just a participant managing the decline. In a five-player market with contracting demand, the correct move is acquisition.
### The 5-Step Framework
The meta-lesson that Case 17 is designed to teach — and that applies to every share price and capital markets case: Stock price cases are not profitability cases. They are investor expectation cases. The correct diagnostic question is not 'where are we losing money?' but 'what has the market revised in its model of our future earnings — and what would cause it to revise upward?' In a contracting industry, the answer to the second question is rarely an operational efficiency programme. It is a strategic move that changes the investor's assessment of whether this company will be a winner or a loser as the market consolidates. Thinking like an investor — rather than like an operating manager — is the analytical posture that this case category rewards.

---
# Case 18 - Fast Food Industry Strategy
Source: articles/case-strategy/case-18-fast-food.mdx
#### Case 18: The Scaling Paradox — Why "Copy-Paste" Is a Strategy Killer
New stores generating higher spend per customer. Profits still collapsing. The data looks like a win. It is not. This case is about what happens when you change the zip code but not the brand.
Case 18 is designed to surface one of the most common and most costly failures in retail and franchise expansion: the assumption that a proven business model scales automatically to a new location. The case presents a fast-food chain that has built a profitable, defensible position in low-income suburban markets — high volume, consistent foot traffic, no meaningful competition — and then expanded into upscale shopping malls, where the stores are barely breaking even.
The immediate diagnostic instinct is to look at operations: labour costs, supply chain efficiency, menu pricing, store layout. These are the wrong places to look. The operations of the new stores are not materially different from the original stores. What is different is the context — and in a context where the brand's defining characteristic (low price) is a social liability rather than a competitive advantage, operational excellence cannot restore the unit economics.
This is a brand-market fit case, not a profitability optimisation case. The distinction matters because it determines the correct analytical framework, the correct diagnostic questions, and the correct recommendation. A candidate who diagnoses it as an operations problem will produce a recommendation that cannot work. A candidate who diagnoses it as a brand positioning failure will produce a recommendation that addresses the root cause.
### The Context Shift: What Changed Between Original and New Stores
The original stores and the new stores sell the same products, operate with the same processes, and carry the same brand. The unit economics are completely different. The gap is entirely explained by the context change — and the eight dimensions below make that gap visible.
The diagnostic principle that this comparison establishes: A business model is not portable. It is a system that works within a specific set of contextual conditions — customer demographics, competitive environment, and brand perception. When those conditions change materially, the model's outputs change with them. The chain's model was not 'high-quality operations' — it was 'high-volume, low-margin, in an underserved market with no competition.' That model does not transfer to a premium mall environment, regardless of how well it is executed.
#### The Data Paradox: Why High Spend Per Customer Is a Warning Sign
The single most important analytical move in Case 18 is reading the spend-per-customer metric in conjunction with the foot traffic metric — not in isolation. The case is designed to present the spend-per-customer data first, as a hook. The candidate who responds positively to that data has accepted the framing. The candidate who immediately asks 'what does foot traffic look like?' has demonstrated the diagnostic instinct the case is testing.
The self-selection insight that converts the data paradox into a root cause diagnosis: The customers who enter the new stores are not representative of the available customer population in the mall. They are a self-selecting minority who are either indifferent to brand perception, are in a hurry and accept the trade-off, or are regular customers who follow the chain regardless of location. Their higher spend reflects the mall's general price environment and their willingness to order more in a sit-down context — not a signal that the brand has found a new premium audience. The foot traffic gap represents the many more who walk past because the brand signals exactly what they are trying to avoid on a leisure shopping day.
### Brand-Market Fit Diagnostic: Five Questions
The brand-market fit diagnostic translates the context shift into five questions that the analysis must answer before a recommendation is possible. Each question is designed to surface a specific dimension of the mismatch between the chain's brand identity and the new location's customer expectations.
### Strategic Pivot Options
The recommendation should not be 'close the stores.' That is the minimum viable response — a retreat without a strategy. The full recommendation addresses the root cause and charts a path that either fixes the brand-market fit failure or redirects growth toward markets where the fit is already proven. The four options below are not mutually exclusive; they operate on different timescales and address different components of the problem.
### The 5-Step Framework
The meta-lesson that Case 18 is designed to teach — and that applies to every market entry and expansion case: The most dangerous words in a growth strategy are 'proven model.' A proven model is proven in a specific context, not universally. The moment the context changes — different demographics, different competitive environment, different customer motivations — the model must be re-validated, not assumed to transfer. The chain in Case 18 did not fail because it expanded. It failed because it expanded without asking whether the thing that made the original model work — a low-price brand in an underserved market with no competition — would still be true in the new location. It was not. Every expansion case in a consulting interview is testing whether the candidate asks that question before recommending growth.

---
# Case 19 - BoxCo Packaging Solutions
Source: articles/case-strategy/case-19-box-co.mdx
### Case 19: The BoxCo Challenge — The Wax Lever
A competitor launches a $500K rebate. You have a 5% margin target you cannot miss. The answer is not in the sales department — it is in the procurement office.
Case 19 presents a commodity market dilemma designed to surface a specific analytical failure: the tendency to accept a false binary when the correct answer is to find the third path. BoxCo is a cardboard manufacturer with 50% market share, a 5% corporate profit margin target, and a $2.5M annual profit. A competitor has launched a $500K rebate programme aimed directly at BoxCo's customer base. The question is how to respond.
The case is framed as a choice between two unattractive options: match the rebate and miss the margin target, or hold the price and lose market share. Most candidates accept this framing and argue for whichever option seems less damaging. That is the wrong move — and it is the move the case is designed to punish.
The correct response is to reject the binary before it constrains the analysis. In a commodity market, the only sustainable path that defends both profit and market share simultaneously is to find the cost reduction that funds the competitive response. The case provides the data to do exactly that — a Type A Wax procurement rate that is $0.10 per pound above the competitor's rate on a consumption base of 6.25 million pounds per year. The solution is $625,000 in annual savings found in the procurement office, funding a $500,000 rebate with $125,000 to spare.
### The False Binary: Why Both Obvious Paths Are Wrong
The first step in Case 19 is to resist the structure of the question. The case presents two options — match the rebate or refuse to match — and most candidates begin by evaluating which is less harmful. The correct structure begins earlier: by questioning whether these are actually the only two options, and identifying what a third path would require.
The move that separates a structured response from a reactive one: State explicitly, in the first 90 seconds, that there is a third path: 'The question is not whether to match the rebate — it is whether there is a cost reduction available that funds the rebate without touching profit. I'd like to examine the COGS structure before recommending.' This one sentence signals to the interviewer that you have not accepted the framing of the problem as the constraint on your analysis.
### COGS Decomposition: Finding the Wax Lever
A full COGS decomposition is the analytical tool that makes the third path visible. By examining each cost line against the constraint — 'which of these can be reduced fast enough and by enough to fund a $500K rebate?' — the analysis narrows from a general cost reduction exercise to a specific procurement opportunity. The Type A Wax line is the answer, but it is only visible if the decomposition is systematic.
Why the wax line is the answer — and how to find it in any COGS analysis: The wax line stands out for two reasons: it is a variable cost (meaning it scales with volume and is renegotiable), and it is above the competitor's known rate (meaning it represents an identifiable, quantifiable overpayment). These two conditions — variable and benchmarkable — are the signals that identify a cost lever in any COGS analysis. Fixed costs and costs at market rate are not levers; they cannot be moved within the required timeframe. The wax line is both variable and above market, which is why it is the answer.
### The Wax Lever: Full Calculation
The wax savings calculation is straightforward once the input data is assembled. The critical step is not the arithmetic — it is identifying that the price differential exists and that the volume is large enough to make the unit saving material at the aggregate level.
### Generalising the Wax Lever: The Procurement Principle
The wax lever in Case 19 is a specific instance of a general analytical principle: when a company faces a competitive cost pressure that it cannot absorb from revenue, the first place to look for funding is variable input costs that are above market rate. This principle applies in any commodity or near-commodity industry where input costs are a significant share of COGS and supplier contracts are not continuously renegotiated.
### The 5-Step Framework
The meta-lesson that Case 19 is designed to teach — and that applies to every cost-structure case: In commodity market cases, the right answer is almost never a choice between the two options presented. It is a third option that requires looking one level deeper into the cost structure than the surface analysis suggests. The wax lever is that third option in Case 19 — but the principle generalises: whenever a case presents a binary that both seem unacceptable, the consulting move is to ask 'what would need to be true for neither of these to be necessary?' and then go find whether that condition can be created. In Case 19, the condition is a cost saving that funds the defensive response. The COGS decomposition is the tool that surfaces it.



---
# Case 2 - Market Analysis Challenge
Source: articles/case-strategy/case-2.mdx
#### Case 2: Can a Mature Chemicals Business Really Grow at 10%+?
$250M revenue. Six businesses all growing at 3–4%. A CEO demanding 10–15% growth. A division head who thinks the core markets are tapped out. The gap between ambition and economics has to be quantified before strategy can be built.
Case 2 is a Deloitte-style growth strategy case with a clear central tension: a CEO has set a 10–15% annual growth target for a Performance Chemicals division that has grown at 3–4% for five consecutive years, in line with the overall market. The division head is skeptical — he believes the core markets are largely tapped out — and has brought in external advisors to either validate his skepticism or identify a credible path to the target.
The analytical discipline this case requires is the opposite of the instinctive response to a growth challenge. The instinct is to generate ideas: new markets, new products, new channels. The correct starting point is to quantify the growth gap and demonstrate why the core business cannot close it. Only after that demonstration is complete does the search for new growth vectors become productive — because the analysis has established what the new vectors must deliver and why.
The case also introduces a dimension that growth strategy cases frequently underweight: organisational feasibility. The business explicitly self-describes as 'we make it by the ton and sell it by the carload' — a manufacturing-oriented, product-centric culture with limited experience in solution-based selling or innovation-led growth. The highest-upside growth path (solutions and services bundling) is also the one that requires the most significant capability transformation. Recommending it without naming the capability gap is not a complete answer.
### Quantifying the Growth Gap: Why the Core Cannot Get There
Before any growth vector is proposed, the size and source of the gap must be established. The table below maps the three dimensions of the growth challenge — historical rate, CEO target, and implied gap — with the strategic implication of each.
The analytical move that earns full marks in growth cases: 'Before I explore new growth vectors, I want to establish that the core business cannot deliver the target organically. All six divisions have grown at 3–4% for five years — this mirrors market growth, which means the division is holding share in a flat competitive position. In a market with limited IP, global competition, and strong customer pricing power, outgrowing the market through product improvement alone is not a credible expectation. The 10–15% target requires structural change, not incremental improvement. I will now structure the growth vectors that could close the gap.'
#### The Growth Spectrum: Five Vectors, Assessed for a 'Made by the Ton' Business
The growth spectrum runs from incremental product enhancement to full business model transformation. Each vector offers a different risk/upside profile — and each must be assessed against the specific capability of a manufacturing-focused chemicals business.
The capability assessment that elevates the answer: 'The solutions and services path offers the highest upside — but it requires a capability transformation in a business that describes itself as product-focused and manufacturing-oriented. Before recommending it as the primary growth vector, I would assess: does the organisation have the technical service capability to deliver solutions? Does it have the customer relationship model built around problem-solving rather than product transactions? Does it have the sales capability to sell outcome-based contracts? If the answers are no, the solutions path is the long-term destination, not the immediate recommendation. The sequencing matters as much as the direction.'
### The 5-Step Framework
The meta-lesson that Case 2 is designed to teach — applicable to every growth strategy case in a mature industry: The most important lesson is not which growth strategy to choose, but how to reason about growth under constraints. When a mature business is asked to grow at 10%+, the right starting point is not creativity — but realism. Quantify what the core can deliver. Acknowledge the competitive dynamics. Assess organisational readiness. Only then can a credible growth strategy be built. Ambitious targets do not change industry economics. But they do force better strategic thinking — and that is the consulting value being tested.

---
# Case 20 - SoapCo Consumer Products
Source: articles/case-strategy/case-20-soap-co.mdx
#### Case 20: SoapCo's $10M Dilemma — Can a Legacy Brand Pivot to Liquid?
A $5M niche leader. A stagnant core market. A mandate to triple revenue in five years. The answer is not 'sell more soap.' It is 'change which soap you sell, and where.'
Growth strategy cases follow a predictable failure pattern: the candidate recognises that growth is needed, proposes to grow harder in the current market, and produces a recommendation that falls short of the target because the market is simply too small to support the goal. Case 20 is engineered to surface that failure pattern and test whether the candidate can move past it.
SoapCo is a market leader in U.S. Decorative Bar soaps — a real achievement in a niche product category. The problem is that niche leadership in a stagnant market generates $2M in annual revenue on a 10% share of a $20M total market. The 5-year target of $15M requires adding $10M. Growing Decorative Bar market share from 10% to the theoretical maximum of 50% would yield $8M in revenue — still short, and achievable only by eliminating every competitor in the category, which is not a strategy.
The correct analytical move is one that many candidates delay too long: disqualify the current market as a vehicle for the growth goal, then identify adjacent markets large enough that a small market share generates the required incremental revenue. The Decorative Bar market cannot close the $10M gap. The Body Bar market ($250M), Liquid Hand Soap ($100M+), and Liquid Body Wash ($100M+) each can — and the question then shifts from whether to enter to how to enter, in what sequence, and with which capabilities.
### Market Sizing: Why the Current Sandbox Is Too Small
The first analytical task is not to propose a growth strategy — it is to prove that the current market cannot deliver the growth target. This step is the one most candidates skip, and skipping it means the adjacent market recommendation arrives without the quantitative justification that makes it compelling. The market sizing below establishes both the ceiling of the current market and the floor of the adjacent ones.
The core insight that separates this case from a standard market entry question: Operational excellence cannot fix a market size problem. SoapCo could achieve best-in-class manufacturing efficiency, perfect customer service, and flawless brand execution in the Decorative Bar segment — and still be structurally unable to reach $15M in revenue, because the entire market is worth $20M. A 100% market share of $20M is $20M. The goal requires $15M from a starting base of $2M. The math closes only through adjacent market entry, not through performance improvement in the existing market.
### The Revenue Bridge: Quantifying the Growth Path
The revenue bridge translates the market sizing into specific revenue targets for each entry scenario. This is the quantitative backbone of the growth strategy recommendation — and the step that converts 'SoapCo should enter adjacent markets' from a directional argument into a financially substantiated recommendation.
The key number that reframes the entire analysis — and that most candidates miss: A 5% share of the Body Bar market ($12.5M) exceeds the entire Decorative Bar market ($20M × 100% = $20M). This means that capturing one-twentieth of a larger adjacent market is more valuable than owning the entire current one. When a single adjacent market share scenario dominates the total value of the current market, the case for entry is structurally self-evident — and the analytical energy should shift from 'whether to enter' to 'how to enter responsibly.'
### Capability Assessment: What SoapCo Can and Cannot Do
Identifying attractive adjacent segments is necessary but not sufficient for a growth strategy recommendation. The recommendation must be feasible — and feasibility is determined by SoapCo's existing capabilities, production infrastructure, and brand positioning. The capability assessment below distinguishes between segments that are both attractive and accessible, segments that require investment, and segments that are currently inaccessible for structural reasons.
### Channel Strategy: Where the Volume Lives
Entering the Body Bar and Liquid Soap segments requires distribution access to the channels where those products generate volume at the price points that support SoapCo's margin requirements. SoapCo's current specialty retail channel is appropriate for Decorative Bars — it is not the channel where $250M in Body Bar revenue is generated. The channel strategy is part of the growth recommendation, not a post-entry operational detail.
### The 5-Step Framework
The principle that Case 20 is designed to teach — and that applies to every growth strategy case: Growth strategy cases test whether a candidate can recognise the difference between a performance problem and a market size problem. Performance problems are solved by doing the current thing better. Market size problems are solved by changing which market you compete in. SoapCo does not have a performance problem — it is the market leader in its segment. It has a market size problem. Every growth case that presents a stagnating core market is testing this distinction. Candidates who miss it recommend performance improvements that cannot close the gap. Candidates who catch it recommend market entry strategies that can.



---
# Case 21 - Brain Teasers for Consulting
Source: articles/case-strategy/case-21-brain-teasers.mdx
#### Case 21: The "Impossible" Interview — Mastering Brain Teasers and Guesstimates
Four problems that top-tier consulting and tech interviewers use to test structured thinking under pressure. The final answer is almost never the point.
Brain teasers and Fermi estimation problems have a reputation for being arbitrary — questions designed to make candidates uncomfortable rather than to surface genuine skill. That reputation is mostly wrong. The firms that still use these questions are not looking for candidates who happen to know that a ping-pong ball has a 4cm diameter or who have memorised the number of JFK runways. They are looking for candidates who, when confronted with a question they cannot immediately answer, do something specific: decompose it, state their assumptions, build a structured path to an estimate, and check whether the answer makes sense.
Case 21 covers four problems that span the two main types of brain teaser used in consulting and technology interviews. The first two — the Calendar Cube and the Chopped Cube — are logic and spatial reasoning problems with definitive correct answers that require a specific insight to unlock. The second two — the 747 Ping-Pong Ball problem and the JFK passenger volume problem — are Fermi estimation problems with no single correct answer but with clear standards for what constitutes a well-constructed estimate. Both types are testing the same underlying capability: structured thinking under ambiguity.
This post works through all four problems in full — including the common traps, the correct solution paths, and the specific signals each problem sends to an interviewer about how a candidate thinks.
### The Four Problems: Full Solution Paths
Each problem below is presented with its structure, the trap that catches most candidates, the correct solution path, and the specific signal the interviewer reads from the approach.
The meta-principle across all four problems: In every case, the wrong approach is to attempt a direct calculation of the final answer. The right approach is to identify the structure of the problem — what type of question is this, what are the constraints, what sub-questions need to be answered first — before doing any arithmetic. The candidate who states their approach before executing it gives the interviewer a window into their thinking. The candidate who silently calculates and presents a number gives the interviewer nothing to evaluate.
### What Interviewers Are Actually Scoring
Brain teasers and Fermi problems are not scored by whether the candidate produces the right number. They are scored by whether the candidate demonstrates five specific capabilities, each of which maps directly to a skill required in consulting and analytical roles.
The single most common failure mode — and how to avoid it: The most common failure in brain teaser interviews is silence. Candidates who do not immediately see the answer go quiet while they think — and interviewers score that silence as an inability to think out loud. The correct response to uncertainty is narration: 'I do not immediately see the solution, so let me start by identifying the constraints I am working within.' That sentence is a better answer than 90 seconds of silence followed by a correct number. The interviewer is watching your process. Make it visible.
### The Fermi Method: A 5-Step Protocol
Fermi estimation problems — JFK passengers, 747 ping-pong balls, windows in Manhattan — all respond to the same five-step protocol. This protocol produces a well-structured, defensible estimate regardless of prior knowledge of the specific domain.
Why brain teasers matter even if your target firm does not use them: Practising structured estimation problems builds a specific cognitive habit: the ability to start from nothing and construct a reasonable answer through a series of auditable steps. That habit — not the ability to solve any specific riddle — is what transfers to consulting work. Every market sizing question, every financial model built without historical data, every strategic recommendation made under time pressure draws on the same capability. The brain teaser is a compressed, explicit test of a skill you will use every week of a consulting career. Treat it as practice for the job, not as a hurdle to the job.

---
# Case 22 - Beantown Insurance
Source: articles/case-strategy/case-22-beantown-insurance.mdx
#### Case 22: The Climate Crisis on the Balance Sheet — Beantown Co.'s Profitability Play
A property insurer losing margin to Southeast climate losses in a market where they cannot raise prices. The instinct is cost-cutting. The data says geographic hedging through M&A.
Case 22 is a profitability case with an unusual constraint: the client cannot use the lever that most candidates reach for first. Beantown Co. is a U.S. property insurer with a 2% operating margin in a market where the best-positioned competitor posts 4%. The gap is two percentage points. The cause is not inefficiency, excessive overhead, or product mix — it is geographic concentration in a region where climate-related losses are accelerating faster than any organic cost reduction can offset.
The constraint that changes the entire analytical structure: Beantown is a price taker. In a fragmented property insurance market with many competing providers, Beantown cannot unilaterally raise premiums without losing policyholders to cheaper competitors. The mechanism that turns a cost problem into a pricing problem — and then uses pricing to restore margins — does not exist in this market structure. Every candidate who opens with 'they should raise premiums' has failed the first filter.
The correct path to margin recovery requires rebalancing the company's risk geography, not managing its existing geography more efficiently. This case is about understanding when the correct answer to a profitability problem is not 'reduce costs' or 'increase revenue' but 'change the underlying risk profile of the business' — and executing that change through the only lever fast enough to be relevant: M&A.
### The Price-Taker Constraint: Why the Obvious Lever Doesn't Exist
The first structural insight in this case is market structure. Understanding why Beantown cannot raise premiums — and why that constraint eliminates the most intuitive profitability lever — is the analytical prerequisite that determines which solutions are worth evaluating. Candidates who skip this step and proceed directly to revenue improvement recommendations have not understood the case.
The question that unlocks the correct analytical direction: 'What does it mean that Beantown is a price taker, and what does that eliminate from the solution space?' Answering this question in the first 90 seconds demonstrates that you understand the market structure before proposing interventions. It eliminates premium increases, narrows the revenue lever to product mix and geographic expansion, and focuses the cost analysis on whether efficiency gains are large enough to close a 2-point margin gap driven by climate-related claims — which they are not.
### The Three-Lever Framework: Why M&A Dominates
With premium increases eliminated by market structure, Beantown's profitability improvement options reduce to five distinct levers across the revenue, cost, and inorganic growth dimensions. The table below evaluates each lever on impact potential, mechanism, and strategic assessment — including the speed-of-impact constraint that determines which lever is relevant to the current crisis.
The key insight that separates a strong answer from a surface one: M&A is not the recommendation because it is the most dramatic option. It is the recommendation because it is the only option that solves both components of the problem simultaneously — margin improvement and geographic diversification — in a timeframe relevant to a company whose losses are compounding annually. Organic geographic expansion is the right direction but the wrong speed. Digital efficiency is the right discipline but the wrong magnitude. The acquisition is not a growth strategy; it is a risk management strategy executed through a financial instrument.
### The Acquisition Target: Why Chicaaago Is the Goldilocks Answer
The fragmented property insurance market contains many potential targets — but most are either too large (triggering antitrust review) or too small (insufficient margin and geographic diversification to move the needle). Chicaaago Insurance Co. is the Goldilocks target: large enough to provide meaningful margin improvement and geographic hedging, small enough to be acquirable without regulatory obstruction.
The benchmarking logic is important to present explicitly: Beantown's 2% margin against Chicaaago's 4% defines the 'size of the prize.' A weighted average blended margin — accounting for the relative premium volume of the two companies — produces the expected post-acquisition operating margin, which becomes the financial justification for the deal price. This calculation is what converts the M&A recommendation from a qualitative argument to a quantitative one that the client's CFO can evaluate.
### M&A Risk Assessment
Recommending an acquisition without a risk assessment is structurally incomplete in a case interview and strategically incomplete in practice. The five risks below are not arguments against the acquisition — they are conditions that must be managed for the acquisition to deliver its expected margin improvement.
The climate risk caveat that demonstrates long-term strategic thinking: The acquisition of Chicaaago is not a permanent solution to Beantown's climate exposure problem — it is a margin and diversification bridge. The Southeast climate trajectory is structural: hurricane frequency, flood zone expansion, and sea level rise will continue to increase Beantown's property loss ratios regardless of who they acquire. The acquisition buys 5–10 years of margin headroom and diversification buffer. The permanent solution requires actuarial repricing as state insurance regulators permit, selective non-renewal of the highest-risk Southeast exposure, and ongoing geographic rebalancing as the climate risk map continues to shift. A candidate who names this long-term dynamic — rather than treating the acquisition as a complete answer — is demonstrating the strategic perspective that senior consulting cases are designed to surface.
### The 5-Step Framework
The principle that Case 22 is designed to teach — and that applies to every profitability case: Profitability cases almost always have an obvious first lever that the interviewer expects you to eliminate before moving to the correct one. In Case 22, the obvious lever is premium increases — and it does not exist in a price-taker market. In Case 28 (Orrington), the obvious lever was revenue growth — but the problem was fixed-cost structure. In every case, the consulting value is in the structural diagnosis that determines which levers exist before evaluating how hard to pull each one. Always diagnose market structure, root cause, and lever availability before proposing a solution.


---
# Case 23 - Streaming vs Cinema Industry
Source: articles/case-strategy/case-23-streaming-vs-cinema.mdx
#### Case 23: Streaming vs. Cinema — Risk Mitigation or Brand Equity?
A streaming platform offers $150M guaranteed. The theatrical upside is $5M more — on a good day. Most candidates choose theaters. Most candidates are answering the wrong question.
Case 23 is presented as a financial comparison: streaming deal versus theatrical release. Calculate the profit for each path, pick the higher number, present the recommendation. Candidates who approach it that way are solving the surface problem — and missing the case entirely.
The real question is not which path generates more profit on the best-case spreadsheet. It is which path produces a better risk-adjusted outcome given the studio's financial position, stakeholder ecosystem, and franchise value trajectory. The $5M theatrical upside over streaming is not the interesting number. The $120M range between the theatrical upside and the theatrical downside is the interesting number — and it is the number that determines the recommendation.
This is also a franchise strategy case disguised as a profitability case. The decision the studio makes for this film is not contained to this film. It sets the distribution precedent for the sequel, signals the studio's commitment to the theatrical window to talent and exhibition chains, and either preserves or permanently reclassifies the franchise's cultural status. Those downstream consequences are where the consulting value in this case lives.
### The P&L Comparison: Why $5M Is a Trap
The financial comparison between the two paths produces a result that appears to favour theatrical release by a narrow margin. Most candidates stop at the base case and recommend theaters for the extra $5M. The interviewer is waiting for the candidate who calculates the downside — and finds that the extra $5M is purchased with a $120M range of outcome risk.
The downside calculation that most candidates omit — and that changes the recommendation: If theatrical revenue comes in at $100M in a weak post-pandemic recovery: $100M revenue − $20M distribution fee − $50M production − $25M marketing = $5M net profit, not a loss. But at $80M theatrical: $80M − $16M dist − $50M prod − $25M mktg = −$11M. The streaming deal's $100M floor means the studio must believe theatrical revenue will exceed approximately $105M just to break even on the comparison — and must exceed $225M to justify the brand equity and relationship risks of a theatrical-first bet. That is the framing the interviewer wants to hear.
### Beyond the Spreadsheet: The Brand Equity Stakes
The financial comparison is necessary but not sufficient. A case that stops at the P&L has answered the math question without addressing the strategy question. The five brand equity risks below each have measurable long-term value implications that are absent from the current-film P&L — and each one applies specifically to franchise properties like Leo, where the decision made on Film 5 sets the conditions for Films 6 through 10.
The franchise valuation principle that converts the brand equity argument from qualitative to quantitative: A major franchise's theatrical window is not a distribution preference — it is a valuation multiplier for the entire intellectual property ecosystem. Box office performance is the benchmark input for merchandise licensing negotiations, theme park partnership valuations, and sequel greenlight decisions. A franchise that moves to streaming loses its box office benchmark and negotiates the entire downstream ecosystem at a discount. The current film's P&L shows a $5M theatrical upside. The franchise's 10-year P&L may show a $200M–$500M differential between 'blockbuster event' and 'streaming content' positioning. Naming that asymmetry is what separates a senior answer from a junior one.
### The Decision Matrix: Conditional on Studio Objective
There is no single correct recommendation in Case 23 — there is a correct framework for arriving at the recommendation that fits the studio's actual situation. The matrix below presents three paths conditional on the studio's primary objective. The hybrid option is the one most candidates miss, and the one most interviewers are hoping to hear.
The hybrid path — theatrical release with a negotiated distribution fee reduction and a streaming fallback trigger — is the structural answer that demonstrates both financial fluency and creative problem-solving. It reframes the decision from a binary choice to a structured option: the studio retains the theatrical upside and the brand equity benefits while capping the scenario where a weak opening weekend converts a near-miss into a loss. This kind of conditional structure is the output consulting interviewers associate with senior analytical thinking.
### The 5-Step Framework
The meta-lesson that Case 23 teaches about certainty vs. prestige trade-offs: The 'certainty trap' is one of the most reliable patterns in case interviews involving guaranteed offers against uncertain upside. The instinct is to take the guaranteed money. The consulting analysis asks: what does the certain option cost in the currency of the uncertain option's upside — and is the certainty premium worth that cost? In Case 23, the certainty premium is $100M guaranteed vs. a range of −$20M to $200M+. Whether that premium is worth paying depends entirely on the studio's financial position and strategic time horizon. A candidate who names both conditions — and explains which recommendation follows from each — has produced the answer the case is designed to extract.



---
# Case 24 - Teacher Retention Challenge
Source: articles/case-strategy/case-24-teacher-retention.mdx
#### Case 24: Solving the Talent Drain — Strategic Retention in Education
A 10% attrition rate across 71,000 teachers. The instinct is to raise salaries. The data says otherwise — and the gap between those two responses is what the case is testing.
Case 24 is presented as a human resources problem. It is not. It is a human capital optimisation problem — and the distinction matters more than it might appear. An HR problem asks: what policy change reduces the attrition number? A human capital optimisation problem asks: which segment of the workforce is failing, at which lifecycle stage, for which underlying reason, and what intervention produces the best return on that specific failure?
The instinctive answer — raise teacher salaries — is not wrong. But it is incomplete, and in a case interview context, incomplete is functionally incorrect. A uniform salary increase applied across 71,000 teachers addresses the compensation gap for the STEM segment competing with private sector offers. It does nothing for the beginning teacher in a rural district who is leaving because she has spoken to no colleague outside her own classroom for three weeks. These are different problems requiring different solutions.
The case reveals two attrition spikes hidden within the aggregate 10% rate: a beginning-teacher burnout spike driven by professional isolation, and a veteran benefits cliff concentrated at the 27–30 year tenure mark. Identifying both, explaining the distinct mechanisms behind each, and recommending targeted interventions for each is the structure that constitutes a strong answer. This post breaks down each component.
### Reframing the Problem: From HR to Human Capital
The first 60 seconds of a case interview response establish whether the candidate has understood the actual problem. Candidates who begin with 'we need to improve teacher satisfaction' have accepted the HR framing. Candidates who begin with 'this is a lifecycle failure — we need to identify which stage of the teacher lifecycle is producing the highest attrition and why' have made the reframe that the interviewer is scoring for.
The reframe that changes the entire analytical direction: Retention is not about stopping people from leaving. It is about making them want to stay — and the conditions that make a beginning rural STEM teacher want to stay are different from the conditions that make a 28-year veteran want to stay. A single retention strategy that addresses both with the same intervention is not strategic; it is averaged. The case is testing whether you can resist the averaging impulse and design for the actual distribution of the problem.
### Segmentation: The MECE Decomposition of 71,000 Teachers
The workforce of 71,000 teachers across 115 districts is not a monolith. Treating it as one produces the kind of averaged, uniform recommendation that consulting interviewers are trained to reject. The MECE segmentation below identifies five distinct cohorts with meaningfully different attrition profiles, root causes, and strategic implications.
The segmentation insight that most candidates miss — and that changes the recommendation: By the time a teacher reaches Year 27, the retention battle has already been won. They have invested 27 years in the profession; the benefits cliff is the only structural incentive that could pull them out before Year 30. The real battle — the one that determines whether the 10% attrition rate improves or stays — is fought and won or lost in the first 36 months. Every teacher who makes it through Year 3 has a dramatically lower lifetime attrition probability. This means the highest-ROI intervention target is not the largest group or the most vocal group: it is the newest cohort, in the most isolated districts, in the first three years.
### Departure Reasons: What the Data Actually Says
The departure reason data is the most commonly misread component of this case. The 61% 'personal reasons' category looks like a terminal answer — the kind of soft, non-actionable data that produces a recommendation to 'improve work-life balance.' It is not. It is a segmentation prompt: personal reasons among whom, in which context, at which career stage?
The 14% 'other / unknown' category is the most analytically valuable one if the state commits to improving its data collection. An anonymous exit survey — short, voluntary, launched at the point of departure notice — converts this unclassified 14% into actionable intelligence over time. The cost is negligible; the policy value is substantial. A candidate who recommends this data collection step in addition to the intervention programme is demonstrating the rigour that senior case interviews are designed to find.
### The Strategy: Technology-Enabled Mentor Network and Benefit Redesign
The retention strategy has two distinct components — one for the beginning-teacher attrition spike and one for the veteran benefits cliff — and they should be presented as such. Conflating them into a single 'retention programme' is a structural error. The four programme components below address the two spikes through different mechanisms, with a pilot design that enables evidence-based statewide rollout.
### The 5-Step Framework
The principle that Case 24 is designed to teach — and that applies to every public sector case: In public sector cases, the instinctive policy lever — raise pay, add resources, issue a mandate — is almost always correct in direction but insufficient in precision. The consulting value is in the targeting: which segment, at which lifecycle stage, with which intervention, measured by which metric. A superintendent who increases the entire teacher payroll by 5% has spent money. A superintendent who deploys a targeted peer network in the 20 highest-attrition rural districts, measures Year-3 retention in the pilot cohort, and expands only the interventions that produce measurable improvement has built a system. Case 24 is about the difference between those two answers.



---
# Case 25 - Agribusiness Strategy
Source: articles/case-strategy/case-25-agribusiness.mdx
#### Case 25: The $20,000 Harvest — Yield vs. Reality in Agribusiness
A retired professor. Ten acres in Durham, NC. A two-year deadline. The numbers almost work — which is exactly what makes this case dangerous.
This case is designed to look like an optimisation problem. Assign the right crops to the right acreage, maximise yield per acre, hit $20,000. Most candidates approach it exactly that way — and most candidates get it wrong, not because their arithmetic is off, but because they are solving the wrong problem.
The real question in Case 25 is not 'what is the optimal crop mix?' It is 'does this investment meet its hurdle rate, and what is the risk-adjusted return?' The $20,000 target is not a revenue target — it is the minimum acceptable profit required to justify the investment. The moment you reframe it as an ROI problem rather than an optimisation problem, the entire analytical structure changes.
The case is further complicated by two embedded traps. The first is the saffron trap: high yield per acre but a regional market that may not absorb five acres of supply at the assumed price point. The second is the cost omission trap: the surface-level gap between crop revenue and target profit is $3,500, but full cost accounting including start-up and maintenance expenses produces a true gap of $7,100 — more than double. Candidates who reach a 'Do Not Invest' recommendation without catching the cost omission have reached the right answer via incomplete analysis.
### The Crop Mix: Revenue Potential and Market Constraints
The four crops available — saffron, beets, rose bushes, and pine trees — vary dramatically in yield per acre, market demand, and time horizon. The optimal crop mix for a 2-year profit window allocates aggressively toward the highest-yield viable crops while respecting the market absorption constraint that limits saffron allocation. Pine trees are excluded from any serious 2-year analysis: their harvest cycle of 8–15 years makes them structurally irrelevant to the stated objective.
The saffron trap — and the market absorption question interviewers are waiting for: Saffron yields $1,200 per acre in a controlled analysis — the highest per-acre return in the mix. The instinctive response is to maximise saffron acreage. The senior response asks: 'What is the local market's absorption capacity for saffron at this price point?' Durham, NC is not a specialty spice trading hub. A single producer introducing 5 acres of saffron into a regional market may depress the local price below $1,200/acre before the first harvest is complete. The analysis assumes full price realisation — an assumption that must be challenged, not accepted.
### Full Cost Accounting: The Gap Is Larger Than It Appears
The $3,500 shortfall between optimal crop revenue ($16,500) and the profit target ($20,000) is the number most candidates cite in their recommendation. It is not the right number. The correct gap analysis deducts start-up costs and two years of maintenance from gross revenue to produce net profit — and the result changes the recommendation materially.
The cost omission is the most common error in this case, and it is the error that separates a candidate who can follow a framework from a candidate who can apply financial rigour. Consulting interviewers use this case to identify candidates who check their own assumptions — who ask 'have I included all costs?' before presenting a recommendation — rather than candidates who stop at the first plausible number.
The land value alternative that most candidates never mention — and that changes the entire recommendation: Durham's technology sector expansion has been materially increasing residential and commercial land values in the surrounding area. A candidate who raises the question — 'What is the current market value of 10 acres in Durham, and what is the expected appreciation over two years?' — has identified an investment alternative that may dominate the farming plan with zero risk. If the land appreciates by $2,000–$4,000 per acre over two years with no capital outlay or execution risk, selling the land generates $20,000–$40,000 with certainty. The farming plan is competing not just against a hurdle rate, but against a risk-free alternative.
### Risk Analysis: The Variables That Make the Gap Insurmountable
Even if the optimal crop mix is implemented perfectly and costs remain at their estimated levels, the recommendation is Do Not Invest. With five identified risk factors that could each independently cause the investment to miss the hurdle rate, there is no reasonable confidence interval under which the expected return justifies the investment. The risk table below documents each factor and its business implication.
### The Strategic Pivot: If the Client Will Not Accept 'No'
In a live case interview, 'Do Not Invest' is the correct primary recommendation — but the interviewer will frequently follow with: 'The client is committed to using this land. What would you recommend?' This is the test of whether a candidate can shift from evaluation mode to creative problem-solving mode without abandoning financial rigour. The answer is not to force the original farming plan to work — it is to redesign the revenue model around the asset's real competitive advantages.
Why agri-tourism is the highest-confidence recommendation — not a fallback: Agri-tourism is not a consolation prize for a failed farming plan. It is a fundamentally different business model applied to the same asset. The farm's location near a growing technology hub creates genuine demand from knowledge-economy workers for authentic rural experiences — a market that did not exist ten years ago in Durham. Farm tours require near-zero capital investment beyond basic safety infrastructure, are not subject to weather or pest risk, and generate revenue in Year 1 rather than waiting for harvest cycles. Combined with a reduced crop programme, the agri-tourism model can close the $7,100 gap with lower risk than the full 10-acre farming commitment.
### The 5-Step Framework
The meta-lesson that Case 25 is designed to teach: Strategy is as much about knowing when to say 'No' as it is about finding the 'Yes.' The best consultants are not optimists who find a way to make every plan work — they are analysts who can distinguish between a plan that is viable under realistic assumptions and one that only appears viable under optimistic ones. Case 25 is solvable on paper. It is not investable in practice. The candidate who explains that distinction clearly, with the numbers to support it, and then proposes a genuinely better alternative, is the candidate who passes.



---
# Case 26 - Energy Transition Strategy
Source: articles/case-strategy/case-26-energy-transition.mdx
### The Energy Transition: Balancing Court Mandates with Market Returns
A European oil major faces a 45% emissions cut by 2030 and a stock price down 35%. The answer is not green vs. oil — it is resiliency through transformation.
Expert-level strategy cases are designed to expose a specific cognitive failure: the tendency to treat two simultaneous constraints as inherently in conflict when a deeper analysis reveals they converge. Case 26 is built on exactly this structure. Sovereign Oil Co. faces a court-mandated 45% carbon reduction and a stock price down 35%. Most candidates spend the case trying to balance these two forces. The insight that earns the offer is recognising that they do not need to be balanced — they need to be synthesised.
The synthesis: the same capital reallocation that satisfies the court mandate — divesting high-carbon assets and deploying proceeds into solar PV with battery storage — also generates the ROIC improvement and ESG-aligned revenue growth that restores institutional investor confidence and recovers the share price. The legal constraint and the shareholder constraint converge at the renewable investment thesis.
This is Case 26 in HéraAI's Case Strategy Chamber series. It requires command of capital markets logic, energy sector economics, ESG regulatory frameworks, and workforce transition strategy simultaneously. Here is how to structure it.
### The Dual Constraint: Why This Case Is Expert-Level
The reason Case 26 is classified as expert-level is not the technical complexity of the renewable energy analysis. It is the requirement to hold two simultaneous constraints — a legal mandate and a shareholder value obligation — without sacrificing one for the other. Most candidates default to one of two failure modes: they optimise for compliance at the cost of shareholder return, or they optimise for shareholder return while treating the mandate as a cost centre. Neither produces a defensible recommendation.
The table below maps both constraints across six dimensions, with a final row that identifies where they converge. That convergence is the strategic premise of the entire recommendation.
The synthesis that defines the expert answer: Renewable ROIC now frequently exceeds new O&G project returns — particularly for solar PV with battery storage in markets with strong B2B demand. This means the asset that satisfies the court mandate is also the highest-return capital allocation available to SOC. The legal constraint and the shareholder constraint are not in tension. They are pointing at the same investment.
### The Technology Selection: Why Solar PV + Battery Storage
The court mandate requires actual emissions reduction, not offset accounting. That means SOC must build or acquire generating capacity that displaces fossil fuel production in its revenue mix. The technology selection must be defended on three dimensions that matter in a capital allocation context: ROIC relative to O&G alternatives, breakeven timeline relative to the 2030 mandate deadline, and commercial alignment with the demand profile of SOC's target B2B customers.
The carbon offset option deserves explicit rejection rather than omission. Purchased carbon offsets do not reduce SOC's actual emissions — they compensate for them on paper. European courts and regulators are increasingly treating offset-reliant strategies as non-compliant with the spirit of emissions reduction mandates. More critically, institutional investors with genuine ESG mandates are applying a discount to companies whose sustainability claims rest on offset purchases rather than operational decarbonisation. Recommending offsets as a primary strategy in this case signals a failure to understand the regulatory and market direction.
The B2B premium argument — the commercial case for the technology choice: Solar PV with battery storage enables 24/7 firm power delivery — always-on, dispatchable clean energy that intermittent wind or solar-only systems cannot provide. Hyperscale data centres, which have committed to 100% carbon-free energy on an hourly matching basis, require firm power not spot-market renewable certificates. SOC's ability to offer guaranteed clean supply, backed by battery storage, enables it to charge a premium above spot market rates through long-term power purchase agreements. The reliability of the technology is not just an engineering characteristic — it is the commercial justification for the price premium.
### The Three-Phase Resiliency Framework
The recommendation is not a single investment decision — it is a sequenced transformation programme. The sequence matters because each phase creates the financial and operational conditions that make the next phase viable. A strategy that begins with renewable investment before completing the divestment has an underfunded capital base. A strategy that completes the divestment without beginning the capability build has a compliance gap in the final years before the 2030 deadline.
The build-buy-partner trifecta and why it is faster than organic development: SOC's primary capability gap in the transition is not capital — it is operational expertise and permitted project pipeline. Building organically from scratch requires years of permitting, grid connection queue navigation, and operational learning. Acquiring established renewable developers brings permitted capacity, grid connections, operational teams, and project management experience immediately. Partnering with joint venture developers allows SOC to gain operational knowledge before committing full capital. The three-mode approach compresses the transition timeline by 2–3 years compared to organic development alone — which matters when the compliance deadline is fixed at 2030.
### The B2B Commercial Strategy: Securing the Revenue Premium
SOC's transition from fossil fuel revenue to renewable revenue requires more than building the right technology — it requires building the right customer relationships. The revenue premium that makes solar PV with battery storage financially compelling relative to spot-market renewable generation depends on securing long-term power purchase agreements with corporate buyers who have their own ESG commitments and need verified clean energy supply.
The B2B strategy is not a marketing decision — it is a project finance decision. Long-term PPAs with investment-grade counterparties (Amazon, Microsoft, major logistics operators) provide the revenue certainty that enables SOC to finance renewable projects at lower cost of capital. A project backed by a 10-year PPA with a creditworthy counterparty carries significantly lower financing risk than a project selling into the spot market, which directly improves the project's ROIC and the company's overall financial profile.
### The Transition Risks the Board Must Address
A transformation of this scale and speed carries execution risks that can derail a financially sound strategy. The expert-level candidate addresses these proactively rather than waiting to be prompted.
The workforce dislocation risk is the one most candidates mention but few develop fully. The insight that distinguishes expert-level thinking is recognising that O&G workers are not simply a cost to be managed in the transition — they are a competitive asset to be retrained and redeployed. Large-scale renewable infrastructure projects require exactly the project management expertise, safety culture, and remote operations capabilities that O&G workforces possess. A retrained O&G workforce gives SOC a talent advantage over pure-play renewable developers who are competing in the same labour market.
### The Five-Step Interview Framework
The principle that defines the expert answer in this case: In expert-level strategy cases, the answer is never 'Green vs. Oil.' It is resiliency through transformation. SOC's 35% stock price decline is not caused by the court mandate — it is caused by investors repricing a fossil-fuel-heavy portfolio in a world where the regulatory, carbon tax, and customer demand environment is structurally shifting against it. The transition is not the threat to shareholder value. The failure to transition is. A candidate who sees that clearly, and builds a recommendation around the convergence of the compliance obligation and the investment thesis, has answered the case at the level that consulting interviews are designed to find.


---
# Case 27 - Surgery Pricing Strategy
Source: articles/case-strategy/case-27-pricing-surgery.mdx
### The Pricing Surgery: Unlocking Alpha in Mature Wholesale Markets
A global food wholesaler. Flat GDP-rate growth. A North American duopoly and a fragmented Asia. The answer isn't a price change — it's a portfolio of elasticities.
In a mature industry growing at the rate of GDP, most executives exhaust two options before calling a consultant: cut costs and market harder. Both are table stakes. Neither addresses the actual source of hidden profitability in a mature business — the pricing architecture applied to an unevenly elastic product catalog.
Case 27 puts you in the seat of a consultant advising a global food wholesaler serving hotels and restaurants across North America and Asia. Revenue growth is flat, tied to macroeconomic conditions. The client has been applying regional average pricing across its full product range. The insight that unlocks the case — and the one most candidates miss — is that a single pricing strategy applied across thousands of SKUs in two structurally different market environments is not a pricing strategy. It is pricing negligence.
The solution is micro-elasticity mapping: plotting every SKU on a demand elasticity versus gross margin matrix and applying a different pricing lever to each quadrant. The result is a portfolio of pricing moves that simultaneously expands margin on sticky products and captures market share on elastic ones — without requiring a single unit of new revenue from new customers.
### The Competitive Physics: Why One Strategy Cannot Serve Two Markets
Before any SKU is plotted or any price is changed, the case requires establishing that North America and Asia are not the same type of market. This is not a geographic observation — it is a structural one. The competitive physics of a duopoly and a fragmented market are fundamentally different, and any pricing move that ignores that difference will either underperform or actively damage the client's position.
The market structure insight the interviewer is waiting for: In a duopoly, you have one competitor to model and one set of responses to anticipate. Price cuts can be surgical and targeted. In a fragmented market, you have dozens of competitors with different cost structures and different levels of price discipline. A list price cut in Asia is not a competitive move — it is an invitation to a race to the bottom where only the lowest-cost operator wins. Naming this distinction before the interviewer prompts it demonstrates market-level strategic thinking.
### The Elasticity-Margin Matrix: A Portfolio of Pricing Levers
The analytical core of this case is a two-axis matrix. The horizontal axis plots demand elasticity — how sensitively volume responds to a price change. The vertical axis plots current gross margin per SKU. The four quadrants that result each represent a different pricing opportunity, and each requires a different strategic action. Applying the same action across quadrants destroys value in at least two of the four.
The counter-intuitive insight that separates a good answer from a great one: the highest-priority pricing action in this case is not the one that cuts prices to gain volume — it is the one that raises prices on sticky, low-margin SKUs to capture consumer surplus that the current cost-plus pricing model has been leaving on the table for years.
The consumer surplus concept is the microeconomic foundation of the Quadrant IV recommendation. Consumer surplus is the gap between what a buyer would be willing to pay for a product and what they are actually charged. For a specialty condiment that a chef considers non-negotiable in a signature dish, the willingness to pay may be substantially higher than the current list price — especially if the price is small relative to the dish's overall cost and the switching friction is high. Cost-plus pricing systematically underprices these SKUs. The elasticity matrix identifies them precisely.
The experience curve compounding mechanism — the senior-level close: The North America price-cut strategy creates a self-reinforcing advantage over time. Volume growth from share capture increases the client's purchasing scale, which enables COGS renegotiation with suppliers, which improves the underlying unit economics, which funds further price cuts. A competitor who matches the price cut does not also receive the COGS improvement — only the higher-volume operator does. This is the experience curve feedback loop, and naming it transforms the pricing recommendation from a tactical move into a structural competitive moat argument.
### Implementation Risks: Where Consultants Fail
The elasticity-margin matrix is a compelling framework. Its credibility in a board presentation — and in a case interview — depends on whether the candidate has thought through the conditions under which it fails. There are five implementation risks specific to this case. Addressing them proactively is what separates an expert-level answer from a good-level one.
The data granularity risk is the most foundational. A client that tracks profitability by category — fresh produce, dry goods, proteins — cannot execute a SKU-level pricing strategy. The matrix requires SKU-level price sensitivity data, which most food wholesalers do not currently have in a form that supports elasticity estimation. The first action in the recommendation must always be the data audit — not the price change.
### The Sequenced Recommendation
The recommendation is not a single pricing action. It is a sequenced program that builds from a data foundation through short-term margin improvement to medium-term market share capture. The sequence matters: each phase creates the conditions for the next, and executing out of order — beginning with North America price cuts before the cash reserve from Quadrant IV price increases has been built — exposes the client to margin risk before the share gains materialize.
Why the sequence is the recommendation: A candidate who presents the correct moves but in the wrong order — cutting North America prices before raising Quadrant IV prices — is recommending a strategy that creates short-term margin pressure before the offsetting gains arrive. The interviewer will ask: 'How do you fund the North America price cuts while waiting for volume to grow?' The answer is: you fund them with the margin improvement from Quadrant IV. That sequencing logic is what makes the recommendation internally consistent.
### The Five-Step Interview Framework
The principle that governs every mature market profitability case: In mature markets, you do not find profit by doing something new. You find it by pricing what you already have more intelligently. The client has been treating its entire product catalog as one business, applying regional average pricing that leaves consumer surplus on every sticky SKU and misses share-capture opportunities on every elastic one. The elasticity-margin matrix does not create new value — it reveals the value that the current pricing architecture has been systematically destroying. That reframe is the analytical contribution of the consulting engagement.




---
# Case 28 - Orrington School Consolidation
Source: articles/case-strategy/case-28-orrington-consolidation.mdx
### The Consolidation Play: Rescuing Orrington Office Supplies
A $275M manufacturer running at 50% capacity across three plants. The fix isn't more sales — it's fewer factories. How to triple pre-tax profit through structural cost surgery.
In manufacturing turnaround cases, the most dangerous first instinct is to look for growth. If a company is struggling with falling profits, the natural response is to ask how it can sell more. In high-fixed-cost businesses running at half capacity, that instinct is precisely backwards — and the case is designed to expose it.
Orrington Office Supplies is a $275M manufacturer with 12,500 SKUs and three production plants in Mexico, Michigan, and New Jersey. All three plants are running at approximately 50% capacity. Profit is thin and deteriorating. The company is approaching acquisition target territory. The question is not how to grow OOS — it is how to restructure it so that the revenue it already has generates a defensible margin.
This is Case 28 in HéraAI's Case Strategy Chamber series. The answer involves closing two of the three plants, rationalizing the SKU catalog, and centralizing production in Mexico. Pre-tax profit triples from $25M to $82M — without a single dollar of revenue growth. Here is how to structure the analysis.
### Step 1 — Diagnosing the High Fixed-Cost Trap
The first analytical move in any manufacturing profitability case is to separate fixed costs from variable costs — and then determine whether the fixed cost structure is sized for the actual volume level the business is running at. In OOS's case, the answer is stark: the company is paying for three full-scale manufacturing plants while running each at 50% utilization.
This is not a revenue problem. Revenue at $275M is stable. It is a structural cost problem — one that cannot be solved by selling more product unless revenue can be grown fast enough to fill capacity across all three plants simultaneously, which is an aggressive assumption in a mature office supply market. The table below maps the P&L to the diagnostic.
The diagnostic question that reframes the entire case: At what utilization level does the current fixed cost structure become viable? In OOS's case, the fixed costs are sized for a business running at close to 100% capacity across three plants. At 50%, the company is carrying approximately $42M in excess fixed cost annually — the cost of one full plant that adds no incremental production value. That is the gap the consolidation closes.
### Step 2 — SKU Rationalization: Clearing the Path for Consolidation
Before any plant can be closed, the production complexity that requires three plants must be addressed. OOS operates 12,500 SKUs — a catalog that is significantly broader than most competitors in the office supply space. That breadth means frequent production changeovers, complex scheduling, distributed inventory, and a manufacturing footprint that requires multiple facilities to manage effectively.
The 80/20 analysis reveals that the bottom 500 SKUs — approximately 4% of the catalog — represent a disproportionate share of operational friction for a small share of total revenue. Removing them costs $11M — acceptable in the context of a $57M profit improvement — and directly enables the consolidation by reducing catalog complexity to a level the Chihuahua plant can absorb alone.
The sequencing insight that separates good from great: SKU rationalization must come before plant consolidation in the analysis — not as an afterthought. A candidate who recommends closing the US plants without first confirming that the Mexico plant can handle the full catalog complexity is presenting a recommendation with an unvalidated execution assumption at its core. The sequence is: simplify the catalog → confirm Mexico can absorb it → then close the US plants.
### Step 3 — Evaluating the Three-Plant Network
With the SKU catalog rationalized to 12,000 products, the question becomes which plant or plants to retain. The network evaluation considers cost structure, capacity, geographic positioning, and workforce risk. The answer points clearly to Chihuahua as the consolidation hub — but understanding why Michigan and New Jersey must close, and what the closure risks are, is what the interviewer is probing.
The critical validation step before recommending closure of the US plants: confirm that Chihuahua's actual capacity — not assumed capacity — can absorb the consolidated volume across 12,000 SKUs at the required service levels. This is not a financial modeling question. It is an operational due diligence requirement. The recommendation is only as sound as this validation.
### Step 4 — The P&L Bridge: From $25M to $82M
The profit improvement story is most powerfully told as a bridge — a line-by-line walk from the current $25M baseline to the $82M post-consolidation outcome. Each line has a specific driver and a specific calculation logic. Walking through it explicitly, rather than announcing the result, demonstrates both analytical rigor and communication clarity.
The net economics of the consolidation: $98M in fixed cost savings from the US plant closures, minus $48M in incremental Mexico variable costs to handle the additional volume, minus $11M in revenue from SKU rationalization, plus the $25M baseline = $82M. The Mexico variable cost is lower than the US fixed cost removal because the marginal cost of incremental production at an already-operational, lower-cost facility is fundamentally different from the full fixed cost burden of maintaining a separate plant. This is the geographic arbitrage at the heart of the case.
The arithmetic that interviewers probe: Why is the Mexico incremental cost only $48M when we're moving the equivalent of two US plants worth of volume? Because Chihuahua already has the fixed cost infrastructure in place. The $48M represents only the variable cost increment — materials, labour hours, and logistics for the additional volume. There is no new rent, no new machinery, no new plant management. The fixed cost of the Mexico plant is already embedded in the baseline. This distinction is the crux of the geographic arbitrage argument.
#### Step 5 — The Risks That Can Sink a Mathematically Sound Recommendation
The P&L bridge shows a compelling financial outcome. The question the interviewer is waiting for is whether the candidate understands that financial models don't close plants — people, unions, regulators, and supply chains do. The risks below are not edge cases. They are execution conditions that determine whether the $82M outcome is achievable in practice.
The labor union risk deserves the most airtime in the board presentation — not because it is the largest financial risk, but because it is the risk with the most asymmetric downside. A poorly managed union negotiation can result in work stoppages at the US plants during the transition period, damaging customer relationships and potentially triggering contract penalties that dwarf the severance cost. The CEO who announces the closures without a pre-negotiated transition plan is presenting a strategy, not an execution plan.
### The Five-Step Interview Framework
The table below consolidates the full case structure for interview preparation. Each step includes the analytical action, the common trap, and the framing that demonstrates the judgment difference between a good answer and a consulting offer.
The principle that governs every manufacturing turnaround case: You cannot grow your way out of a broken cost structure. When fixed costs are too high relative to the revenue the business generates, the only solutions are to increase volume significantly (hard and uncertain), reduce fixed costs structurally (consolidation), or accept a declining margin trajectory. OOS cannot grow fast enough to justify three underutilized plants. The consolidation is not the aggressive option — it is the only analytically defensible one. The candidate who sees that clearly, before being prompted, is demonstrating exactly the commercial judgment that MBB firms are hiring for.


---
# Case 29 - Sugar Beet Revolution
Source: articles/case-strategy/case-29-sugar-beet-revolution.mdx
#### The Sugar Beet Revolution: Why a 200% Yield Increase Isn't Always a Win
Vindaloo Biotech has doubled the sugar yield per beet. Most candidates see doubled revenue. The correct answer is a $5B cost-savings story — and the trap that eliminates 80% of applicants.
In biotech and agtech case interviews, 'breakthrough' almost always triggers the same instinct: more output means more revenue. It's the most natural framing — and in commodity markets, it is precisely wrong. Case 29 is designed to expose that instinct and replace it with the analytical framework that actually applies when demand is fixed.
Vindaloo has engineered a sugar beet that produces 2 lbs of refined sugar instead of the standard 1 lb. The global sugar market is worth $2B per year. On the surface, this looks like a technology that doubles the market. The correct analysis shows it does something more valuable and more defensible: it compresses the cost structure of a $2B industry by approximately 20% — generating $400M per year in durable, IP-protected savings. That is the $5B asset.
This is Case 29 in HéraAI's Case Strategy Chamber series. Here is how a top-tier consulting candidate structures the analysis — and the five traps the case is designed to surface.
### The Reframe That Decides the Case: Fixed Demand, Variable Cost
The first analytical question in any market entry or technology valuation case is: what type of market is this? In a growth market, innovation creates value through revenue expansion — new customers, new use cases, higher penetration. In a commodity market with fixed or inelastic demand, that mechanism does not apply.
Sugar has a demand elasticity of approximately 1. Consumers do not put more sugar in their coffee because sugar becomes cheaper. Food manufacturers do not reformulate their products on a short timeline in response to price changes. The total market stays at roughly $2B regardless of how efficiently Vindaloo's beet produces the supply. All of the value created by the innovation lives on the cost side of the ledger — not the revenue side.
The reframe that wins the case: The moment a candidate says 'in a commodity market with fixed demand, the value of this technology is entirely in cost savings — not revenue growth' they have demonstrated the analytical lens the case is designed to test. Everything that follows is quantification. The reframe is the insight.
### Mapping the Value Chain: Where the Savings Live
Once the cost-savings lens is established, the analysis requires mapping the full value chain and identifying where Vindaloo's technology changes input requirements at each stage. The key principle: savings only exist where the seed's properties — specifically, doubled sugar concentration per beet — reduce the physical inputs required to produce the same output volume of refined sugar.
The value chain has four stages with different cost shares and different sensitivity to the seed's yield improvement. The table below models the savings decomposition across each stage.
The distribution stage is the analytical precision point most candidates miss. Distribution costs are based on the weight of refined sugar delivered — 1 lb of sugar is 1 lb of sugar regardless of how many beets it took to produce it. Downstream logistics are entirely unaffected by the upstream yield improvement. Candidates who apply a blanket 50% savings across all four stages are overcounting by approximately $80M — and will be challenged on it.
The trucking 'dead weight' argument — the senior insight: The largest proportional gain in the value chain is not in farming — it's in trucking, relative to its cost base. Today, a truck carries 1 tonne of beets to extract approximately 200 lbs of sugar. With Vindaloo's seed, the same tonne of beets yields 400 lbs. Half the truck trips are required for the same sugar output. The 'dead weight' being eliminated — the non-sugar mass of the beet transported to the refinery — is the clearest illustration of why this innovation creates value even though it cannot create more sugar demand.
### The Perpetuity Valuation: From Annual Savings to Enterprise Value
With $400M in annual cost savings established, the valuation uses the Gordon Growth Model — a growing perpetuity formula appropriate for a stable, IP-protected cash flow stream in a mature market. The formula: Value = Annual Cash Flow ÷ (Discount Rate − Terminal Growth Rate).
The base case uses a 10% WACC — reflecting the biotech risk premium — and a 2% terminal growth rate, consistent with long-term sugar market growth. The table below presents the base case and three sensitivity scenarios that bound the valuation range.
The sensitivity analysis is not a formality — it is the argument. A $5B point estimate presented without bounds is not a valuation; it is a number. The scenarios that matter most are the downside cases: partial savings realization due to incomplete acreage reduction ($4B), and the glut scenario in which commodity price erosion eliminates most of the modeled saving ($2.5B). Presenting these scenarios proactively demonstrates the discipline to stress-test your own analysis.
When to use perpetuity vs. DCF in a case: In case interviews, use the perpetuity formula when the cash flow is recurring, relatively stable, and expected to continue indefinitely — as with a licensing fee on a widely-adopted agricultural technology. Use a full DCF model when cash flows have a defined finite life, significant near-term volatility, or a terminal event (sale, patent expiry, market saturation). For Vindaloo, the perpetuity is the correct anchor — with the caveat that the patent lifecycle creates a finite protection window that should be noted.
### The Risks the Board Must Address
A $5B valuation is a ceiling that rests on specific assumptions. Two of those assumptions — that farmers will reduce acreage and that the patent will hold — are not guaranteed. The risk register below captures the factors that could compress the valuation and the mitigation strategies that address each one.
The supply glut risk is the most important conversation in the board presentation. The entire valuation model depends on the market not being oversupplied. A farmer who adopts the new seed and maintains current acreage produces twice as much sugar — and the price mechanism does the rest. For the savings to materialize, the aggregate farming sector must reduce planted area by approximately 50%. This requires either market price signals strong enough to drive voluntary reduction, or contractual licensing terms that enforce it. Vindaloo's go-to-market strategy should address this directly.
### The Five-Step Interview Framework
The table below consolidates the full case approach for interview preparation. Each step includes the analytical action, the common trap, and the framing that demonstrates senior-level commercial judgment.
The principle that governs every commodity valuation case: In a commodity market, efficiency is the product. The company that wins is not the one with the highest output — it is the one with the lowest cost to produce an equivalent output. Vindaloo's innovation is not that it grows more sugar. It is that it grows the same amount of sugar for less land, fewer trucks, and less factory time. That is a $5B idea. A seed that simply grows more sugar in a market that cannot absorb more sugar is not a business — it is a science project.


---
# Case 3: From $250M to $1 Billion in 5 Years — Deloitte Growth Strategy Case
Source: articles/case-strategy/case-3.mdx
By Shuangshuang Wu · HéraAI · January 19, 2026 · 11 min read · Case Source: Deloitte Consulting
Most candidates walk into a growth strategy case and immediately start listing tactics. The ones who get offers start by diagnosing why growth has stalled — and building a framework that separates genuine opportunity from wishful thinking.
{/* Stats Cards */}
3–4%
historical growth rate being challenged
10–15%
target growth rate set by the CEO
4×
projected size increase — $250M → $1B in 5 years
The Deloitte Growth Strategy Case is one of the most instructive cases in consulting interview preparation — not because it's technically complex, but because it puts the candidate in a situation that mirrors real strategic advisory work. The client isn't in crisis. The business is functional, growing at market rate, and led by a manager who genuinely believes there is no untapped potential. Your job isn't to validate that belief. It's to challenge it rigorously — and construct a credible path to 10–15% annual growth. Here are the four analytical moves that separate strong candidates from hired ones.
1. The Case Opens With a Skeptical Client — That's the First Test
The setup is deliberate. Performance Chemicals' business manager does not believe significant untapped potential exists in his markets. He has approached Deloitte not to validate a growth plan — but to get external cover for a conservative position.
This is a classic consulting dynamic: the client is smart, experienced, and wrong in a specific, diagnosable way. Your first job is not to present a growth strategy. It's to establish why the client's mental model of the market is too narrow.
| The Client's Mental Model vs. The Consulting Reframe |
| Client's view |
Growth is limited by market size. We're already serving the available market at the available rate. 3–4% is what's possible. |
| The flaw |
This assumes the only growth lever is penetrating existing markets with existing products. It excludes channel strategy, business model innovation, and cross-industry applications of existing technology. |
| The consulting reframe |
The right question isn't 'can we grow faster in our current markets?' It's 'are we in the right markets, with the right model, capturing the right type of value?' Those are three separate questions with three separate answers. |
Interview Signal
When you encounter a skeptical client setup in a case, don't rush to agree or disagree. Name the mental model the client is operating from — and then explain specifically which assumption you're going to test first. That's the move that signals structured, senior-level thinking.
2. Market Diagnosis Comes Before Strategy — Always
Before any growth recommendation is credible, you need to understand the market environment producing 3–4% growth. In this case, the diagnosis reveals structural constraints that make traditional product strategy insufficient on its own.
| Market Diagnostic: What the Numbers and Context Reveal |
| Growth rate match |
The division's 3–4% growth exactly mirrors the average growth rate of its served markets. This is not underperformance — it's market-rate performance. That's an important distinction: the problem isn't execution, it's strategic positioning. |
| Product portfolio |
Asphalt additives, sodium chemicals, paper pulp bleaching solutions. These are commodity-adjacent specialty chemicals — high technical barrier to entry historically, but increasingly exposed to global competition. |
| Competitive environment |
Limited intellectual property protection. Products are being commoditized. Pricing pressure is structural, not cyclical. Global competitors can replicate at lower cost. |
| Cultural constraint |
The business operates on a 'make it by the ton, sell it by the carload' philosophy. This is product-volume thinking — the exact mindset that prevents a services and solutions transition. |
💡 Expert Tip — The Diagnostic Question Hierarchy
First: Is the growth problem market-rate performance or underperformance? (Here: market-rate — so the strategy must expand beyond current markets, not just execute better within them.)
Second: Is the constraint competitive, structural, or internal? (Here: all three — commoditization, IP exposure, and a culture that doesn't think in solutions.)
Third: What trends are reshaping the industry that could be exploited rather than defended against? (Here: outsourcing, product-service bundling, solutions vs. products.)
3. The Growth Spectrum Framework — and How to Apply It Under Interview Pressure
Once the market diagnosis is complete, the case calls for a structured framework to explore growth opportunities systematically. A Growth Spectrum — ranging from lower-risk product enhancements to higher-risk new business model innovation — prevents the common mistake of jumping straight to the most dramatic option.
Product Enhancements
Upgrade existing products to defend margin and slow commoditization.
New Products
R&D into adjacent chemistries that serve existing customer relationships.
New Markets
Apply existing technical capabilities to industries currently underserved.
New Channels
Reach customers through distribution, digital, or direct service models.
New Business Models
Shift from product transactions to service contracts, bundles, and managed inventory.
The critical discipline: each lever on the spectrum requires a different capability assessment. Product enhancements leverage existing R&D. New markets require channel and customer acquisition capabilities the company may not have. New business models require organizational and cultural transformation — which this company, by its own admission, is not currently built for.
| Applying the Growth Spectrum to Performance Chemicals |
| Product Enhancements |
Lowest risk. Extend existing asphalt additive and bleaching solution lines into adjacent performance specifications. Buys time but doesn't solve the commoditization trajectory. |
| New Markets |
Apply existing chemical technology to industries currently underserved — construction materials science, industrial water treatment, agricultural chemical applications. Requires market entry investment but leverages existing IP. |
| New Business Models |
The highest-impact lever. Shift from selling chemicals by volume to selling performance outcomes. Vendor-managed inventory, solution bundling, long-term service contracts. This is the move that separates a $250M product business from a $1B solutions business. |
Interview Signal
When applying a growth framework in a case, always connect each option to the client's specific capabilities and constraints — not just to abstract strategic logic. A new business model recommendation that ignores the 'make it by the ton' culture will get challenged immediately. The answer that wins the room acknowledges the constraint and proposes how to address it.
4. The Recommended Strategies — and the Reasoning Behind Them
Deloitte's approach was not to pick one growth lever — it was to run a structured diagnostic across all of them and identify the combination with the highest feasibility-to-impact ratio. The resulting strategy set reflects a deliberate progression from low-disruption to high-transformation.
Sell a solution, not a product
Reframe the value proposition from chemical volume to customer outcome. Asphalt additive customers don't want chemicals — they want road performance. Paper mills don't want bleaching solution — they want throughput and yield. This reframe is the foundation of every other recommendation.
Become indispensable to strategic customers
Identify the top 20% of customers who represent disproportionate revenue and deepen those relationships through co-development, embedded technical support, and long-term contracts. Switching cost creation is the most durable competitive advantage in commodity-adjacent markets.
Become one-stop shop for specialty chemicals
Expand the portfolio breadth so that strategic customers can source multiple product categories from a single supplier. Reduces procurement complexity for the customer; increases revenue per relationship for Performance Chemicals.
Vendor-managed inventory as a service
Take ownership of customer inventory management. This converts a transactional product sale into an ongoing service relationship — generating recurring revenue, deepening operational integration, and creating switching costs that price competition cannot easily overcome.
🎯 Interview Tactic — The Feasibility Challenge
The interviewer's likely follow-up: "How would you actually implement this in a company whose culture is 'make it by the ton, sell it by the carload'?"
✗ The weak answer
"We'd need to change the culture and hire new talent." (True but not actionable.)
✓ The strong answer
"Deloitte ran 2-day workshops with each niche business unit to build the business case for change from within — using the Valuable Formula methodology to connect strategic options to unit-level P&L impact. Culture change follows economic incentive when the math is made visible."
Real Interview Questions From This Case — and How to Answer Them
"How would you build a case for whether Performance Chemicals can grow at 10%+ per annum?"
Why they ask: To test whether you can structure an ambiguous growth mandate into a testable hypothesis — rather than jumping to recommendations.
Start by decomposing the 10% target: how much can come from existing markets (market share gain vs. market growth), how much must come from new markets or new business models, and what's the timeline assumption? Then identify which of those levers is most feasible given the company's current capabilities. The answer isn't a strategy — it's a diagnostic framework that leads to a strategy.
"The business manager doesn't believe there's untapped potential. How do you handle that?"
Why they ask: To test your ability to manage a skeptical client without being either dismissive or capitulating.
Acknowledge the manager's expertise — he knows his current markets better than any external consultant. Then reframe: the question isn't whether there's more potential in his current markets. It's whether the definition of 'his markets' is the right frame. A company that sells asphalt additives is in the road infrastructure performance business. That's a much larger and faster-growing market than 'asphalt additives.' Redefine the market before you argue about the growth rate.
What Deloitte Actually Did — and What It Teaches You
The Deloitte team ran a growth diagnostic to understand both the cultural and infrastructural impediments to growth. They conducted two-day workshops with each niche business unit — using the Valuable Formula methodology to develop alternative strategies unit by unit, rather than imposing a single top-down recommendation.
The output included product-service bundling, outsourcing partnerships, and new market applications for existing technological capabilities. Preliminary projections indicated the potential to quadruple Performance Chemicals from $250M to $1 billion within five years. The client agreed and implemented a subset of the strategies.
💡 The Meta-Lesson for Consulting Candidates
The case is not a puzzle with one right answer. It's a diagnostic process with multiple defensible conclusions.
The client's skepticism is data, not an obstacle. It tells you where the cultural and organizational resistance to growth actually lives — and that's where the real work begins.
The highest-value move in any growth case: Redefine the market before you redesign the strategy. A $250M business in a narrow market is often a $1B business in the right market — served the right way.
Growth Strategy Cases Reward Structured Diagnosis — Not the Fastest Route to Recommendations
The Performance Chemicals case is a master class in one of consulting's most important skills: the ability to tell a skeptical, experienced client something they don't already believe — and back it up with a framework rigorous enough that they can't dismiss it. That requires market diagnosis first, capability assessment second, and recommendation third. Never the other way around.
At HéraAI, we help candidates develop the diagnostic instincts and structural frameworks that make growth strategy cases — and the real client work they simulate — genuinely tractable.
This article is part of the Case Strategy Chamber series from HéraAI — Instant Access to 5.8M+ Active Jobs Worldwide.
---
# Case 30 - Olympic Broadcast Bid
Source: articles/case-strategy/case-30-olympic-broadcast-bid.mdx
#### The Time Value of Prime Time: The $177M Olympic Broadcast Bid
A TV network bidding in 2004 for the 2010 Winter Olympics. Three financial traps, one strategic recommendation, and the question every consulting interviewer is really asking.
Most candidates who see an Olympic broadcast case think: revenue minus costs. The interviewers know this. The case is designed to expose the three layers of financial reasoning that separate that first instinct from a senior-level recommendation: opportunity cost, time value of money, and the discipline to know when to bid above your own NPV calculation — and why.
This is Case 30 in HéraAI's Case Strategy Chamber series. The scenario: you're the CFO of a major TV network bidding in 2004 for the rights to broadcast the 2010 Winter Olympics — a 16-day event. The IOC wants a bid. You have a week to build the model and make the recommendation. Here is how a top-tier consulting candidate structures it.
### How to Structure This Case: The Three-Layer Framework
A media rights valuation case has three analytical layers, each of which is a separate failure point in an interview. The first layer — building the revenue model — is where most candidates focus all their preparation. The second layer — opportunity cost — is where approximately 70% of candidates fail on first pass. The third layer — discounting to present value — is where the senior-level filter operates.
### Step 1 — Building the Ad Inventory Model
Revenue in broadcast is a function of two variables: the price per ad slot and the number of slots available. Both are constrained. Consumer research establishes that audiences tolerate approximately 10 minutes of advertising per hour before engagement drops significantly — which translates to 6 thirty-second slots per hour. Price varies by daypart: prime time (8–11pm) commands $400k per slot; non-prime carries $200k.
The broadcast schedule covers 16 days: 10 weekdays, 4 weekend days, the Opening Ceremony, and the Closing Ceremony. Ceremonies are full prime-time events. The table below models the slot inventory across the full broadcast window.
Scaling the slot model to total gross revenue requires assumptions about the full broadcast day — not just the evening window modeled above. A full 16-day Olympic schedule includes approximately 15 hours of coverage per day across prime and non-prime dayparts. The total gross ad revenue, across all markets and daypart segments, reaches approximately $928M before costs.
The precision signal: In a case interview, candidates are not expected to produce the exact number — they are expected to demonstrate a logical, structured approach to estimation. Walking through the slot calculation tier by tier, naming the assumptions explicitly (6 slots per hour, prime vs. non-prime segmentation, ceremony premium), and arriving at a defensible order-of-magnitude estimate is more valuable than a precise figure reached through opaque reasoning.
### Step 2 — The Opportunity Cost Trap
Broadcasting the Olympics is not revenue with no cost beyond production. It displaces content. Every hour of Olympic coverage is an hour in which the network is not broadcasting its regular schedule — which already generates approximately $1M per hour in ad revenue from established programming. This is the opportunity cost of the bid, and it is the most commonly missed component in media valuation cases.
The displacement runs across approximately 154 hours of the broadcast window — the overlap between Olympic coverage hours and the network's existing primetime and daytime schedule. At $1M per hour, the opportunity cost is $154M. This is not a production expense. It is the revenue that the network gives up by showing the Olympics instead of its regular content.
Why this is the most important number in the case: The opportunity cost argument is what transforms this from an accounting exercise into a strategic one. A network with weak regular programming has a lower opportunity cost and a higher willingness to pay for rights. A network with strong primetime ratings faces a real trade-off between the Olympic halo effect and the disruption to its regular audience. Surfacing this dimension — without being asked — is the clearest signal of commercial judgment in this case type.
### Step 3 — The Full P&L and NPV Calculation
With gross revenue modeled and all costs identified, the P&L waterfall builds cleanly. The critical final step is discounting the 2010 net profit back to 2004 present value — the year of the bid. A 12% WACC applied over six years produces a discount factor of approximately 0.51, using the Rule of 72 as a mental model: at 12%, capital doubles every six years, meaning future cash flows are worth roughly half today.
The Rule of 72 is not a substitute for a precise DCF calculation — but it is exactly the kind of rapid approximation that case interviewers reward. Being able to say 'at 12% WACC, the Rule of 72 tells me this profit stream roughly halves over the six-year lag, giving us approximately $177M in today's dollars' demonstrates both financial fluency and the ability to reason quickly without a spreadsheet.
The number that the bid must be anchored to: $177M is the NPV floor — the point below which the investment creates value, and above which it destroys it on a pure financial basis. This is not the recommended bid. It is the analytical ceiling for the financial argument. The strategic recommendation builds from here.
### Step 4 — The Strategic Recommendation: Why $200M
The final output of this case is not a number. It is a recommendation with a justification. The NPV says the financial value of the broadcast rights, in 2004 dollars, is $177M. The recommendation is to bid $200M. The $23M difference — approximately 13% above NPV — requires a specific, defensible argument. In this case, there are two.
The discipline the recommendation requires: the prestige premium argument must be bounded. Candidates who argue for bidding $300M 'because the Olympics is priceless' have abandoned analytical reasoning for strategic hand-waving. The correct answer acknowledges the specific, quantifiable channels through which the premium creates value — and sets a limit on how far above NPV a rational bid can go.
### Step 5 — Risk Assessment
No bid recommendation is complete without a risk frame. This case was set in 2004 for a 2010 event — a period that bridged a significant structural shift in how audiences consumed television. The risk register below captures the factors that could cause the realized return to fall below the modeled NPV.
The viewing habit shift risk deserves specific attention because it is structural rather than probabilistic. By 2010, DVR penetration had reached approximately 40% of US households, and online streaming was beginning its early-stage growth. A model built on 2004 linear TV economics was already discounting a structural trend that would accelerate significantly in the following decade. The sophisticated candidate acknowledges this explicitly and suggests that the model should incorporate a downside scenario with a 10–15% audience discount to test the bid's robustness.
### The Five-Step Interview Framework
The table below consolidates the full case approach into an interview-ready structure. Each step includes the action, the common trap, and the framing that separates a good answer from a great one.
The meta-principle this case tests: A bid is not an NPV calculation. It is a judgment call about risk appetite, competitive dynamics, and the value of intangibles — anchored by an NPV calculation. Candidates who treat the math as the conclusion have misunderstood the question. Candidates who ignore the math in favor of strategic intuition have also misunderstood the question. The answer that wins is the one that does both: rigorous quantitative foundation, strategically intelligent recommendation built on top of it.



---
# Case 4 - Business Model Assessment
Source: articles/case-strategy/case-4.mdx
### Case 4: Wealth Advisory — When Independence Is Not Enough
A premium wealth advisory firm losing revenue in the affluent individual segment. The problem is not execution — it is a structural value chain gap that independent advisors cannot close without a deliberate strategic choice. Four different competitors are exploiting it simultaneously.
Case 4 is a Deloitte-style market disruption case set in luxury financial services. A premium wealth advisory firm is experiencing revenue decline in the affluent individual segment — a market it once dominated through independent, advice-first positioning. The surface diagnosis — competitor pressure, pricing erosion — understates the structural nature of the problem.
The core issue is a value chain gap. The client's strength is upstream: independent advice, trusted client relationships, deep expertise. Its structural weakness is downstream: SEC restrictions limit control over product selection and transaction execution. This gap was manageable when independent advice was the primary client demand. It has become critical as new entrants offer end-to-end solutions that eliminate the need to choose between advice quality and execution convenience.
The disruption is not coming from a single source. Investment banks are moving down-market with bundled offerings. Fintechs are undercutting on cost structure with technology-driven advice. Big 4 firms are bundling advisory into integrated platforms. Robo-advisors are capturing the next generation of affluent clients before they reach the premium advisory threshold. Each competitor exploits a different dimension of the client's structural gap — which means a single defensive response is insufficient.
#### Value Chain Analysis: Where the Model Holds and Where It Breaks
The first analytical move is to map the full advisory value chain and identify where the client's capabilities are genuinely strong and where the structural gap creates vulnerability. The left-right comparison below makes the asymmetry visible.
The value chain framing that unlocks the case: 'A strong upstream capability cannot compensate for a downstream constraint when clients are increasingly purchasing the full value chain as an integrated product. Independence is valuable — but independence without execution means the client depends on a third party to complete the service it has sold. When that third party is also a competitor, or when integrated alternatives eliminate the need for the dependency, independence becomes a positioning claim rather than a delivered advantage.'
### Four Disruption Mechanisms — Four Different Threats
The competitive disruption in Case 4 does not come from a single source. Mapping each competitor type to its specific attack mechanism reveals that a single strategic response will be insufficient — and that the recommendation must address the structural gap rather than any individual competitor.
### Strategic Paths: Three Options, One Analytical Tool
The three strategic paths available to the client require different trade-offs and different capital commitments. Conjoint analysis is the analytical tool that makes the choice between them data-driven rather than directional.
The conjoint analysis framing that elevates the answer: 'Before recommending a strategic path, I would use conjoint analysis to quantify how this client's affluent segment trades off independence against cost, convenience, and integrated delivery. The output tells us: what percentage of the current client base will pay the current fee for independence-only advisory; at what price point does the integrated model become the preferred choice; and which client sub-segments — ultra-HNW, business owners, cross-border families — have planning complexity that the independent model uniquely addresses. Strategy built on this analysis is specific to the client's market rather than a generic response to fintech disruption.'
### The 5-Step Framework
The meta-lesson that Case 4 is designed to teach — applicable to every market disruption case in professional services: Frameworks are only the starting point. Real value comes from linking market dynamics directly to the client's specific value proposition and its blind spots. In Case 4, the blind spot is the value chain gap that independence creates — an upstream strength that is not matched by downstream control. Every disruption case in professional services should begin with this value chain mapping before any competitor analysis begins. The gap in the chain is always where disruption enters.'


---
# Case 5 - Competitive Strategy
Source: articles/case-strategy/case-5.mdx
#### Case 5: Technology Product Warehouser — When the Best Advice Is to Stop Playing
Eight consecutive quarters of profit decline. Simultaneous price, volume, and market size contraction. Manufacturers restructuring the value chain to bypass intermediaries entirely. Sometimes the hardest consulting lesson is knowing when not to recommend a turnaround.
Case 5 is one of the most instructive cases in the series — not because it involves complex calculations, but because it demands something harder: the ability to separate evidence from hope, and to deliver a strategic recommendation that management does not want to hear. A technology product warehouser in the telephony sector has experienced eight consecutive quarters of declining profits. From 2000 to 2002, the industry shrank simultaneously across price, volume, and total market size. Manufacturers began bypassing intermediaries to sell direct. Market share fell from 33% to 25%, with the steepest losses in the Value-Added segment — the one where differentiation was supposed to matter most.
The analytical challenge is not identifying that the business is declining. The data makes that obvious. The challenge is classifying the decline correctly — structural, not cyclical — and resisting the temptation to propose operational improvements that look like consulting value but cannot address the root cause. A business whose structural role in the value chain is being eliminated cannot be saved by cost reduction, service improvement, or targeted marketing. It can be redirected — through diversification into adjacent categories — or it can be exited responsibly through sale or orderly closure.
Case 5 tests three skills that are critical in real consulting engagements: recognising structural decline from a data pattern, separating what hope says from what evidence shows, and communicating clear, honest recommendations even when the conclusion is uncomfortable. These are the skills that distinguish a consultant who advises with clarity from one who defers the hard conversation until it costs the client more than it had to.
#### Five Structural Signals — and Why Each Rules Out a Cyclical Explanation
The case diagnosis begins with data. Before any strategic option is considered, five signals must be read correctly — each one ruling out a different cyclical or firm-specific explanation, and collectively pointing to a structural industry decline that no internally-focused response can reverse.
The analytical discipline the case is testing: 'Before I recommend any strategic response, I want to confirm whether this is a structural or cyclical decline — because the correct response to each is completely different. Cyclical decline warrants patience, cost management, and a turnaround plan. Structural decline warrants exit optionality. The data shows simultaneous price and volume contraction across all segments, total market shrinkage, disintermediation by manufacturers, and eight consecutive quarters without a positive inflection. That pattern is structural. My recommendation must match that diagnosis.'
### Separating Hope from Evidence
Every structurally declining business has a management team with a set of beliefs about why recovery is coming. Part of the consultant's job is to surface these beliefs, pair each one with the specific data that contradicts it, and do so without dismissing management's perspective. The table below maps the five most common hopeful hypotheses against what the evidence in Case 5 actually shows.
Why separating hope from evidence is a consulting skill, not a personality trait: 'Management is not irrational for holding these beliefs — they are emotionally invested in a business they built and a team they are responsible for. The consultant's role is not to dismiss that investment but to make the gap between the belief and the evidence visible and specific. A general statement that 'the market is structurally challenging' is not enough. Pairing each hopeful hypothesis with the specific data point that contradicts it gives management a clear basis for the recommendation — and makes it harder to dismiss the conclusion as consulting pessimism rather than data-driven analysis.'
### Strategic Options: The Viable Space Narrows to Three
When structural decline is confirmed and no differentiation or cost lever remains, the strategic option space narrows. The correct recommendation names all three viable options explicitly, evaluates each against the client's specific capital position and timeline, and identifies which is most appropriate — without softening the conclusion.
### The 5-Step Framework
The meta-lesson that Case 5 is designed to teach — applicable to every structural decline and exit strategy case: Case interviews test more than calculations and frameworks. They test the ability to recognise structural decline in a data pattern, separate hope from evidence in a way that is specific and credible, and communicate a clear strategic recommendation even when the conclusion is uncomfortable. The best advice in a structurally declining business is not always how to win. Sometimes it is when not to keep playing — and delivering that conclusion with evidence, clarity, and confidence is the highest-value contribution a consultant can make.
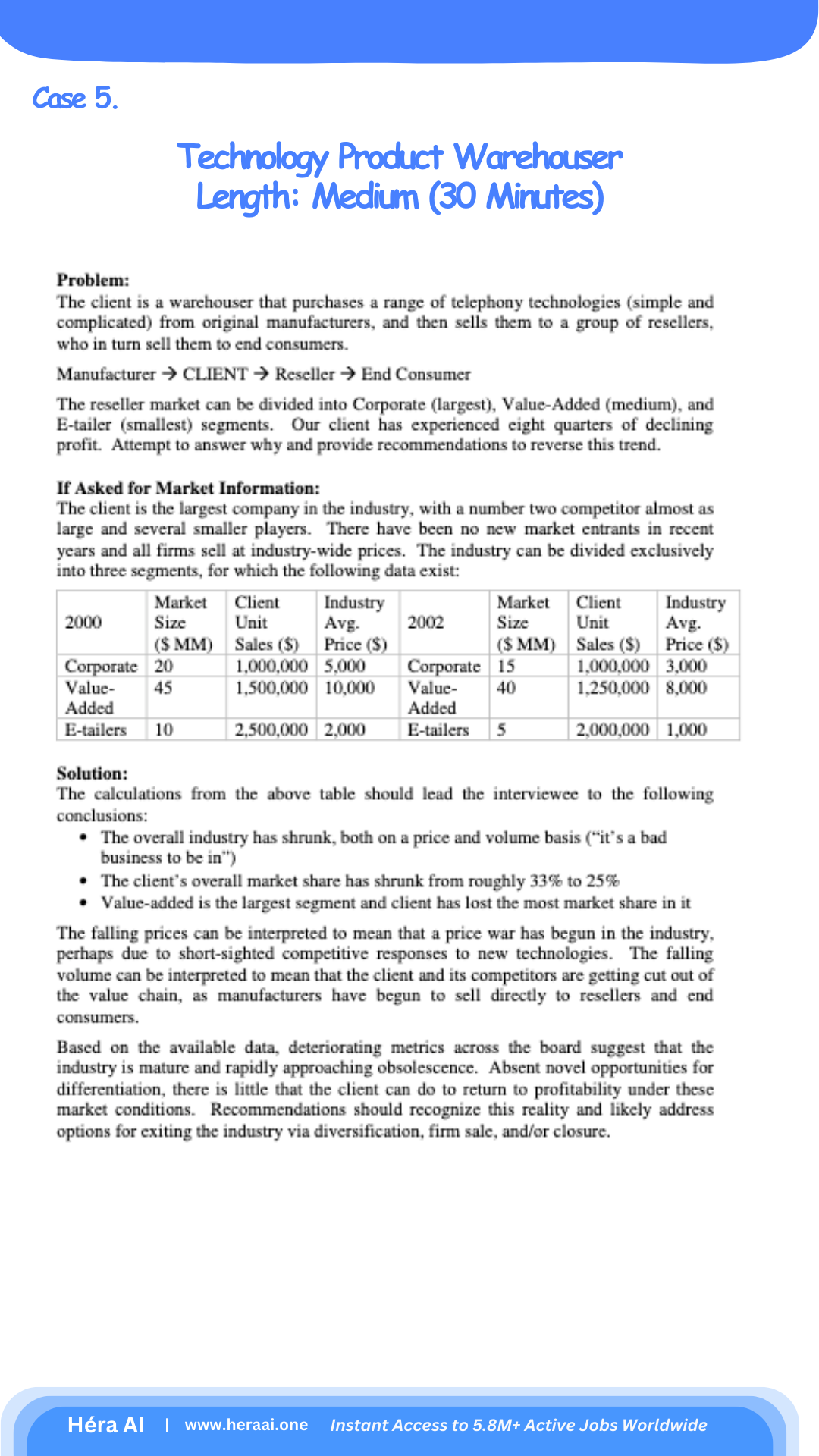
---
# Case 6 - Growth Strategy Analysis
Source: articles/case-strategy/case-6.mdx
#### Case 6: Telecom Wholesale — Using Data to Tell the Hard Truth
Eight consecutive quarters of profit decline. Prices down. Volumes down. Market share eroding in every segment. Manufacturers bypassing wholesalers entirely. The data pattern has a story — and the consultant's job is to read it accurately, not optimistically.
Case 6 is a short but dense case — designed to be completed in 15 minutes — that tests one of the most important consulting skills: the ability to distinguish a firm-specific execution problem from a structural industry decline. The surface question is why profit has been falling for eight quarters. The real question is whether the decline is reversible — and whether the right response is an improvement plan or an exit strategy.
The data pattern is unambiguous once it is read correctly. Price and volume declining simultaneously across all three segments (Corporate, Value-Added Resellers, E-tailers) rules out any hypothesis centred on the client's individual execution failures. Market share falling from 33% to 25% in the largest segment confirms that the client is not merely underperforming a stable market — it is losing ground in a contracting one. The E-tailer segment halving in two years signals that an entire customer type has already exited the wholesale channel. And manufacturers bypassing wholesalers entirely is not a competitive threat — it is a structural elimination of the wholesaler's role in the value chain.
This case is not about finding a growth lever or identifying an operational improvement. It is about using data to reach a clear-eyed conclusion about structural decline — and recommending the strategic options that match the reality: diversification, sale, or orderly closure. Candidates who arrive at an improvement plan have misread the data. Candidates who name the structural reality and propose realistic responses have demonstrated what consulting judgment actually looks like.
### Segment-by-Segment Deterioration: Reading the Pattern
The first step is to map the decline across all three segments and identify what the pattern reveals about whether the problem is structural or operational. When all three segments deteriorate simultaneously in both price and volume, the data is pointing to an industry-level shift — not a firm-level execution gap.
The diagnostic read that separates structural from cyclical: 'Price and volume declining together in every segment simultaneously is a structural signal, not an execution signal. If the client were underperforming operationally, we would expect to see peer companies holding share while the client loses it. If the market itself is structurally declining, we would expect the pattern we see: broad-based, multi-segment deterioration that cannot be explained by any internal factor. I would want to confirm that competitors are experiencing similar trends — if they are, this is industry structure, not execution. If they are not, we have a firm-specific problem worth diagnosing further.'
### Structural vs Firm-Specific: How to Read Five Key Data Signals
Each data signal in Case 6 carries a specific diagnostic implication. The table below pairs each observation with the distinction it enables — firm-specific (addressable by execution improvement) versus structural (requiring a strategic response that may include exit).
### Strategic Options: When the Viable Space Narrows to Three
When structural decline is confirmed — disintermediation eliminating the wholesale role, all segments deteriorating, no differentiation or cost levers remaining — the strategic option space narrows. The honest recommendation covers three paths and names which is most appropriate given the client's specific circumstances.
The recommendation framing that demonstrates consulting maturity: 'My recommendation is structured around three realistic options, in order of value preservation. First, explore diversification into adjacent categories where the logistics and supplier relationship capabilities generate defensible margin — this requires a 60-day capability and market assessment. Second, if diversification is not capital-viable, initiate a sale process within the next two quarters while the business still operates and a credible sale price is achievable. Third, if sale is not feasible, plan an orderly wind-down that preserves residual value for stakeholders. I am not recommending an improvement plan because the data does not support the premise that this is an execution problem. It is a structural problem, and the response must match the diagnosis.'
### The 5-Step Framework
The meta-lesson that Case 6 is designed to teach — applicable to every structural decline and industry lifecycle case: Consulting is not just about solving problems. It is about using data to tell the hard truth and guide leadership toward realistic strategic decisions. The most valuable thing a consultant can deliver in a structural decline situation is clarity — about what the data shows, what it means for the options available, and what the cost of delay is. A recommendation that softens the structural reality to make it more palatable is not consulting. It is delay. Each quarter of inaction in a structurally declining business narrows the options and reduces the recoverable value. Data-driven clarity, delivered with confidence and evidence, is the highest-value contribution available.
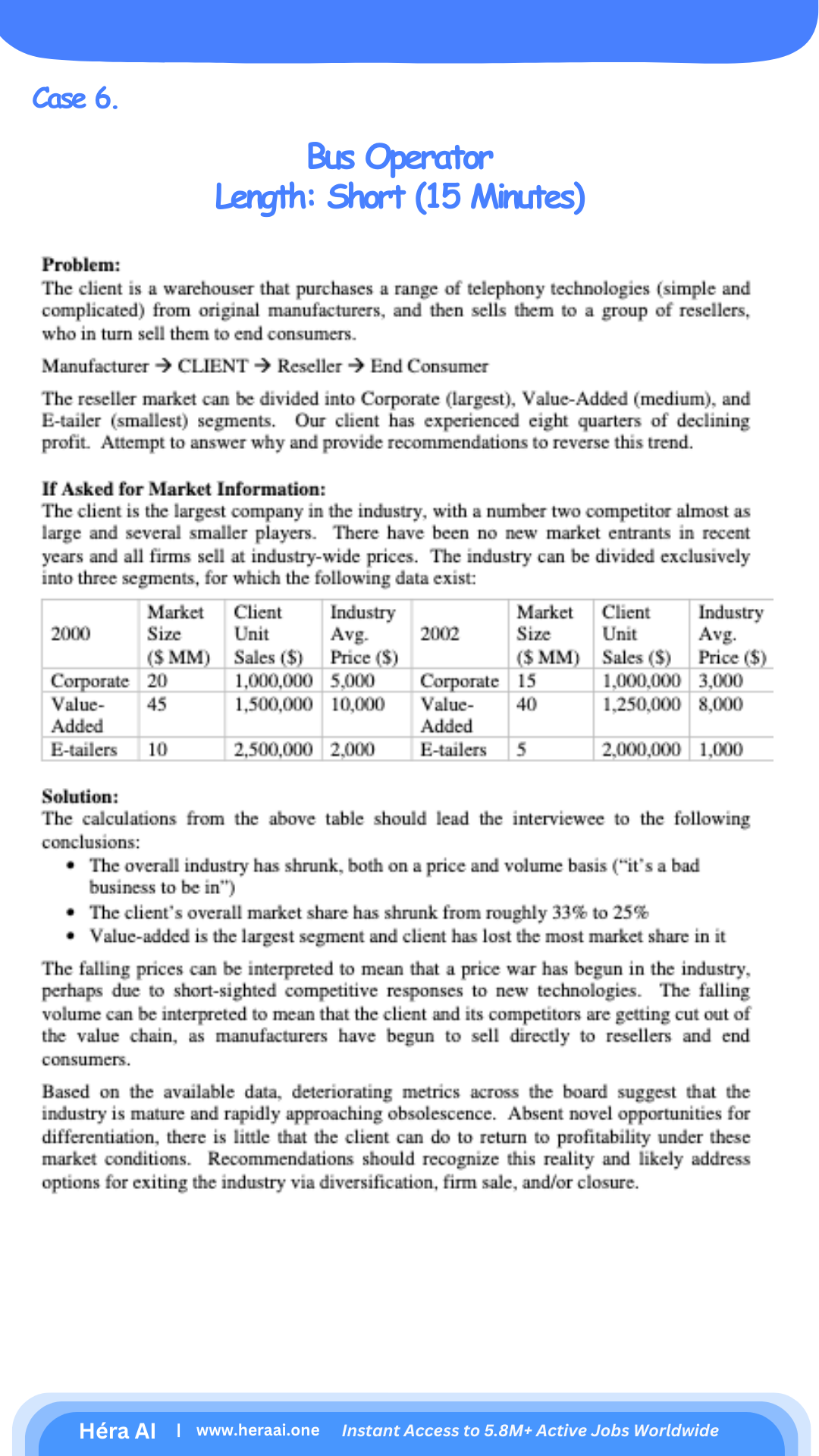
---
# Case 7 - Operational Excellence
Source: articles/case-strategy/case-7.mdx
#### Case 7: Premium Apparel — When Your Distributor Becomes Your Competitor
Market share fell from 15% to 7% in a growing market. Prices unchanged. Costs unchanged. No obvious competitor moves. The problem was not what the client was doing wrong — it was what its channel partners started doing differently.
Case 7 is a market share decline case with a diagnostic trap. The headline numbers are puzzling: share halved in a growing market, with no price changes, no cost disruption, and no visible competitive product entry. The standard hypotheses — pricing, demand, product quality, cost structure — are all eliminated by the facts given. The problem only becomes visible when the analysis shifts from the client's internal operations to the structure of the value chain through which its products reach customers.
The diagnosis is channel power and incentive misalignment. Seventy percent of the client's sales flowed through large multi-brand retailers. Those retailers launched their own premium private-label brands — and in doing so, reversed their incentive structure. The distributor, previously a partner whose profits depended on selling the client's product well, became a competitor whose profits depended on replacing it. With control of shelf space, product placement, and staff recommendation, the distributor could execute that substitution quietly, in every store, without any single visible competitive event.
The second condition that made the decline so severe was low brand recognition. Brand pull — customers actively seeking the brand by name — is the only reliable demand-side protection against distributor substitution. Without it, the client had no ability to prevent the channel shift from translating directly into lost sales. Both conditions were necessary: channel concentration made the client structurally exposed, and the absence of brand pull removed the protection that would have limited the damage.
### Diagnostic Elimination: Ruling Out the Standard Hypotheses
A market share decline case should begin with a systematic elimination of the standard hypotheses before looking for an unconventional root cause. In Case 7, the data given eliminates every standard explanation — which is the signal that the problem lives somewhere less obvious.
The diagnostic discipline that interviewers are testing: 'I want to work through the standard hypotheses before looking elsewhere — because if any of them apply, the solution is straightforward. Pricing unchanged, so no affordability issue. Market growing, so no demand collapse. No product disruption identified, so no quality gap. Costs unchanged, so no supply-side deterioration. All four eliminated. That means the problem is not inside the client's operations — it is in the relationship between the client and the pathway through which its products reach customers. I would like to explore the distribution channel next.'
### The Root Cause: Channel Power Shift and Brand Pull Absence
Once the standard hypotheses are eliminated, the analysis moves to the value chain. The question becomes: who controls the customer interface, and what are their incentives? In Case 7, the answer to both parts of that question changed when the distributor launched its own private-label products.
### Strategic Response: Rebuilding Channel Control and Brand Pull
The strategic response must address both conditions simultaneously: reduce structural dependency on the channel that now has conflicting incentives, and build the brand pull that provides demand-side protection against substitution in any channel. The table below evaluates each option.
The brand dilution caveat that demonstrates premium market understanding: 'For a premium brand, channel expansion is not neutral — it is a positioning decision. Owned retail done well, in high-footfall premium locations with carefully designed brand environments, reinforces the premium positioning and justifies the price premium. Owned retail done cheaply, in secondary locations with inconsistent service quality, undermines it. The recommendation is channel diversification, but the execution standard matters as much as the channel choice. A premium brand's distribution strategy is its brand strategy.'
### The 5-Step Framework
The meta-lesson that Case 7 is designed to teach — applicable to every market share decline and channel strategy case: Many performance problems are not caused by what a company does wrong — but by what its partners start doing differently. Market growth does not guarantee firm-level success. Even in expanding markets, power shifts within the value chain can quietly destroy incumbents by removing the intermediaries' incentive to sell on the incumbent's behalf. Spotting those shifts early requires looking beyond the client's internal operations to the incentive structures of every actor in the value chain. Distribution strategy is not a logistics decision. It is a strategic decision — because losing control of the customer interface means losing control of demand.

---
# Case 8 - Market Entry Strategy
Source: articles/case-strategy/case-8.mdx
#### Case 8: Toothbrush Wars — When Disruption Targets Your Most Profitable Segment
A $5 spinbrush captures 1% of the global market. That sounds small. But it does not draw from the $3 manual segment — it draws from the $12-per-year rechargeable segment. The case is not about market share. It is about profit pool erosion — and why a knockoff response accelerates the problem it was meant to solve.
Case 8 is a consumer products disruption case with a specific analytical trap: the instinctive response to a new competitor is to match it. Launch a spinbrush. Defend the market. Protect the share. In this case, that response destroys more value than the competitor does on its own. The spinbrush does not attack the high-volume, low-margin manual segment — it attacks the low-volume, high-margin rechargeable segment. A direct competitive response by the client accelerates the cannibalization of its own most profitable customer base.
The analytical reframe that unlocks this case is the shift from market share to profit per customer per year. Management stated this is how they view the business — and that hint is the key. At 1% market share, the spinbrush looks like a minor competitive irritant. Measured in annual profit per customer lost ($8 per converted rechargeable user), the threat is structurally serious before it becomes visible in the volume numbers.
The case tests whether candidates can identify the correct competitive metric, map the profit pool before drawing strategic conclusions, trace where the spinbrush draws its share from (rechargeable, not manual), and name why the knockoff response is the worst available option. These four moves, in sequence, produce a recommendation that is both analytically rigorous and strategically sound.
### The Profit Pool: Three Products, Three Different Economic Realities
The first analytical step is to map the annual profit per customer across all three product tiers. This mapping reveals the economic structure of the competitive threat — and immediately reframes the case from a market share question to a profit pool question.
The reframe that changes everything: 'The spinbrush has 1% of global market share. That sounds manageable. But 1% of what? If the spinbrush draws disproportionately from the rechargeable segment — which generates three times the annual profit per customer — then 1% of volume can represent a much larger share of profit impact. Before assessing whether the threat is serious, we need to know which customers the spinbrush is taking. That question determines everything that follows.'
#### Why This Is a Profit Threat — Not Just a Market Share Threat
### Strategic Response Options: What Helps and What Accelerates the Problem
The strategic response options for the client span a range from self-defeating to structurally sound. The table below evaluates each option against the profit pool logic established in the analysis — distinguishing responses that protect value from those that erode it.
The cannibalization logic that separates strong answers from average ones: 'If the client launches a $5 spinbrush, it defends volume share in the entry-level electric segment. But where does that spinbrush volume come from? Not from manual users — they were not going to upgrade to a $50 rechargeable anyway. It comes from customers who were deciding between spinbrush and rechargeable, and who now choose the client's spinbrush instead of the client's rechargeable. The client has successfully competed — against itself. The market share number improves. The profit per customer number falls. This is not a response to disruption; it is a subsidy of it.'
### The 5-Step Framework
The meta-lesson that Case 8 is designed to teach — applicable to every disruption case: Not all market share is worth defending. Disruption often enters at the point where the incumbent's margins are highest and its value proposition is most vulnerable to a price anchor that redefines what the category is worth. The correct response is not to match the disruptor on its terms — it is to widen the gap between the premium product and the disruptor, making the premium's price feel justified rather than vulnerable. Strategy is not about reacting faster. It is about reacting smarter, with a clear understanding of where value is actually created and where it is at risk.

---
# Case 9 - Digital Transformation
Source: articles/case-strategy/case-9.mdx
### Case 9: Newspaper Start-Up — A Fermi Problem in Disguise
No financial model. No market data. Just a delivery window, six carriers, and the question every consultant should ask first: does this plan even work in the real world? One calculation is enough to find out.
Case 9 is the shortest and most elegant case in the series — and one of the most instructive. An entrepreneur wants to distribute a printed newspaper door-to-door across Cologne, Germany, between 4:00 AM and 6:00 AM, using six carriers, each covering one square kilometre, with no external capital available. The question is not how to optimise the plan. The question is whether the plan is physically possible.
The answer is no — and a single Fermi estimation chain reveals it in four steps. Ten thousand homes per square kilometre, divided by 7,200 seconds available, equals approximately 1.4 deliveries per second. On a bicycle. Door to door. Before dawn. No additional analysis is required after that calculation. The plan fails not because it is poorly managed but because it was designed without checking whether the physical constraints allow it to exist.
The case tests three consulting skills that are distinct from the analytical skills required in most profitability or market entry cases: the ability to simplify a real-world problem into a tractable estimation, the discipline to follow the calculation chain to a clear conclusion before proposing alternatives, and the confidence to deliver a negative verdict — 'this cannot work' — as a form of value creation rather than a failure to find a solution.
### The Fermi Estimation Chain: Five Steps to the Red Flag
Fermi estimation in a consulting context is not about arriving at a precise answer. It is about determining whether the order of magnitude of a plan is viable. The chain below traces each step from the given constraints to the delivery rate conclusion — with the assumption behind each step and why it matters for the validity of the final result.
The estimation principle that makes this chain credible in the interview room: 'I am making conservative assumptions at each step — even distribution, no non-residential areas, no apartment stacking. Each of these assumptions makes the plan look more feasible than it would be in reality. If the plan fails under the most favourable assumptions, it definitely fails under realistic ones. I do not need to model real-world complexity to reach a confident conclusion.' Stating this explicitly signals that the candidate understands the direction of estimation bias — which is the mark of someone who has used Fermi estimation as a real analytical tool, not just a framework to recite.
#### Structural Levers: What Can Save the Plan — and What Cannot
Since the binding constraints are fixed — no additional capital, a defined delivery window, and a fixed carrier count — incremental improvements to execution cannot resolve the infeasibility. The only viable responses are structural changes to the plan's design. The table below evaluates each option against the hard constraints.
### Three Consulting Lessons That Case 9 Is Designed to Teach
Case 9 is short because the analytical content is concentrated in a single insight. The three lessons it delivers are each applicable far beyond logistics and distribution — they are foundational principles of how good consultants add value.
### The 5-Step Framework
The meta-lesson that Case 9 is designed to teach — applicable to every estimation and feasibility case: The fastest way to add value is often to prove that something cannot work. A consultant who delivers that conclusion clearly, quickly, and without apology — backed by a transparent calculation chain — has performed exactly the role the client needs. There is no shame in a negative verdict. The shame would be in spending three weeks building a financial model for a plan that fails a ten-minute sanity check. Fermi estimation is the tool that performs that check. Case 9 is the case that teaches you to reach for it first.

---
# Case Interview Framework - Foundation Guide
Source: articles/case-strategy/case-framework.mdx
### Acing the Case Interview: A Strategic Roadmap
Consulting case interviews are not tests of business knowledge. They are tests of structured thinking, quantitative speed, and the ability to deliver a coherent recommendation under uncertainty. This is the roadmap — from building your toolkit to executing in the room.
The consulting case interview is one of the most structured and learnable interview formats in professional hiring — and yet the failure rate among well-qualified candidates remains high. The reason is almost always the same: candidates prepare the content of case interviews without preparing the process. They memorise frameworks for profitability cases and M&A cases, practise math drills, and read case study books. Then they walk into the room and discover that the real challenge is not knowing what to say — it is executing a structured, collaborative, audible problem-solving process in real time, with an evaluator watching every decision.
The consulting recruitment process has two distinct components that evaluate different capabilities. Understanding what each component is actually measuring — and preparing for each on its own terms — is the first step toward performing well in both.
The roadmap below covers the full picture: the two-component evaluation structure, the four-element consultant's toolkit that must be developed before the interview, the four-step execution process for the case itself, and the three-stage live performance framework that turns preparation into performance in the room.
### The Two-Component Evaluation Structure
Most candidates understand that consulting interviews include a case component and a fit component. Fewer candidates understand that these two components are evaluating fundamentally different things — and that preparing for one does not prepare you for the other. The table below maps each component to its primary evaluation goal and what that means in practice for preparation and delivery.
The framing error that most case candidates make — and how to correct it: Treating the case interview as a knowledge test rather than a process test. The interviewer is not evaluating whether you know the right answer. They are evaluating whether you can structure a problem clearly, perform arithmetic transparently, form and test hypotheses in real time, and deliver a recommendation with appropriate confidence. A candidate who reaches an imperfect conclusion through a rigorous, audible process outperforms a candidate who reaches a correct conclusion through a silent, opaque one.
### Step 1 — Build Your Consulting Toolkit
The consultant's toolkit is the set of capabilities that must be developed before the interview. These are not things you can improvise in the room — they require deliberate practice over time. The four elements below correspond to the four dimensions that case interviewers evaluate, either explicitly or implicitly, throughout the case.
The toolkit element that candidates most consistently underinvest in — and that has the highest return on preparation time: Paper management. Candidates spend hours on math drills and framework memorisation, and almost no time on the physical practice of drawing structured notes under time pressure. In the room, a candidate who produces a clear Revenue-Cost-Market Dynamics diagram on paper and talks through it with the interviewer is demonstrating consulting-style thinking in real time. A candidate who thinks silently and presents conclusions verbally is making their process invisible — and invisible process cannot be scored positively.
### Step 2 — Execute the Case: The 4-Step Walkthrough
The case execution process is a repeatable four-step sequence. Knowing the sequence in advance means you do not spend mental energy in the room deciding what to do next — you know the next move before you need it. The table below describes what each step requires and the specific mistakes to avoid at each stage.
### The 3-Stage Live Performance Framework
The four execution steps describe what to do. The three-stage live performance framework describes how to do it in real time — with an evaluator in the room, a clock running, and the pressure of a genuine consequential interview. These three stages correspond to the observable behaviours that experienced interviewers score across the case.
The principle that connects every element of this roadmap — the meta-insight that distinguishes candidates who pass from those who do not: The case interview is a simulation of a client meeting. Everything you do — how you structure your notes, how you narrate your math, how you form and test hypotheses, how you deliver your recommendation — is a preview of how you will behave in front of a client. Interviewers are not scoring whether you got the right answer. They are asking themselves: 'Would I put this person in front of a client?' Candidates who prepare the toolkit, practise the process out loud, and deliver the recommendation with confidence and structure answer that question in the affirmative. That is the entire test.




---
# AI Isn't Replacing You — It's Redistributing Your Work
Source: articles/future-vision/ai-redistributing-work.mdx
Decoding Microsoft's 'Working with AI' report: a strategic guide to AI delegation and occupational shifts in 2026.
By Carrie Yu · HéraAI · March 11, 2026
For years, the conversation around AI and employment has been dominated by speculative doom-and-gloom. A new report from Microsoft changes that. By analyzing over 200,000 anonymized conversations with Microsoft Copilot, researchers have mapped — with real-world data — exactly where AI is already doing the heavy lifting. If you're currently in the workforce or entering the 2026 job market, this data is your new North Star. Here's what it actually says.
{/* Stats Cards */}
200,000+
real Copilot conversations analyzed
#1
most impacted sector: Media & Communications
0
roles that are fully "AI-proof"
{/* Image */}
1. The Information Life Cycle Is Ground Zero
The report's most significant finding is that AI applicability isn't uniform — it concentrates almost entirely on information work: the creation, processing, and communication of data. The occupations sitting at the top of the AI applicability scale are those most deeply embedded in that cycle.
Most Impacted Roles
- Media & Communications
- Sales Representatives
- Information & Records Clerks
- Business & Financial Operations
Least Impacted Roles
- Physical labor & manual trades
- Hands-on care & healthcare support
- Heavy machinery operation
- Roles requiring constant physical presence
The pattern is clear: the further a role is from a screen, the lower its AI applicability score. The closer it is to producing, managing, or communicating information, the higher the exposure.
Key takeaway: AI applicability is not random. It follows the information supply chain. Understanding where your role sits on that chain is the first step in building a future-proof career strategy.
2. The Great Task Split: Delegation vs. Collaboration
One of the most practically useful insights in the report is the distinction between two modes of AI integration — and they have very different implications for how you should think about your career.
The Delegation Zone
Who's here:
Media, business, and financial operations roles.
What's happening:
AI is moving from a tool to a service provider. Core tasks — compiling records, writing commercial copy, answering customer inquiries, preparing training materials — are being handed off entirely.
Your new role: reviewer, editor, and decision-maker. Not executor.
The Collaboration Zone
Who's here:
Computer science, mathematics, architecture, and engineering roles.
What's happening:
Humans remain firmly in the loop. AI accelerates existing workflows rather than replacing them — a powerful amplifier, not a substitute.
Your new role: the same, but faster and higher-leverage.
The insight that matters: knowing which zone your role occupies changes everything about your career strategy. Delegation Zone workers need to move up the value chain — fast. Collaboration Zone workers need to master AI acceleration before someone else does.
3. Specific Tasks Being Handed to AI Right Now
The report doesn't just identify industries — it maps the specific task types that are seeing the highest AI delegation rates. These are called Information Work Activities (IWAs), and they are already shifting. These aren't future predictions. Microsoft's dataset confirms they are happening now, at scale, across major enterprises.
High-Delegation Task Categories (IWAs)
Writing & Editing
Commercial copy, document editing, drafting correspondence.
Information Dissemination
Responding to inquiries, presenting data, customer-facing communication.
Teaching & Explaining
Translating technical details, policies, and regulations into plain language.
Knowledge Maintenance
Gathering, synthesizing, and summarizing information from multiple sources.
4. Three Things That Will Actually Matter in the 2026 Job Market
The data from this report translates into three concrete strategic priorities for anyone building or pivoting their career right now.
1
The 'Connecting Glue' Skill
As AI democratizes information work, the most durable asset becomes cross-task judgment: the ability to connect dots across domains, read a room, and build relationships. AI can produce the output. It cannot own the relationship or make the call in a non-routine situation. That gap is where your premium lives.
2
Foundational Domain Expertise
The report flags a crucial catch: AI can shrink the performance gap between low- and high-skilled workers — but only if the human evaluating the output has the expertise to know when AI is right and when it's wrong. In 2026, 'AI literacy' isn't about prompting. It's about having enough domain knowledge to be a credible judge of AI output. Without that, you're not working with AI — you're just forwarding its mistakes.
3
The Task Refactoring Mindset
Entirely new occupations are emerging, and existing ones are being restructured around what humans and machines each do best. Even physical roles — food service, healthcare support — are seeing AI enter through their administrative and informational components. No role is AI-proof. Almost every role is AI-enhanceable. The competitive skill is learning to split your work deliberately: what to delegate, what to automate, and what to own.
The HéraAI bottom line: Don't just learn to do the work. Learn to direct the AI that does the work.
The Frontier Has Moved. Have You?
Microsoft's report confirms what the most forward-thinking career strategists have been saying: AI is becoming a general-purpose technology, comparable in scale to the internet or the steam engine. Its effects won't be uniform, and they won't all arrive at once.
For current employees, the priority is identifying which parts of your information lifecycle can be safely delegated — so you can redirect that time toward the creative, interpersonal, and judgment-intensive work that AI cannot replicate.
For the class of 2026, the message is direct: the workers who will thrive aren't the ones who know how to use AI. They're the ones who know how to think alongside it. At HéraAI, that's exactly the transition we help people navigate.
Note: Insights are based on Microsoft Copilot usage data from late 2024 through 2025, as reported in 'Working with AI: Measuring the Applicability of Generative AI to Occupations.'
---
# Machine Learning Engineer Career Analysis 2026
Source: articles/future-vision/ml-engineer-career-analysis-2026.mdx
#### The Modern ML Engineer: 2026 Market Analysis, Skill Blueprint, and Career Pivot Guide (part 1)
Based on analysis of 10,000+ job postings. Median US salary: $187,500. Senior ceiling: $350,000+. Here's what the market actually requires.
Machine Learning Engineering has become the most critical — and most compensated — bridge role in enterprise technology. As AI moves from research labs into production infrastructure, organisations no longer just need people who can train models. They need engineers who can deploy them, monitor them, scale them, and keep them running at 24/7 reliability.
This article covers two interconnected topics: the full state of the ML Engineer market in 2026, and the specific roadmap for Data Analysts looking to make the transition. Both are grounded in analysis of over 10,000 current job postings and the latest North American compensation data.
#### 1. What ML Engineers Actually Do — And Why It's Different from Data Science
The most important distinction in the current market is between Data Scientists and ML Engineers. Both work with machine learning — but they operate at opposite ends of the production spectrum.
Data Scientists focus on exploration: they analyse data, test hypotheses, and build models in controlled environments. ML Engineers are responsible for what happens next — taking those models into production, ensuring they perform reliably at scale, and building the infrastructure that keeps them running. The shift from 'model accuracy' to 'model reliability' is the defining characteristic of the ML Engineer role.
That production focus is exactly what's driving the demand surge. Organisations that invested in AI research capability over the past five years are now trying to convert that capability into working systems. The bottleneck isn't ideas — it's engineers who can build and maintain the infrastructure that makes ideas deployable.
The market signal: 21% of current ML Engineer job postings specifically cite 'cross-functional communication' and 'business translation' as required skills — not preferred. Companies aren't just buying technical capability. They're buying the ability to connect that capability to organisational outcomes.
### 2. The Seniority Spectrum: Responsibilities, Market Share, and Compensation
The current ML Engineer market has a distinct structural shape. Mid-level roles account for 78% of all postings — reflecting an industry that has moved past initial experimentation and is now scaling production systems. Junior roles focus on implementation; senior roles focus on vision and team-building; the bulk of the market is in the middle, where the real architectural work happens.
The mid-level opportunity: The 78% concentration of postings at the mid-level is not just a market stat — it's a strategic signal. Candidates who can demonstrate end-to-end ownership of an ML system (from design through production monitoring) are entering the most active and best-compensated hiring segment in the current market.
### 3. The Complete Skill Stack for 2026
The skill requirements for ML Engineers in 2026 reflect a fundamental shift in what 'production AI' means. The baseline (Python, ML frameworks) is now assumed. The differentiators are MLOps fluency, GenAI stack experience, and the communication capability to translate system performance into business language.
The GenAI column deserves specific attention. LLMs, RAG architectures, and prompt engineering were considered specialist skills 18 months ago. In current job postings, they appear as core requirements — not enhancements — at both mid and senior levels. Candidates without this stack are increasingly screened out at the first filter.
The MLOps imperative: Docker, Kubernetes, and SageMaker are no longer 'nice to have.' They are the production infrastructure that every deployed ML system runs on. An engineer who can build a model but can't containerise, deploy, and monitor it in a live environment is not a production ML engineer — they're a research engineer. The market is paying for the former.
#### 4. North American Compensation: US vs. Canada, Level by Level
The compensation data confirms ML Engineering's position at the top of the technology labour market. US ML Engineers are in the top 4% of earners nationally. The Canada market is structurally similar but compensates at approximately 60–65% of US levels in nominal terms — though purchasing power parity and quality of life calculations shift that comparison significantly in certain markets.
Geographic concentration is significant. In the US, California (32%) and New York (11%) account for 43% of all postings — and the highest compensation bands. In Canada, Toronto, Vancouver, and Montreal represent 62% of the country's AI talent market. Remote-eligible roles remain available, particularly at mid and senior levels in Software, Finance, and Insurance sectors.

---
# NLP Blueprint - Future Applications
Source: articles/future-vision/nlp-blueprint-future.mdx
#### CAREER PIVOT NAVIGATOR · NLP Engineering · 2026 Hiring Cycle
#### The NLP Gold Rush: 5 Truths About the 2026 Job Market Every Candidate Needs to Know
The global NLP market is projected to surpass $201 billion by 2031. The opportunity isn't scarce — the talent to seize it is.
The AI boom has created a landscape defined by equal parts immense opportunity and real confusion. While 'AI' has become a corporate buzzword, the most lucrative and stable career opportunities are concentrating within a specific discipline: Natural Language Processing.
NLP is the engine behind the Generative AI revolution — the technology allowing machines to grasp, interpret, and generate human language. And right now, the market is desperately short on people who can build it well.
Surviving the 2026 hiring cycle requires more than a certificate. It requires a strategic understanding of how the technical and economic pieces actually fit together. Here are five truths that will change how you approach this market.
#### 1. The 'Junior' Label Is a Misnomer — And the Salary Floor Reflects That
One of the most persistent myths in tech hiring is that 'Junior' roles in AI are low-paying entry points. In the NLP world, that label describes what is, in practice, a high-impact engineering role with a salary floor most industries reserve for senior staff.
The reason the floor is this high comes down to one thing: human ambiguity. Even a baseline NLP role requires the ability to teach machines to parse the messiness of human intent — sarcasm, context shifts, cultural inference, contradictory phrasing. That's not a skill that scales easily.
What this means for you: These figures aren't just attractive compensation data — they reflect genuine talent scarcity. Companies are paying this much because they can't find enough people who can bridge computational linguistics and deep learning. That gap is your leverage.
#### 2. Linguistic Intuition Is the Differentiator That Separates Good Candidates from Hired Ones
Thousands of candidates can list PyTorch and TensorFlow on their resume. Far fewer can explain why a model fails to handle sarcasm — or what it would take to fix it.
That distinction is linguistic intuition: the ability to reason about the gap between what a model processes and what a human actually means. It's not a soft skill. It's a technical design capability.
The most effective NLP engineers understand the structural difference between syntax (how language is arranged) and semantics (what it actually means). That understanding directly shapes model architecture decisions — which training signals to weight, which evaluation metrics to trust, and where the model is likely to fail silently.
Interview signal: When asked about model limitations, don't just describe the technical failure. Explain the linguistic phenomenon behind it. That's the answer that gets offers.
#### 3. Bias Mitigation Is Now a Hard Engineering Skill — Not an Ethics Elective
The industry has moved from 'pure tech' to 'responsible tech.' In the 2026 hiring landscape, if you can't speak concretely to bias mitigation, you're a liability — particularly for roles in hiring, law enforcement, healthcare, and customer service, where biased model outputs carry legal and operational consequences.
The framing shift that matters: stop treating debiasing as an ethical consideration and start treating it as a technical requirement embedded in your engineering pipeline.
The hiring reality: Senior hiring managers increasingly treat bias mitigation fluency as a minimum bar, not a bonus. Candidates who can walk through a concrete debiasing pipeline — with specific tools and metrics — stand out immediately.
#### 4. Transformer Architecture Is the Baseline — Know It Beyond the Buzzwords
The 2026 interview room has moved past recurrent neural networks. The baseline expectation is a genuine understanding of the Transformer architecture: not just that it works, but why it outperforms earlier approaches and what its actual limitations are.
The key insight: Transformers solved the long-range dependency problem that made RNNs unreliable for complex language tasks. The self-attention mechanism allows the model to evaluate all tokens in a sequence simultaneously, rather than processing them sequentially and losing context over distance.
#### 5. Portfolios Are the New Resume — Build Projects That Prove Production Readiness
Theoretical knowledge is a commodity. In 2026, what separates shortlisted candidates from the rest is demonstrated ability to build systems that handle real-world messiness — not clean benchmark datasets.
The rise of Shadow AI (employees using AI tools outside official IT channels) and AI Democratization means hiring managers are increasingly evaluating whether you can build the tools others are already using. Your portfolio is where you prove that.
The portfolio principle: Every project you include should answer one question for the hiring manager: 'Can this person handle the failures that don't appear in documentation?' Show the edge cases you solved, not just the pipelines you built.
#### The Future Belongs to Engineers Who Ensure AI Truly Understands Language
As AI Democratization accelerates, the number of people who can use the tools will grow rapidly. The number who can ensure those tools are accurate, ethical, and genuinely language-aware will remain scarce.
The engineers who define this next phase won't just generate text. They'll be part linguist, part engineer, part strategist — capable of navigating the boundary between what a model outputs and what a user actually needs.
The field is moving toward multilingual embeddings, complex discourse analysis, and real-time adaptive systems. The candidates who thrive will be the ones who understand not just how these systems work, but why they sometimes don't — and what it takes to fix them.
At HéraAI, that's the level of strategic clarity we help engineers develop.
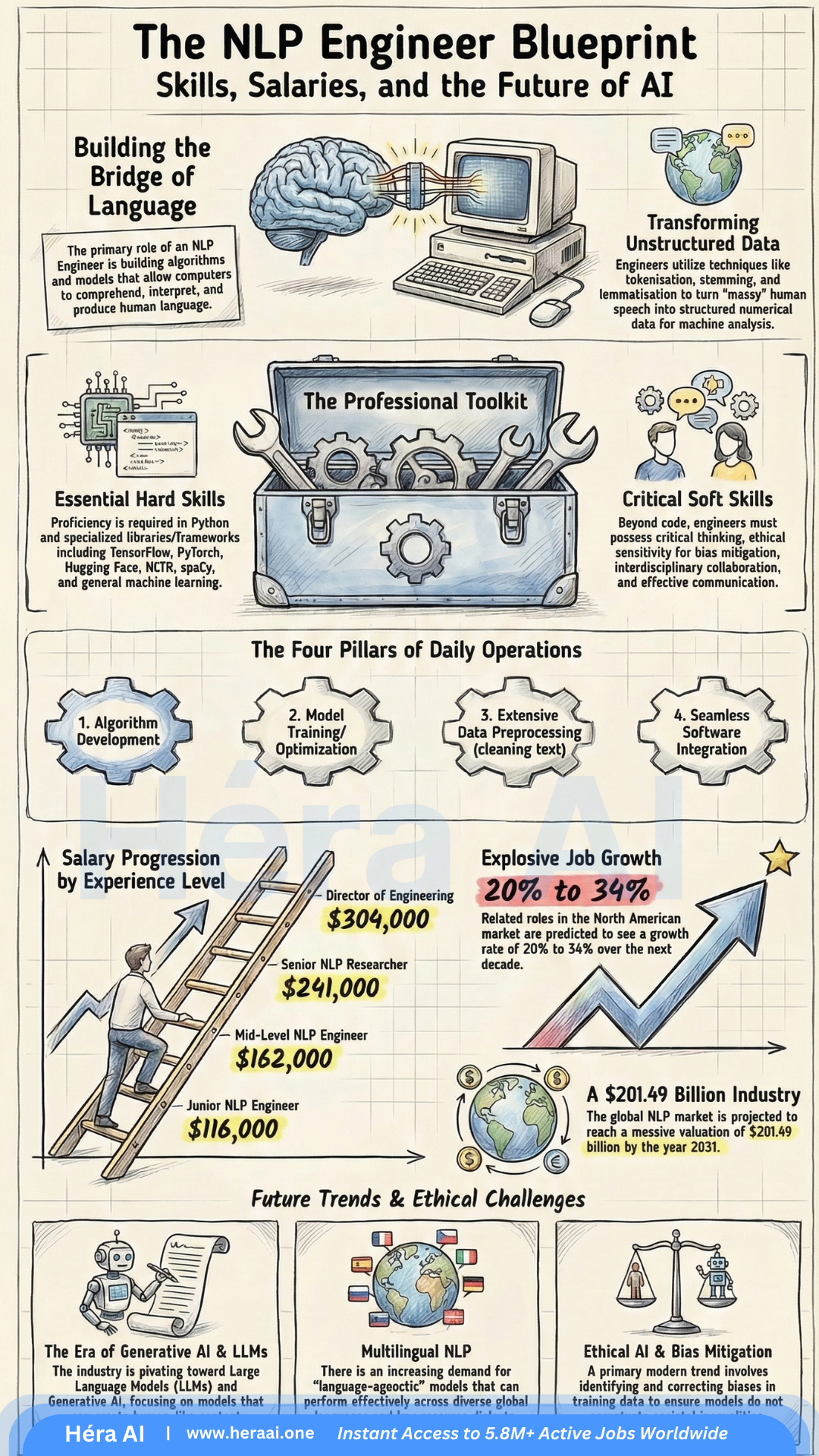
---
# ByteDance Data Analyst Interview Series 1
Source: articles/interview-vault/bytedance-da-interview-series-1.mdx
#### ByteDance DA Interview, Day 1: Why 90% of Candidates Fail with Correct SQL Queries
The real ByteDance SQL screen doesn't test syntax — it tests whether you think like a product owner. Here are the five traps that eliminate technically correct candidates.
If you're preparing for a Data Analyst role at ByteDance or TikTok, the foundational SQL questions are your baseline. But at petabyte scale with real-time business logic, a technically correct query that ignores product context is a failing grade — and the interviewers are specifically designed to surface that gap.
At ByteDance, data is not a reporting function. It's a decision engine. The analysts who advance to offer stage are not the ones with the cleanest syntax — they're the ones who ask the right clarifying questions before writing a line of code, who understand why a specific JOIN choice corrupts a retention metric, and who can explain the computational cost of a self-join on a table with 10 billion rows.
This article breaks down five SQL concepts that appear in ByteDance DA screens and maps the gap between the surface-level answer and the senior-level one. Each section covers what most candidates say, what the interviewer is actually probing, and what the top 1% of candidates demonstrate instead.
### The Five Traps at a Glance
The table below maps each SQL concept to the hidden trap it contains and the response pattern that signals senior-level thinking. Use it as a preparation checklist — for each concept, the question to answer is not 'do I know this' but 'can I explain the business implication under follow-up pressure?'
The meta-signal ByteDance interviewers are looking for: The difference between a junior and a senior data analyst is not the code they write — it's the mistakes they anticipate before writing it. Every senior response begins with a clarifying question or a denominator definition. That instinct, more than any technical skill, is what the interview is designed to detect.
### Trap 01 — The JOIN Bias: Accuracy vs. Truth
The most commonly cited SQL concept in retention analysis is JOIN type. Most candidates know the difference between INNER and LEFT JOIN in mechanical terms. Fewer understand what happens to a metric's validity when the wrong JOIN type is selected — and at ByteDance, metric validity is the entire job.
The specific trap: calculating Day-1 Retention using INNER JOIN between a user registration table and an activity table. An INNER JOIN returns only rows that match in both tables — which means every user who registered but never performed the defined activity is automatically excluded. The denominator shrinks. Retention appears higher than it is.
The retention figure in the LEFT JOIN query is not lower because ByteDance has a worse product — it's lower because it's accurate. The INNER JOIN figure is not wrong because of a syntax error; it's wrong because of a metric design error. That distinction is exactly what the follow-up question is designed to expose.
HéraAI interview technique: In a ByteDance interview, before writing any retention query, state your denominator explicitly: 'I'll use LEFT JOIN to preserve the full registered cohort in the denominator. I'm assuming we want to measure what percentage of all registered users returned — not just the subset who were already active. Can you confirm?' This single question signals product ownership.
### Trap 02 — Window Functions: The Senior Signal
Window functions are standard SQL knowledge. The ByteDance DA screen uses them to test something more specific: whether you understand the computational cost difference between a window function and a self-joined subquery — and whether you can articulate the edge cases that determine which ranking function to use in a business context.
The setup: 'Find the top 3 creators by view count in each content category.' The junior answer produces a correlated subquery with a self-join that scans the table multiple times. The senior answer uses a window function in a single pass — and names the specific function based on the tie-handling requirement.
The DENSE_RANK() vs. RANK() distinction is not academic in this context. ByteDance's Creator Fund distributes incentive payments based on creator rank tiers. If two creators tie for rank 2 and RANK() is used, rank 3 is skipped — meaning a creator who would qualify for Tier 3 incentives under a continuous ranking system loses out due to a SQL function choice. Demonstrating awareness of this edge case is the fastest way to signal production experience.
The performance signal that closes the conversation: After presenting the window function solution, add: 'At ByteDance's data volume, a self-join on the creator activity table would require scanning billions of rows twice. A window function processes the data in a single pass. The performance difference at this scale could mean the difference between a query that runs in 30 seconds and one that times out.' This frames a technical choice as an infrastructure cost decision.
### Trap 03 — SQL Execution Order: The Debugging Superpower
SQL execution order is taught in every introductory course. At ByteDance, it's used as a senior filter because knowing the order conceptually is different from being able to debug a production error by tracing the order mentally — without running the query.
The most common trap: filtering on an aggregated metric in a WHERE clause. WHERE runs before GROUP BY and SELECT, which means aggregate functions don't exist yet when WHERE is evaluated. Using AVG(engagement_score) > 80 in a WHERE clause produces a syntax error in standard SQL. The correct clause is HAVING — which runs after GROUP BY, when aggregate results are available.
The engine-specific nuance that separates candidates: whether SELECT aliases are available in ORDER BY depends on the SQL engine. In BigQuery and Presto (common at ByteDance), aliases defined in SELECT are available in ORDER BY. In standard SQL and some strict engines, they are not. Mentioning the specific engine — and demonstrating awareness that behavior varies — signals that you've actually spent time in a production query environment.
The debugging framing that impresses interviewers: When asked to optimize or debug a query, say: 'Let me trace the execution order. FROM loads the data, WHERE filters individual rows — so I can't use an aggregate here, that needs to go in HAVING — GROUP BY creates the aggregation buckets, HAVING filters on the aggregated result, then SELECT evaluates...' Walking through the order out loud demonstrates the production debugging instinct that senior DA roles require.
### Trap 04 — The Retention Formula: It's Strategy, Not Arithmetic
The retention formula is conceptually simple: returning users divided by total users from the cohort. The ByteDance interview uses it to test something entirely different — whether you understand the business decisions embedded in every component of that formula, and whether you know what happens to the metric when those decisions change.
Three dimensions define the formula's validity. Each one is a clarifying question you must raise before writing the query — and each one has a specific implication at global product scale.
The timezone dimension is the one that most directly distinguishes candidates with global product experience. ByteDance operates across every major timezone. A user in Seoul who registers at 11:30pm local time registers at 14:30 UTC the same day. If your Day-1 window is defined as the next calendar UTC day, this user's 'Day 1' begins in 30 minutes — making any activity in the next 24 hours fall outside the Day-1 window in your query, even though it's genuinely Day-1 behaviour.
The fastest path to a 'Strong Hire' rating: Mention timezone normalization unprompted. Most candidates never raise it. The moment you say 'I'd want to confirm whether we're normalizing UTC to the user's local timezone for the day boundary calculation — this can shift retention figures by 10-15% for global cohorts' you have demonstrated a level of metric engineering awareness that the majority of candidates at every level do not.
#### Trap 05 — 3NF and Data Types: Where Theory Meets Infrastructure Cost
Third Normal Form and data type selection are the SQL concepts most candidates treat as textbook theory. At ByteDance, they're asked to assess whether you understand data engineering collaboration and infrastructure economics — two dimensions that matter significantly for a senior DA who works at the intersection of product and data platform.
### SQL Is the Language. Business Judgment Is the Message.
The five traps in this article share a common structure: each one has a technically correct answer that fails the interview, and a strategically correct answer that passes it. The difference is not SQL knowledge — it is the instinct to ask what a query is actually measuring before deciding how to write it.
At ByteDance, data analysts are not query writers. They are product decision partners who happen to use SQL as their primary tool. The interview is designed to determine whether you approach a metric as a coder — asking 'how do I calculate this?' — or as a product owner — asking 'what exactly are we measuring, why does it matter, and what could make this number misleading?'
This article is Part 1 of HéraAI's ByteDance DA Interview Series. Part 2 covers Statistics and A/B Testing — including why p < 0.05 is not always a win, how ByteDance applies Bayesian thinking in experiment design, and why the 'average user' is a distribution trap that eliminates senior candidates who don't see it coming.
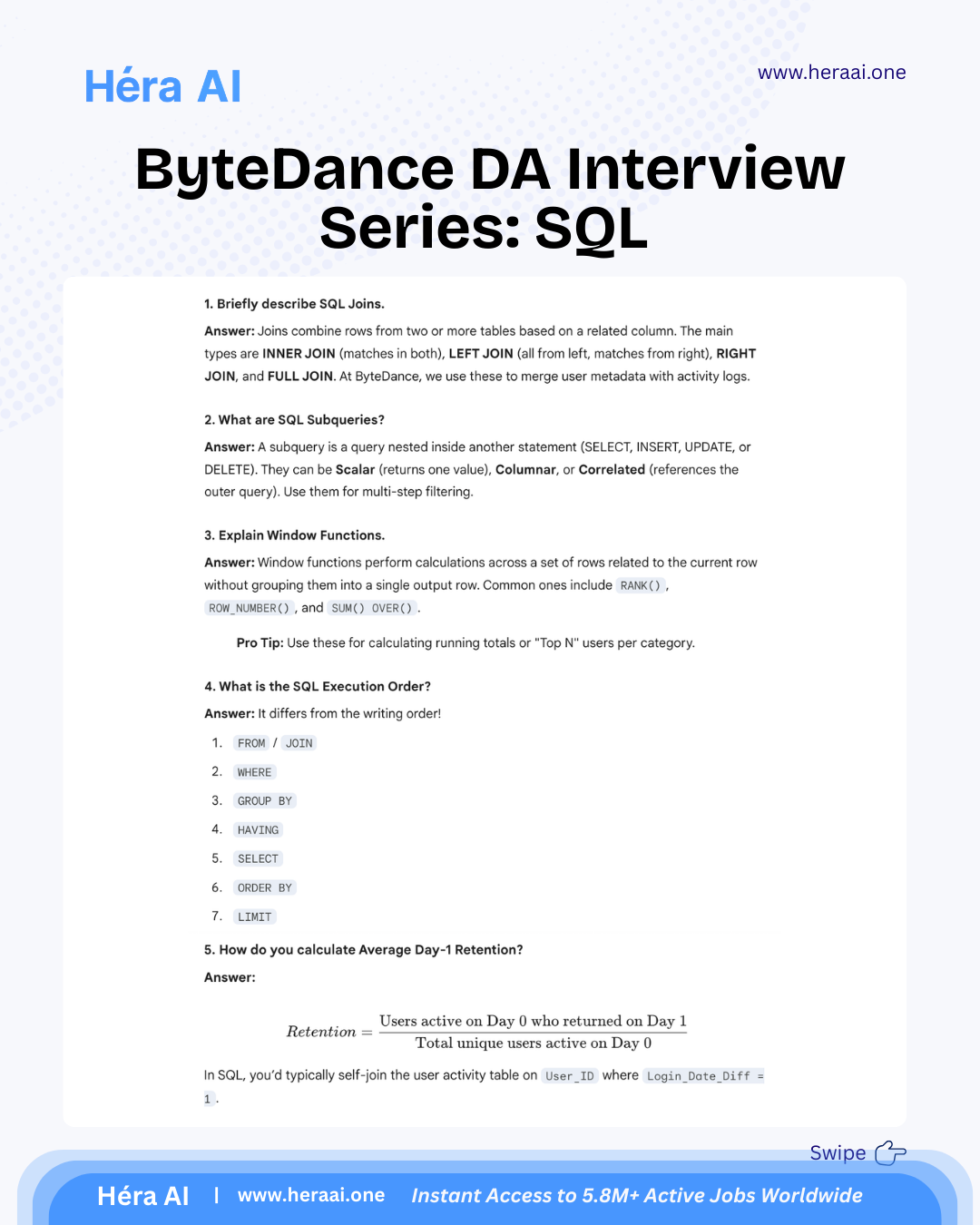
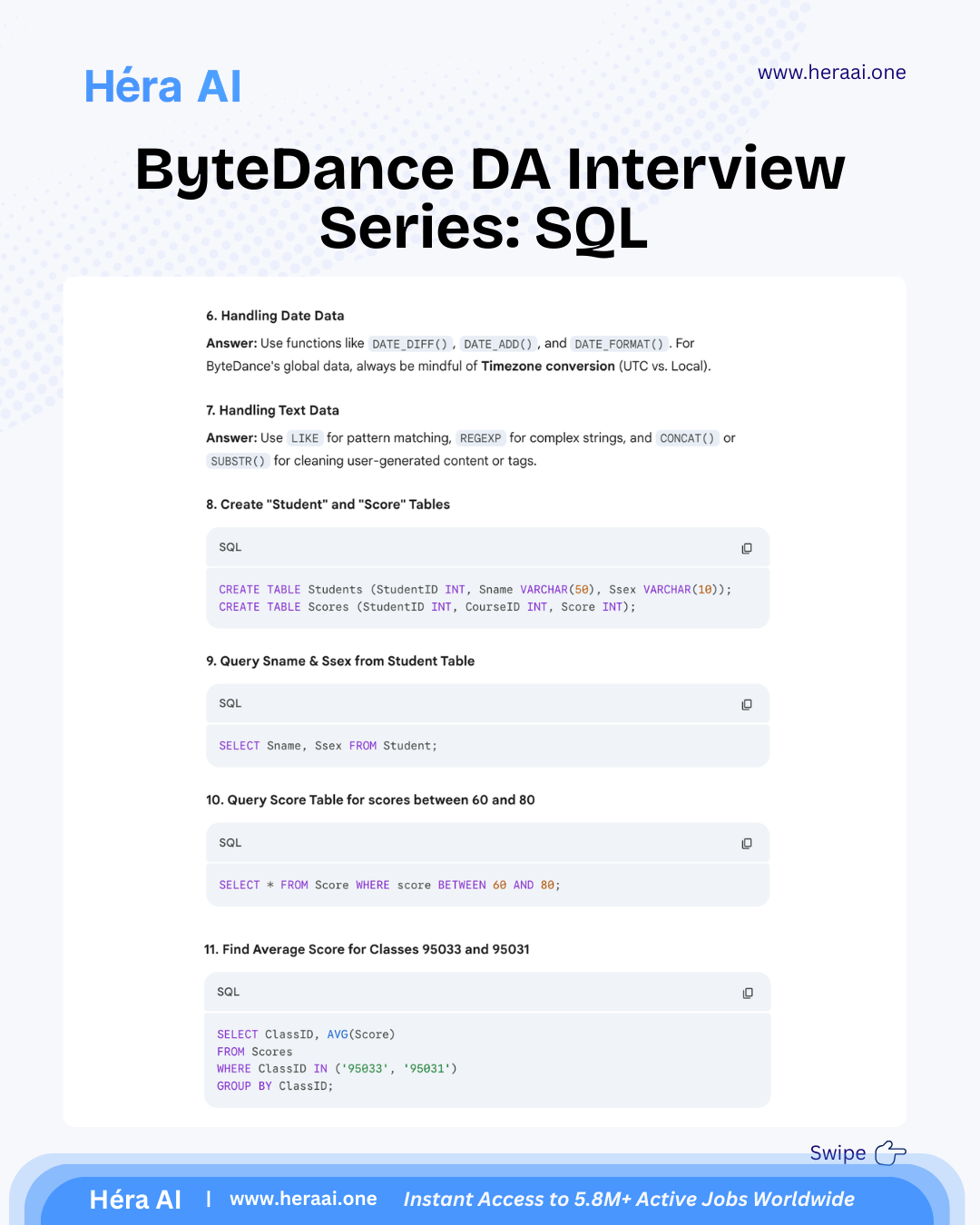
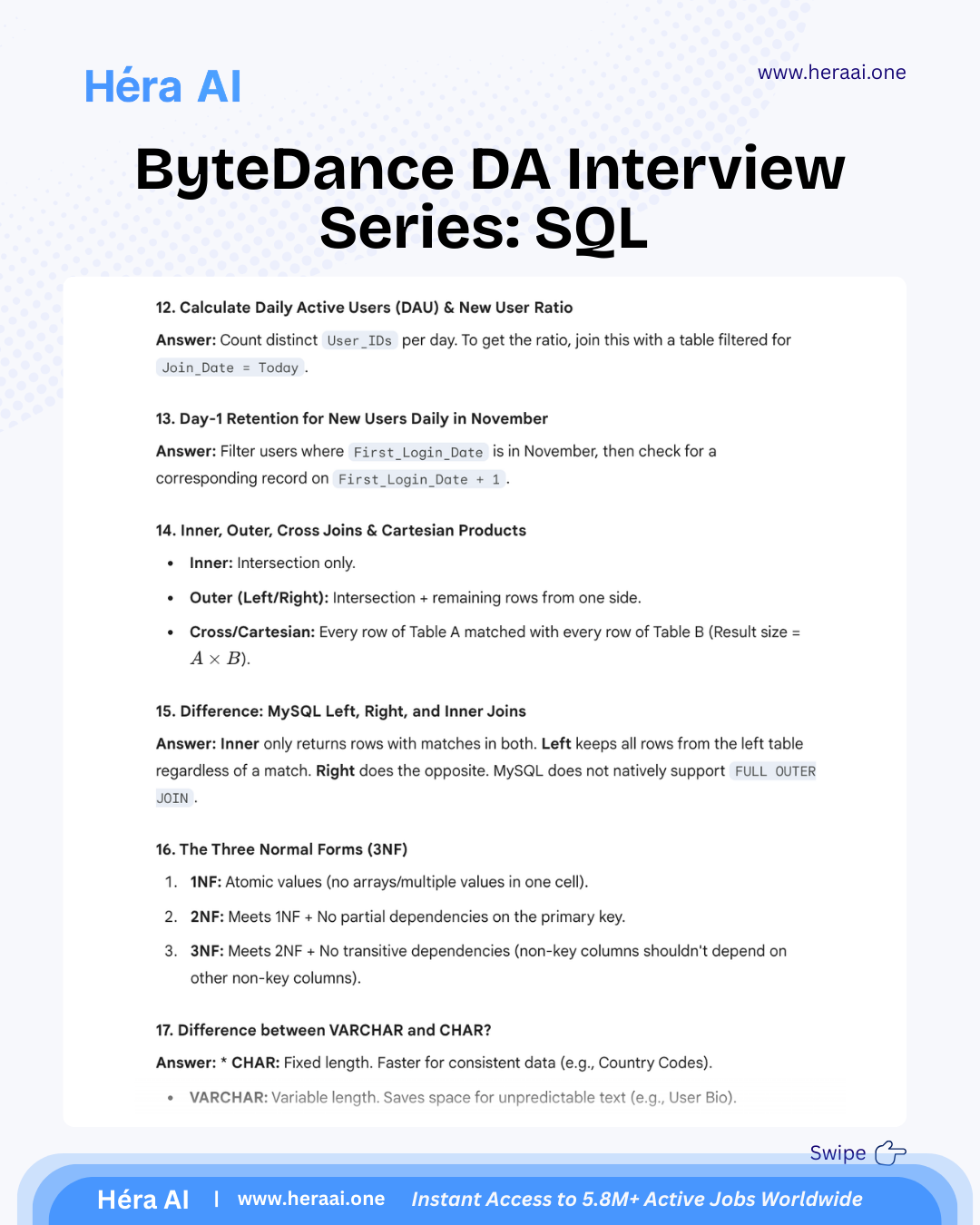
---
# ByteDance Data Analyst Interview Series 2 - Statistics
Source: articles/interview-vault/bytedance-da-interview-series-2.mdx
### ByteDance Statistics Interview: Why Most Analysts Misinterpret A/B Tests
At TikTok's scale, almost every test is statistically significant. The real question — the one that decides the offer — is whether the result is practically meaningful.
Day 1 of the ByteDance DA series covered the SQL traps that eliminate 90% of candidates before the statistics round begins. Day 2 is where the remaining candidates get separated. The statistical concepts themselves are not advanced — p-values, confidence intervals, and the central limit theorem are standard curriculum. What separates a ByteDance hire from a ByteDance reject is precision in applying these concepts to the specific data environment of a platform with hundreds of millions of daily active users, viral content distributions, and product decisions that cost millions of dollars to reverse.
At TikTok's scale, almost every A/B test will reach statistical significance. The sample sizes are enormous. A feature that improves average watch time by 0.0001 seconds will produce a p-value well below 0.05. A candidate who presents that finding as 'the feature is a success' has answered the wrong question. The interview is testing whether you can ask the right question: Is the effect large enough to justify shipping?
This is Day 2 of HéraAI's ByteDance DA Interview Series. Here are the five statistical concepts that appear most frequently, the five A/B testing traps that eliminate otherwise-qualified candidates, and the precision distinctions that signal senior-level analytical thinking.
### The Five Concepts — What ByteDance Is Actually Testing
The five statistical areas below are not being tested in isolation. Each one is a proxy for a specific analytical judgment that ByteDance DAs exercise daily. The table maps each concept to the business question it answers and what the interviewer is actually probing for.
The framing shift that defines a senior candidate: ByteDance interviewers are not testing your ability to recall statistical definitions. They are testing your ability to translate statistical logic into product risk. The difference between a junior and senior answer to any statistics question is: the junior answers the math, the senior answers the business cost of getting the math wrong.
#### The A/B Testing Trap Table: Five Mistakes That Signal Junior Thinking
The five traps below are not obscure edge cases. They appear in the majority of ByteDance DA statistics interviews and account for a disproportionate share of candidate rejections at the statistics stage. Each one has a surface-level correct response that is actually wrong in the ByteDance context.
The statistical power trap deserves special attention because it is the one most candidates never raise proactively. Statistical power is the probability of correctly detecting a real effect. An experiment designed with insufficient power — too small a sample, too short a duration — risks a Type II error: concluding no effect exists when it actually does. At ByteDance, where product decisions are made on the basis of experimentation results, a false null conclusion can lead to discarding a genuinely valuable feature. Raising this before the interviewer asks shows you think about experiment design, not just experiment interpretation.
The Mann-Whitney signal — why it works as a senior filter: Most candidates default to t-tests because that is what statistics courses teach. ByteDance interviewers know that TikTok engagement data is not normally distributed — it is severely right-skewed by viral content. A candidate who says 'given the outlier structure of TikTok engagement data, I would use the Mann-Whitney U Test rather than a t-test because it compares distributions by rank rather than mean, making it robust to the viral outlier problem' has demonstrated three things simultaneously: statistical knowledge, platform understanding, and practical judgment. That combination is rare enough to be a strong hire signal.
### Precision Distinctions: The Concept Pairs That Interviewers Probe
The questions below are frequently used to separate candidates who understand statistical concepts from candidates who have memorised definitions. The correct answer to each requires not just the distinction but the business context in which the distinction matters.
The time series decomposition row is frequently underweighted by candidates who focus entirely on A/B testing. ByteDance DA roles are not only about experiment analysis — they involve ongoing metric monitoring, anomaly detection, and attribution of metric movements to specific causes. A DA who cannot separate a weekend seasonality spike from a product-driven trend change will produce incorrect feature attribution and flawed roadmap recommendations. The decomposition framework — trend, seasonality, residual — is the analytical tool that prevents this error.
### Explain Normal Distribution to a Five-Year-Old — Interview Question 13
This question appears deceptively simple. It is not. ByteDance asks it because the ability to explain statistical concepts to non-technical audiences is a core job requirement for a DA embedded in a product or growth team. A DA who can only speak to other statisticians cannot influence product decisions, cannot defend their analysis in design reviews, and cannot communicate experiment results to the PMs and engineering leads who will act on them.
The correct approach is to prepare three versions of the explanation — one for each type of audience — and to know which version to deploy based on who is in the room.
Why communication range is the hidden filter in the statistics interview: ByteDance hires DAs who will sit in product reviews and growth meetings with mixed audiences. The ability to adjust statistical communication to the listener — not just the ability to compute correct answers — is what enables a DA to actually influence decisions. A technically perfect analysis that the PM cannot understand does not change the product roadmap. Question 13 is testing influence capability disguised as a statistics question.
### Series Comparison: Day 1 SQL vs. Day 2 Statistics
The ByteDance DA interview series builds a cumulative profile of what the hiring team is actually evaluating across the two technical rounds. Day 1 establishes whether you can extract and structure data correctly. Day 2 establishes whether you can reason about what the data means and whether it is telling the truth.
The principle that connects D1 and D2 — and defines the ByteDance DA standard: SQL is how you extract data. Statistics is how you prevent that data from lying to you. A DA who writes perfect SQL but misinterprets the resulting A/B test has done the easy part right and the important part wrong. ByteDance's interview sequence is designed to test both layers because the job requires both: technical precision in data extraction and analytical judgment in data interpretation. The candidates who pass both rounds are the ones who treat every query as a hypothesis and every result as a claim that needs to be validated before it reaches a product decision.
### Explore the HéraAI Content Hub
ByteDance DA interview series, SQL cheatsheets, Python references, statistics frameworks — the complete Interview Cheatsheet Vault.


---
# ByteDance Data Analyst Interview Series 3 - Excel
Source: articles/interview-vault/bytedance-da-interview-series-3.mdx
### ByteDance Excel Masterclass: Why Efficiency Is the Ultimate Interview Metric
At ByteDance, the Excel interview is not about whether you can use a Pivot Table. It is about whether you build systems that eliminate work — or whether you just complete tasks faster.
Day 1 of the ByteDance DA series covered SQL — the extraction layer. Day 2 covered statistics — the validation layer. Day 3 moves to Excel, and the framing shift is immediate: this is not a test of formula knowledge. It is a test of whether you think at the task level or the systems level.
In a high-intensity environment like ByteDance, time is the scarcest resource. The Excel portion of the DA interview is designed to surface candidates who have internalised the automation mindset — who reach for batch processing, Power Query, and dynamic references not because they were told to, but because they instinctively reframe every repetitive task as a system to be built once and eliminated forever.
A candidate who knows how to create a folder manually has passed a task. A candidate who answers the same question by concatenating Excel formulas into a .bat file that creates 500 folders in 10 seconds has demonstrated the systems thinking that ByteDance explicitly values in senior DA profiles. The technical skill is a proxy for the mindset. That is what Day 3 is testing.
### The Three Mastery Levels — Where ByteDance Sets the Bar
The ByteDance Excel interview is structured around three implicit proficiency tiers. Most candidates arrive at Level 1 or Level 2. The interview is designed to find candidates who operate at Level 3 — not because Level 3 requires the most difficult formulas, but because it requires a fundamentally different orientation toward the tool.
The distinction that the interview is designed to surface: Level 1 and Level 2 candidates solve problems. Level 3 candidates eliminate categories of problems. When asked how they would generate 1,000 personalised sales statements, a Level 2 candidate describes an efficient manual process. A Level 3 candidate describes Mail Merge or a Python script — a single build that makes the question permanently irrelevant. ByteDance is hiring Level 3 thinkers and using Excel questions to find them.
### Power Query: The Replacement for VLOOKUP at Scale
The single clearest signal of a Level 2-to-3 transition in Excel competency is the shift from VLOOKUP to Power Query. VLOOKUP is fragile — it breaks when columns are inserted, fails on approximate matches in large datasets, and requires manual re-execution when source data changes. Power Query is a transformation engine that maintains a reproducible, refreshable pipeline from source data to output table.
ByteDance interviewers test Power Query not because it is technically impressive, but because it represents a data pipeline mindset — the understanding that data transformation is a repeatable process to be architected, not a one-time manipulation to be performed. The four operations below are the ones most frequently appearing in the Day 3 interview.
The unpivot signal and why it matters beyond Excel: When a ByteDance interviewer asks you to analyse a wide-format table with dates as column headers, the correct response is Power Query Unpivot — not a manual transpose, not a series of VLOOKUP references to each column individually. The unpivot answer demonstrates two things: that you know the long-format data structure that downstream tools require, and that you reach for a transformation engine rather than a formula workaround. It signals that you think about data in terms of pipelines and schemas, which is exactly the mental model ByteDance DAs need when working between raw data exports and BI layers.
### String Manipulation: Cleaning TikTok Data at Row Scale
User-generated data from a platform like TikTok arrives messy: hashtags with inconsistent capitalisation, content IDs structured as delimited strings, device identifiers embedded in URL parameters. The string manipulation techniques below are tested because they represent the real data cleaning work that ByteDance DAs perform — not because the formulas are inherently advanced.
The key distinction the interview is probing: do you know which tool to use for which data condition, and can you compose functions dynamically rather than applying fixed-length extractions that break when the data structure changes?
The formula composition principle that separates Level 2 from Level 3: A Level 2 candidate extracts the first 8 characters of a string because that is where the relevant data always appears in the sample data. A Level 3 candidate writes =LEFT(A2, SEARCH("-", A2)-1) because they know the sample data structure may not hold for all 10,000 rows — and they build the formula to adapt to the actual delimiter rather than the assumed position. Dynamic composition that references structure rather than position is the characteristic that makes string formulas robust at scale.
### The Automation Mindset: Four Techniques That Signal Systems Thinking
The following four techniques are not tested because they require rare or advanced Excel knowledge. They are tested because the decision to reach for them — rather than a manual approach — reveals whether a candidate has developed the automation instinct that ByteDance's high-output environment demands. Each one is a proxy question: not 'do you know this feature?' but 'do you think at the system level?'
The Distinct Count via Data Model question is the one that most candidates get wrong not because they lack statistical understanding — they know what a distinct count is — but because they are unaware that standard Pivot Tables count all instances including duplicates. The Data Model checkbox is a UI detail, but knowing it exists signals platform depth. Interviewers use this question as a fast filter: candidates who know it have spent real time building production-grade Pivot Table reports. Candidates who don't know it have used Pivot Tables for basic summaries.
### The Full Series: D1, D2, D3 in Comparison
The three-day ByteDance DA interview series builds a cumulative profile of one hire standard: the ability to move from raw data to defensible decision. Day 1 establishes that you can extract the right data. Day 2 establishes that you can validate whether what the data says is true. Day 3 establishes that you can present it in a form that a busy stakeholder can act on — and that you built the workflow to do it again tomorrow without starting from scratch.
The principle that runs through all three days of the ByteDance DA series: Efficiency is not about typing faster. It is about making the tool do the work for you — and building systems that make the question permanently easier to answer the next time it arrives. SQL is how you extract data. Statistics is how you prevent that data from lying to you. Excel is how you turn the validated result into a decision that gets acted on. A candidate who can do all three, at ByteDance's scale and pace, is the candidate the offer goes to.


---
# ByteDance Data Analyst Interview Series 4 - Business Sense
Source: articles/interview-vault/bytedance-da-interview-series-4.mdx
#### ByteDance Business Case Study: How to Answer "Why Is Retention Dropping?"
Hard skills get you the interview. Business sense and ownership get you the offer. Day 4 covers the framework that turns raw data findings into product decisions.
Days 1 through 3 of the ByteDance DA series built the technical foundation: SQL for extraction, statistics for validation, Excel for delivery. Day 4 is where those technical skills are tested in the context of the question that actually appears on the interview scorecard: can this person translate a data finding into a product decision?
The most dangerous response to a ByteDance business case question is to start building a model. The most common reason otherwise-qualified DA candidates fail the business sense round is not insufficient technical skill — it is insufficient structure. They hear 'retention is dropping' and immediately think about which features to correlate with churn, which queries to run, which model to build. The interviewer is watching for something different: whether the candidate defines the problem before touching the data.
This is Day 4 of the ByteDance DA Interview Series. The content covers the 6-step analytical workflow, the three-source anomaly diagnosis framework, the three evaluation filters the interviewer is scoring against, and the transferable metrics that allow candidates from any industry background to answer TikTok product questions with precision.
### The 6-Step Analytical Workflow
The 6-step framework below is not a template to recite. It is a discipline that prevents the most common business case failure: answering a well-defined analytical question before the problem scope has been established. At ByteDance, where product decisions affect hundreds of millions of users, an analysis that answers the wrong question at high precision is worse than no analysis at all — it produces confident misdirection.
The scoping question that separates a senior response from a junior one: When the interviewer says 'retention is dropping,' the first words out of a senior candidate's mouth are a clarifying question, not a hypothesis. Is this Day-1, Day-7, or Day-30 retention? Is it dropping globally or in a specific region or cohort? Is the drop in the metric itself or in the underlying event log completeness? The candidate who scopes before analysing is demonstrating the product ownership mindset. The candidate who starts hypothesising is demonstrating pattern-matching without problem definition.
### Anomaly Diagnosis: Bug, Outlier, or Fraud
A metric movement that appears in a ByteDance dashboard has three possible sources, and each requires a completely different response. A candidate who jumps to product hypotheses without first ruling out technical and fraud causes is building an analysis on an unvalidated foundation. The anomaly diagnosis step belongs between data extraction and EDA — before any product conclusions are drawn.
The cross-reference discipline that signals senior analytical thinking: When a ByteDance DA sees a retention drop, the first three checks are: (1) null rate in the event log — is the data pipeline intact? (2) deployment log — did an app release or infrastructure change coincide with the timing of the drop? (3) cohort segmentation — does the drop affect all user segments uniformly, or is it concentrated in a specific device type, geographic region, or content category? A uniform drop across all segments on the day of a pipeline deployment is almost certainly a tracking bug. A drop concentrated in one cohort that coincides with a specific content policy change is a product signal. These are different problems requiring different responses — and the candidate who knows to check before hypothesising is the one who avoids presenting a tracking error as a product crisis.
### The Three Evaluation Filters
ByteDance interviewers score business case responses against three explicit criteria. Understanding what each filter is actually measuring — rather than what it appears to measure — is what allows a candidate to answer precisely rather than comprehensively.
The ownership filter is the hardest to perform under interview conditions because it requires demonstrating an attitude rather than a skill. The most reliable way to signal ownership in a case interview is to close every analytical step with a proactive next action: 'Having found that the retention drop is concentrated in the Day-7 cohort from Southeast Asia, I would immediately check whether this coincides with a recent localisation change or a content moderation policy update in that region — rather than waiting for the PM to ask.' The word 'immediately' and the absence of any request for guidance are the ownership signals.
### Transferable Metrics: Why Industry Background Is Not a Barrier
ByteDance DA candidates come from e-commerce, fintech, gaming, SaaS, and consulting backgrounds. The interviewer is not expecting short-video platform experience — they are expecting metric literacy and analytical framework transfer. The metrics and tools below appear across every industry that generates user behaviour data. Knowing their precise definitions and the business questions they answer allows a candidate with no TikTok experience to structure a compelling response to a TikTok product question.
The framing that turns non-industry experience into an asset: A candidate from retail analytics should not apologise for the absence of short-video experience. The correct framing: 'In retail, I measured Day-30 repeat purchase retention as the primary cohort health metric — the definition of the activation event was different, but the cohort construction logic and the segmentation approach are identical to what you would use for TikTok Day-30 return-to-app retention. The metric is transferable; the product context is learnable.' This framing demonstrates analytical maturity and eliminates the perceived industry gap in one sentence.
### The Full Series: D1 Through D4
Day 4 completes the foundational layer of the ByteDance DA interview series. The four-day arc builds a single composite capability: the ability to move from raw event data to a product recommendation that the team can act on — without introducing errors at any stage in the pipeline.
The principle that defines the ByteDance DA standard across all four days: Data is just the starting point. SQL extracts it. Statistics validates it. Excel delivers it. Business sense decides what to do with it. A ByteDance DA who can do all four — who extracts the right data, validates the finding, delivers it efficiently, and owns the product implication without being prompted — is not a data professional who supports product decisions. They are a product thinker who happens to work in data. That is the hire ByteDance is looking for, and that is what all four days of this series are designed to help you become.



---
# ByteDance Data Analyst Interview Series 5 - Machine Learning
Source: articles/interview-vault/bytedance-da-interview-series-5.mdx
### ByteDance ML Interview: How Recommendation Engines Actually Think
At ByteDance, machine learning is not a nice-to-have skill — it is the core product. The interview tests whether you understand why the algorithms work, not just that they exist.
Day 5 is where the ByteDance DA interview series reaches its technical ceiling. Days 1 through 4 established that a candidate can extract data, validate findings, deliver them efficiently, and translate them into product decisions. Day 5 asks whether the candidate understands the machine learning infrastructure that generates the data they are analysing — and whether they can build and evaluate models that feed directly into TikTok's core product surfaces.
The key reframe for Day 5: ByteDance interviewers are not testing algorithm memorisation. They are testing the reasoning behind algorithm selection. A junior candidate says 'I would try a different algorithm to improve the model.' A senior candidate says 'I would improve the data preprocessing — specifically the feature engineering and outlier handling — because the algorithm is rarely the bottleneck in a production ML system at this scale.' That distinction in orientation is the primary filter.
This post covers four technical areas tested most frequently in ByteDance ML interviews: storage architecture, clustering algorithms, the recommendation engine distance metric question, and the standard preprocessing pipeline. Each is presented with the trade-off context that the senior-level answer requires.
### Storage Architecture: Why Columnar Storage Is the ML Foundation
The question 'why do we use columnar storage for ML features?' appears frequently in ByteDance DA interviews as a technical filter question — it seems like an infrastructure question, but it is actually probing whether the candidate understands the data access patterns that ML training workloads require. The answer reveals whether a candidate has thought about how features are stored and retrieved at platform scale, or only about how models are trained in a Jupyter notebook.
The infrastructure reasoning the interviewer is waiting for: ML training on a dataset with 500 features does not read all 500 features for every training run. A model predicting Day-7 retention might use 12 features. Columnar storage allows the system to read only those 12 columns across all rows — ignoring the other 488. With billions of user records, that I/O reduction is not a convenience; it is the difference between a training job that completes in 2 hours and one that runs for 3 days.
### Clustering and Classification: The Algorithm Trade-off Questions
ByteDance ML interviews test algorithm selection judgment, not algorithm recall. The question is never 'what is K-Means?' — it is 'when would you choose DBSCAN over K-Means, and what would you need to observe in the data to make that decision?' The table below presents the four algorithms most frequently appearing in ByteDance Day 5 interviews alongside the trade-off context that constitutes the senior-level answer.
The overfitting answer that signals production experience: A candidate who recommends Random Forest without mentioning hyperparameter constraints is describing the algorithm in the abstract. In a ByteDance production context, the interviewer will follow up: 'How do you prevent the forest from overfitting on the training cohort?' The correct answer includes max_depth to limit tree depth, min_samples_split to require a minimum number of samples before a node splits, and cross-validation on a held-out cohort from a different time period — not just a random train/test split, which can leak temporal patterns. The time-based validation split detail is the practitioner signal that separates someone who has trained models from someone who has debugged them in production.
#### The Recommendation Engine: Why Cosine Similarity Runs the For You Page
The distance metric question is the most product-connected ML question in the ByteDance Day 5 interview. The For You Page recommendation system matches user taste profiles — encoded as vectors of content preferences, watch history, and engagement signals — to video embeddings. The choice of distance metric determines what 'similar' means in that matching process. Getting this wrong produces a recommendation system that surfaces popular content rather than relevant content.
The NLP context adds a further dimension to this question. ByteDance uses NLP for comment sentiment analysis, auto-captioning, and content categorisation — all of which produce text embeddings that are compared using cosine similarity. A candidate who connects the cosine similarity answer to NLP applications ('this is the same distance metric used in ByteDance's NLP pipelines for content tag matching and comment sentiment clustering') demonstrates product-stack depth that the interviewer will note as a strong signal.
### The Standard Preprocessing Pipeline
When asked how they would improve a model, junior candidates change the algorithm. Senior candidates improve the data. The preprocessing pipeline is where the majority of ML quality improvements at ByteDance are made — not in algorithm selection, but in the sequence and precision of data preparation before the first model is trained. The four-step pipeline below is the production-standard sequence. The order is not arbitrary.
The reservoir sampling detail in the feature engineering step is the specific signal that differentiates candidates with academic ML experience from candidates with production ML experience. In an academic setting, datasets fit in memory. At ByteDance, a single day of TikTok event logs does not. Reservoir sampling — which selects a random sample of size K from a stream of N records in a single pass, with each record having equal probability of inclusion — is the correct tool for exploratory work on datasets that exceed memory capacity. Most statistics courses do not cover it. Knowing it signals that you have worked with data at the scale ByteDance operates at.
### The Complete Series: D1 Through D5
The principle that connects all five days — and defines what ByteDance is actually hiring: ByteDance does not hire candidates who are strong in one of these five domains. It hires candidates who can move fluidly across all five: extract the right data with SQL, validate the finding with statistics, deliver it efficiently with Excel, translate it into a product decision with business sense, and build the predictive model that automates that decision at scale with machine learning. Each day of this series is a layer in the same capability stack. A DA who can do all five layers — and who understands why each one matters for the product, not just how to execute it technically — is the hire that ByteDance's interview process is designed to find.



---
# Class of 2026 Data Science Grads: Are You Really Ready? 4 Brutal Truths Hidden in One Roadmap
Source: articles/interview-vault/data-science-advanced-graduates.mdx
By Shuangshuang Wu · Career Intelligence Series · March 23, 2026 · 11 min read
Every year, thousands of data science graduates flood the job market armed with impressive degrees — and get eliminated in the first phone screen. The problem isn't ability. It's the absence of a mental framework.
{/* Stats Cards */}
36%
projected job growth for data science roles
4×
salary gap between entry- and experienced-level hires
4 rounds
each testing a completely different hidden competency
We did a deep dive into a 2026 Data Science Interview Roadmap designed specifically for advanced graduates — and found four insights that most candidates never realize until it's too late. The gap between candidates who get offers and those who don't isn't usually technical depth. It's the presence or absence of a structured way to think about problems under pressure.
1. Technical Learning Has a Phase Order — Skipping Ahead Will Cost You
The roadmap breaks technical growth into six phases: Mathematical Foundations → Coding Proficiency → Exploratory Data Analysis → Core Machine Learning → Deep Learning → MLOps and Production. Most candidates assume Phase 4 is where interviews happen. It isn't. Interviewers at top-tier companies frequently probe Phase 1 — and they do it deliberately, because it's where most candidates have the weakest foundations.
| The Six Phases — and Where Candidates Underinvest |
| Phase 1 · Math |
Linear algebra, statistics, calculus. The layer most candidates deprioritize. The layer most senior interviewers probe first. |
| Phase 2 · Coding |
Python, SQL, version control. Table stakes — but the quality of your code under pressure reveals more than your portfolio does. |
| Phase 3 · EDA |
Exploratory data analysis before modeling. Candidates who skip this step in interviews reveal they've only worked with clean, pre-processed datasets. |
| Phase 4 · Core ML |
Regression, classification, ensemble methods. What most candidates over-prepare for. |
| Phase 5 · Deep Learning |
Neural networks, transformers, LLMs. Increasingly tested, but rarely the deciding factor at interview. |
| Phase 6 · MLOps |
Production deployment, monitoring, CI/CD for ML. The phase that separates researchers from engineers — and increasingly, what late-stage interviews test. |
Interview Signal
Dedicate at least 20% of your prep time back to Phase 1. This is exactly where most competitors cut corners — and where you can pull ahead fastest. When an interviewer asks you to explain the bias-variance tradeoff, they want mathematical reasoning, not a rehearsed buzzword definition.
2. Statistics Is a Trap — Because Interviewers Go Two Layers Deep
Here's the deceptively correct answer every candidate gives: a p-value ≤ 0.05 indicates strong evidence against the null hypothesis. Textbook accurate. And in 2026, completely insufficient at a top-tier company. The follow-up questions are getting sharper — and they're designed to surface whether you understand the concept or just the definition.
"What's the difference between statistical significance and practical significance?"
Why they ask: To test whether you understand that a result can be mathematically real and operationally meaningless at the same time — especially with large sample sizes.
A result is statistically significant when the p-value clears the threshold. It's practically significant when the effect size is large enough to matter to a user or a business. With a large enough sample, almost anything becomes statistically significant — including differences too small to act on. Always pair p-values with effect size metrics like Cohen's d or confidence intervals.
💡 Expert Tip — The Two-Layer Rule
Layer 1
State the definition precisely.
Layer 2
State its most common misuse or limitation — and give a concrete example of when it fails.
Why it works: This pattern signals that you've used the concept in real conditions, not just studied it. Apply it to every statistics question you answer.
3. The Portfolio Trinity Is Harder to Execute Than It Looks
The roadmap introduces a portfolio framework: Fun × Relevant × Explainable. Most candidates read this and think their current portfolio qualifies. It almost certainly doesn't — because checking one dimension at the expense of the others is the most common portfolio failure mode.
Technical Purist
Relevant ✓ · Explainable ✗ · Fun ✗
Nobody outside their field understands it, and there's no human angle that generates interest.
Business Background
Fun ✓ · Relevant ✗
Lacking the technical depth that engineering interviewers need to see.
Typical Fresh Grad
Misses all three dimensions
A Kaggle classifier with 92% accuracy on a pre-cleaned dataset. No domain personality, no real data messiness, no narrative.
✓ Portfolio that stands out
"I took a domain I genuinely care about, used real-world messy data, and built a story that goes from raw input to business decision — documented fully on GitHub with a companion blog post."
Interview Signal
GitHub combined with a personal blog documenting the full workflow — from raw data to business narrative — is what 'Show, Don't Just Tell' actually means. The blog post is not optional decoration. It's where you prove you can communicate findings to a non-technical stakeholder.
4. The Four Interview Rounds Each Have a Hidden Scoring Dimension
From phone screen to offer, each stage of the data science interview cycle tests a stated competency and a hidden one. Candidates who only prepare for the surface layer quietly lose points on the dimension the interviewer is actually scoring.
| Stage |
Surface Assessment |
Hidden Assessment |
| Phone Screen |
Background introduction |
Clarity of self-positioning. Can you explain your journey and your target role in 90 seconds without wandering? |
| Virtual Technical |
SQL / ML algorithm questions |
Thinking visibility under pressure. Are you narrating your reasoning, or silently computing? Interviewers score the process, not just the answer. |
| On-site Deep Dive |
Whiteboard coding / case study |
Stakeholder communication ability. Can you explain a modeling decision to a non-technical audience without losing precision? |
| HR Round |
Culture fit conversation |
Consistency of career narrative. Does your story hold together across everything you've said? Inconsistencies surface here. |
🎯 Interview Tactic — Prepare for the Hidden Layer Explicitly
Phone Screen
Practice a 90-second positioning statement that names your target role, your strongest relevant experience, and why this company specifically.
Virtual Technical
Narrate your reasoning out loud as you work — even if you're uncertain. Silence signals a black-box process that teams can't trust or collaborate with.
On-site
After every technical explanation, add one sentence translating it to business impact. 'Which means for the product team, this model reduces false positives by X%.'
The Gap Between Entry-Level and Experienced Isn't Years — It's the Quality of Your Mental Framework
Data science is projected to be one of the fastest-growing careers of the decade, with a 4× salary gap between entry-level and experienced professionals. That gap isn't primarily about years of experience. It's about the systematic quality of how you think about problems, communicate under pressure, and build things that work in the real world.
At HéraAI, we believe career competitiveness in the AI era starts with honest self-assessment and a structured preparation path — not just more flashcards.
This article is part of the Career Intelligence Series from HéraAI — Instant Access to 5.8M+ Active Jobs Worldwide.
---
# Google Interview Questions Guide
Source: articles/interview-vault/google-interview-guide.mdx
12 min read
#### Cracking the Google Code: 5 Strategic Truths Every Candidate Needs to Know Before the Interview
Google interviews can take up to four months. They test more than your technical skills — they test whether you think, decide, and communicate like a Googler. The candidates who make it through aren't just smart. They've decoded the system.
The AI boom has put Google at the center of every serious engineer's career ambitions. But landing a role here isn't just a test of what you know — it's a test of how you think. Google has a specific DNA they screen for at every stage: "Googliness". It's not a vague culture-fit buzzword. It's a precise combination of data-driven decision-making, genuine empathy, and the ability to operate confidently in ambiguous situations. Here are the five truths that will change how you prepare.
#### 1. "Googliness" Is a Technical Standard — Not a Personality Test
Most candidates misread this. They prepare polished anecdotes about teamwork and assume that's enough. It isn't. Google's interviewers are using Googliness as a structured signal for professional maturity under pressure — specifically, your ability to drive outcomes in situations where the map doesn't exist yet.
### 2. Frameworks Are Your Scaffold — Not Your Script
Every serious Google candidate knows STAR. Far fewer know how to use it as a thinking tool rather than a recitation template. The difference is visible within 90 seconds of your answer.
What interviewers are watching for: whether your 'Action' section shows genuine initiative — not just participation — and whether your 'Result' is quantified. An unquantified result signals that you weren't measuring what mattered.
### 3. Behavioral Answers Are Won or Lost Before You Speak
The most common mistake in Google behavioral interviews: candidates treat them as a storytelling exercise. Google treats them as a structured data collection exercise. Your answer is being evaluated against specific rubrics — not for narrative quality.
The preparation principle: build a Story Bank of 3–4 specific experiences before you walk in, each tagged to a core Googliness principle. Don't improvise this on the day.
### 4. Product Sense Questions Reward Diagnosis, Not Speed
Google's product sense questions are designed to penalize the candidate who jumps straight to solutions. The correct opening move is always clarification — because the metric you're asked about is almost never the one that matters most.
The instinct to fix before you've diagnosed is the fastest way to signal inexperience. Interviewers want to see a systematic mind, not a fast one.
### 5. Strategy Questions Test Business Judgment, Not Just Marketing Knowledge
Google's strategy and marketing cases — like increasing YouTube Premium penetration in a new market — aren't looking for creativity. They're looking for analytical rigour and commercial awareness. The AARRR model is the structural backbone, but the quality of your answer lives in the economics.
#### The Candidates Who Get Offers Aren't Just Prepared — They Think Like Googlers Already
The Google interview process is long by design. Every touchpoint is an opportunity to demonstrate that you don't just know the frameworks — you've internalized the thinking behind them. Googliness isn't a performance. It's a consistent pattern of data-first reasoning, user-centered judgment, and intellectual honesty about what you don't know.
The candidates who reach the offer stage aren't necessarily the most technically accomplished in the room. They're the ones who make the interviewer feel like they're already talking to a colleague.
At HéraAI, that's the level of strategic clarity we help candidates develop — not just what to say in a Google interview, but how to think in one.

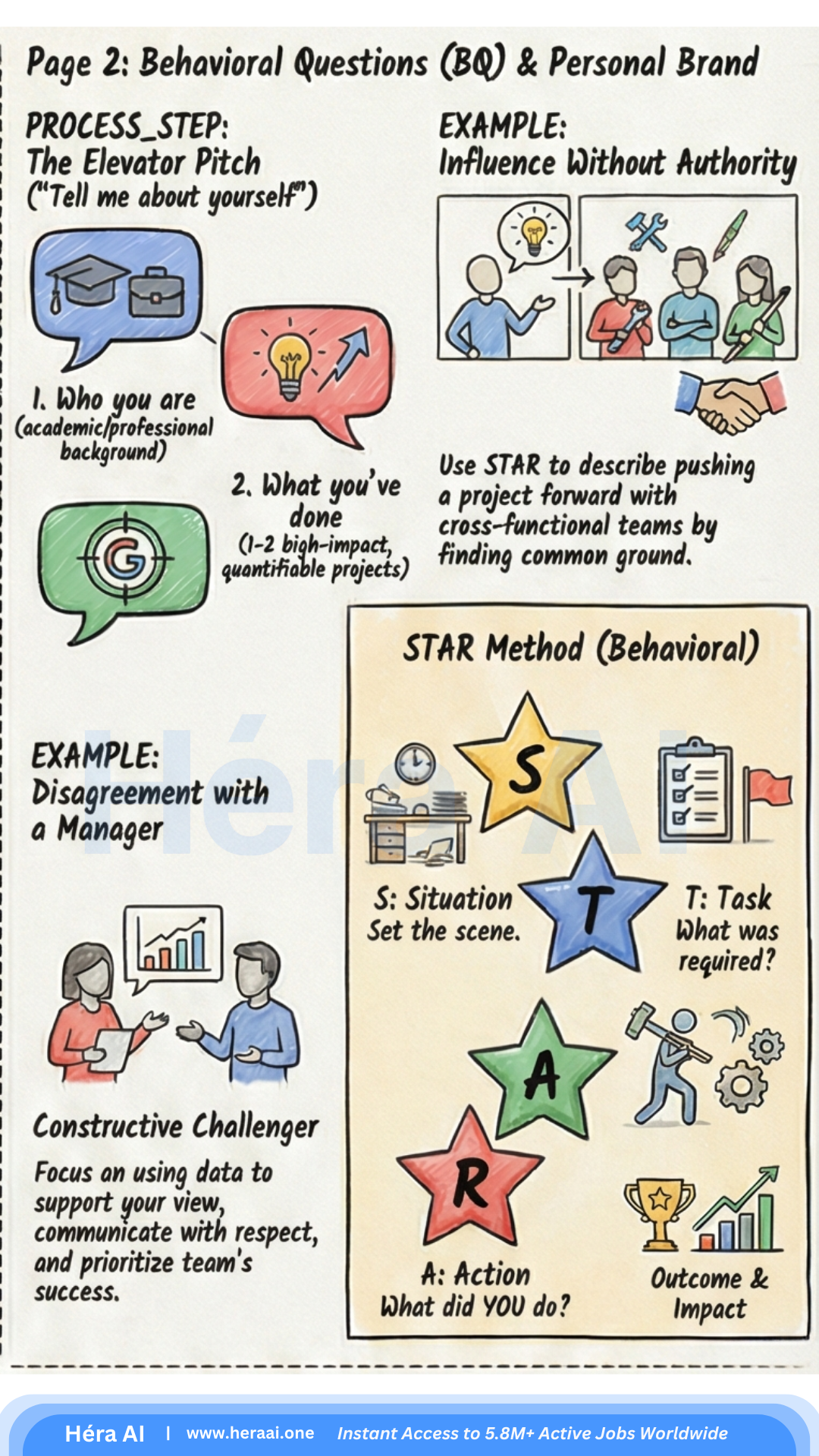
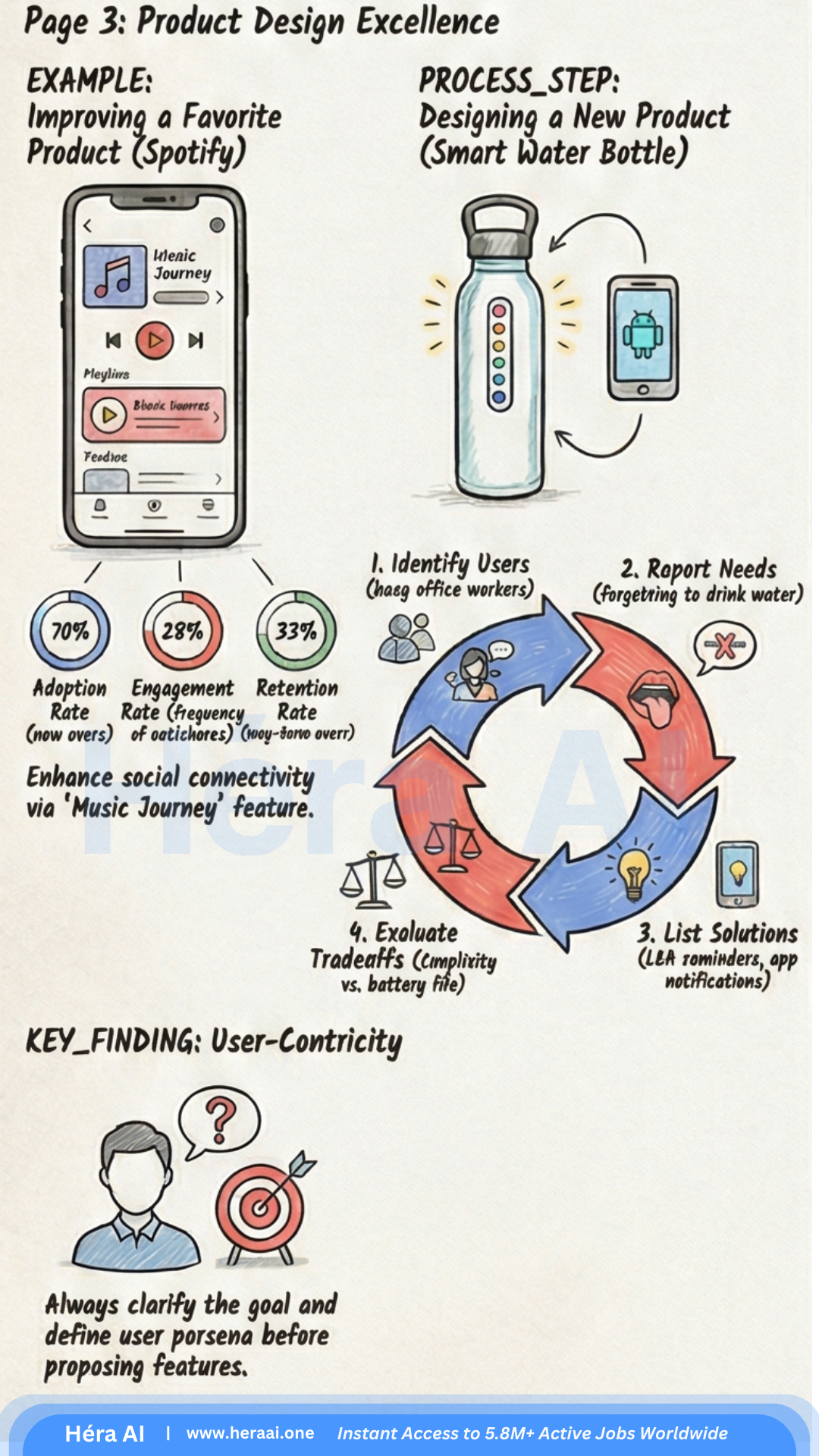

---
# Stop Answering ML Interviews. Start Running Them.
Source: articles/interview-vault/ml-interview-guide.mdx
By Carrie Yu · HéraAI · March 22, 2026
What Alibaba's BST paper reveals about what senior engineers actually know — and how to demonstrate it.
Most candidates walk into an ML system design interview prepared to answer questions. The ones who get offers walk in prepared to lead a conversation.
That distinction — between responding and directing — is the entire gap between a junior and a senior signal. And understanding why requires looking at how the world's most sophisticated recommendation systems are actually built, not just how they're described in textbooks. We combined insights from engineering blogs at Instagram and Pinterest with a deep read of Alibaba's published research on their Behavior Sequence Transformer (BST) — the model powering recommendations for hundreds of millions of Taobao users daily.
{/* Stats Cards */}
+7.57%
BST online CTR lift vs. Wide & Deep baseline
20ms
BST response time at Taobao scale
{/* Image before first section */}
1. The 80/20 Rule Is a Systems Thinking Signal, Not a Communication Tip
The single most reliable indicator separating a junior ML candidate from a staff-level engineer isn't mathematical depth. It's who controls the frame of the conversation.
Junior candidates wait for questions. They answer what's asked, demonstrate knowledge on demand, and follow wherever the interviewer leads. This is the exam mindset — and it's the wrong mental model for an ML system design session.
Senior candidates treat the interview as a guided presentation. They clarify business objectives before touching architecture. They drive 80% of the dialogue. They ask:
• "Are we optimizing for engagement — session length, return rate — or for revenue?"
• "Is the primary constraint latency, infrastructure cost, or cold-start performance on new users?"
This isn't confidence theater. It reflects a genuine understanding that there is no universally correct ML system — only systems correctly aligned to specific product objectives. A model optimized for click-through rate at Taobao will look completely different from one optimized for watch time at YouTube, even when both use Transformers and both serve billions of users.
Key takeaway: Before rehearsing any architecture, rehearse your clarifying questions. The quality of those questions is the first signal an interviewer reads — and it sets the frame for everything that follows.
2. The Two-Stage Pipeline: Most Candidates Only Understand Half
At production scale — tens of millions of items, hundreds of millions of users, real-time serving constraints — you cannot run a deep ranking model across the entire item catalog. The math simply doesn't fit within latency budgets. This is why every major industrial recommendation system converges on the same fundamental architecture: a two-stage pipeline of Match (candidate generation) and Rank.
Match Stage — Speed & Coverage
Embedding-based retrieval (e.g., ig2vec + FAISS) narrows millions of candidates to a shortlist in milliseconds.
Precision is deliberately sacrificed for throughput at this stage.
Rank Stage — Precision & Engineering Judgment
Instagram Explore uses a three-layer funnel: distillation model → lightweight NN on dense features → deep NN on dense + sparse features.
Alibaba's BST builds on Wide & Deep, embedding user profile, item category, context, and cross features before CTR prediction.
The insight most candidates miss: knowing this architecture exists is table stakes. Being able to reason about the tradeoffs at each stage — why distillation replaces full-model inference, what precision you lose at the match stage and why that's acceptable — is the senior signal.
3. The BST Paper's Core Finding: Order Is Information
Here's the finding from Alibaba's research that should change how every ML practitioner thinks about user behavior data.
The dominant paradigm before BST was Embedding & MLP: raw features embedded into low-dimensional vectors, concatenated, and fed into a multi-layer perceptron. Google's Wide & Deep and Alibaba's own Deep Interest Network (DIN) both follow this pattern.
The critical limitation: concatenation destroys sequence.
When a user's clicked items are concatenated as a flat feature vector, all information about the order of those clicks is lost. But order carries meaning. A user who bought an iPhone and then searched for phone cases expresses very different intent from one who bought a phone case and then searched for iPhones — even though the item histories are identical.
Alibaba's BST addresses this by applying the Transformer architecture to user behavior sequences. The self-attention mechanism learns relationships between items in a user's click history, capturing not just what was clicked but how that sequence evolved over time.
BST's Positional Embedding Design
Instead of standard sinusoidal position encoding, BST defines position as the time difference between when an item was clicked and when the recommendation is being made. This encodes recency directly into the model — giving structural weight to recent behavior over older signals.
+7.57%
CTR vs. Wide & Deep
20ms
response time at scale
What a staff-level answer looks like: Walk through the full reasoning chain — from the limitation of concatenation, to the sequential signal hypothesis, to the Transformer as solution, to the positional embedding design choice, to production deployment tradeoffs. That depth of connected reasoning is what distinguishes a senior candidate.
4. Production Constraints Are Part of the Answer, Not a Footnote
One of the most common failure modes in ML system design interviews is treating the model as the complete answer. The architecture goes on the whiteboard, the interviewer nods, and the candidate considers the question closed. It isn't.
A production ML system is a model embedded inside an infrastructure, monitored against business KPIs, updated on a deployment schedule, and subject to real-world constraints that no offline benchmark captures. The BST paper illustrates this directly. Alibaba chose a single Transformer block over stacking multiple blocks — not because deeper stacking couldn't theoretically improve AUC, but because single-block BST achieved the best offline performance in practice (stacking to b=2 or b=3 actually degraded results), and because production feasibility required response times competitive with WDL and DIN at Taobao scale.
The Pattern That Signals Senior Judgment
For every architectural decision you propose, immediately follow it with:
→
The constraint it's responding to
→
The tradeoff it introduces
Decision → Constraint → Tradeoff. That's the vocabulary of senior engineering.
The product mindset: The best model isn't the most accurate model in isolation. It's the model that maximizes the metric that matters while respecting real constraints — latency SLAs, infrastructure costs, feature drift monitoring, retraining frequency, and organizational capacity to maintain it.
The Throughline: ML Interviews Are Product Conversations in Technical Clothing
Every insight in this breakdown points to the same principle. The candidates who perform at the highest level in ML system design interviews aren't the ones who've memorized the most architectures. They're the ones who understand that every technical decision is simultaneously a product decision — shaped by user behavior, business objectives, infrastructure constraints, and the ongoing lifecycle of a system that serves real people at real scale.
The BST paper isn't just a research contribution. It's a case study in exactly this kind of thinking — and being able to discuss it at that level of depth, in an interview room, is the difference between a candidate who knows ML and a candidate who is ready to lead it. At HéraAI, that's the shift we help engineers make.
This article is part of the Tech Career Interview Series from HéraAI — Instant Access to 5.8M+ Active Jobs Worldwide.
---
# NLP Interview Guide 2026
Source: articles/interview-vault/nlp-interview-guide-2026.mdx
### From Career Switcher to NLP Engineer: Your 2026 Interview Masterclass
NLP is no longer a niche for academics. It is the engine behind a $201B market — and the interview is accessible to anyone who understands the mechanics, not just the theory.
Natural Language Processing has moved from research papers into production infrastructure. Every customer-facing AI system, every enterprise search tool, every automated document processor runs on NLP foundations. The $201.49 billion market projected for 2031 is not being built by academics — it is being built by engineers who understand how language models work well enough to deploy them reliably, evaluate them honestly, and explain their limitations clearly.
For career switchers, the path into NLP engineering is real and structurally accessible — but it requires targeted preparation. NLP interviews test a specific combination of theoretical understanding and practical judgment that neither pure coding practice nor pure reading will produce. The engineers who pass these interviews are the ones who can explain not just what each concept does, but why it matters for the specific task at hand and what it breaks on in production.
This post covers the ten technical questions that define the NLP interview at most companies hiring in 2026, a tokenization deep-dive that separates Level 1 from Level 3 answers, and the four-part preparation strategy designed specifically for career switchers entering the field without a conventional ML background.
### The Big 10: Technical Questions and the Senior-Level Answers
The ten questions below are not a random sample — they represent the technical pillars that appear most consistently across NLP engineering interviews at companies ranging from AI-native startups to enterprise tech employers. For each, the table below provides the pillar category and the content that constitutes a senior-level answer, not just a correct one.
The distinction that separates a passing answer from a strong one across all ten questions: Every technical question in an NLP interview has a surface answer and a depth answer. The surface answer demonstrates familiarity with the concept. The depth answer demonstrates understanding of why the concept exists — what problem it solves, what it fails on, and what trade-off it makes. Interviewers at companies building production NLP systems are not testing whether you have read the Wikipedia article. They are testing whether you have thought about the production implications.
### Tokenization Deep-Dive: The Question Behind the Question
Tokenization is Question 1 on the Big 10 list for a reason: it is the foundational architectural decision that determines everything downstream. An engineer who understands why subword tokenization exists — and can connect it to the specific models that use each approach — has demonstrated the conceptual depth that NLP interviewers are screening for in the first five minutes.
The most common tokenization interview follow-up: 'What happens when you tokenize a domain-specific term your model has never seen — say, a proprietary drug name or a company's internal product code?' The answer reveals whether a candidate understands OOV handling in practice. With BPE, the term will be split into known subword units — potentially losing the specific meaning of the whole token. The production solution: include domain-specific terms in fine-tuning data so the tokenizer learns them as single units, or use a character-level fallback. This level of answer is what closes the interview loop.
#### AI Ethics: The Technical Requirement That Most Candidates Treat as a Soft Skill
Question 9 — bias identification and mitigation — is the one that most career switchers either over-prepare for with philosophical language or under-prepare for with no technical depth. Neither approach works. Interviewers at companies deploying NLP in hiring, healthcare, legal, or financial contexts are asking this question because bias in their system is a regulatory and reputational liability. They need an engineer who has a technical plan, not an ethical position.
The technical answer for a 2026 NLP interview covers three stages: data auditing before training (examining corpus composition for demographic representation and historical encoding of discrimination), balanced sampling or reweighting during training (ensuring model does not optimise against minority-class language patterns), and disaggregated evaluation after training (measuring performance separately across demographic and linguistic subgroups rather than reporting a single aggregate accuracy that can mask group-level failures).
The AI ethics answer that signals production experience rather than academic awareness: 'I would start by auditing the training corpus for demographic representation — specifically checking whether the data over-represents certain geographic, linguistic, or socioeconomic groups in ways that would encode their language patterns more strongly than others. Then I would evaluate the trained model separately across subgroups before deployment, and set minimum performance thresholds for each group as a release criterion — not just overall accuracy.' This answer describes a process with concrete decision points, not a values statement.
### The Career Switcher's Preparation Strategy
The four strategies below are ordered by dependency: Foundation must come first, because the portfolio and communication skills build on it. The Linguistic Intuition advantage is listed third not because it is less important, but because it is only visible to an interviewer after the technical foundation is established.
The principle that defines the career switcher's path into NLP engineering: You are not competing with CS graduates on their home ground — you are bringing a combination they do not have: engineering fundamentals plus domain knowledge plus the communication skills that come from working in a field where language precision mattered before you ever wrote a line of Python. The NLP interview rewards people who understand how language actually works in context, not just how models process tokens. That understanding is your entry point — and this post is the map to make it visible in the interview room.
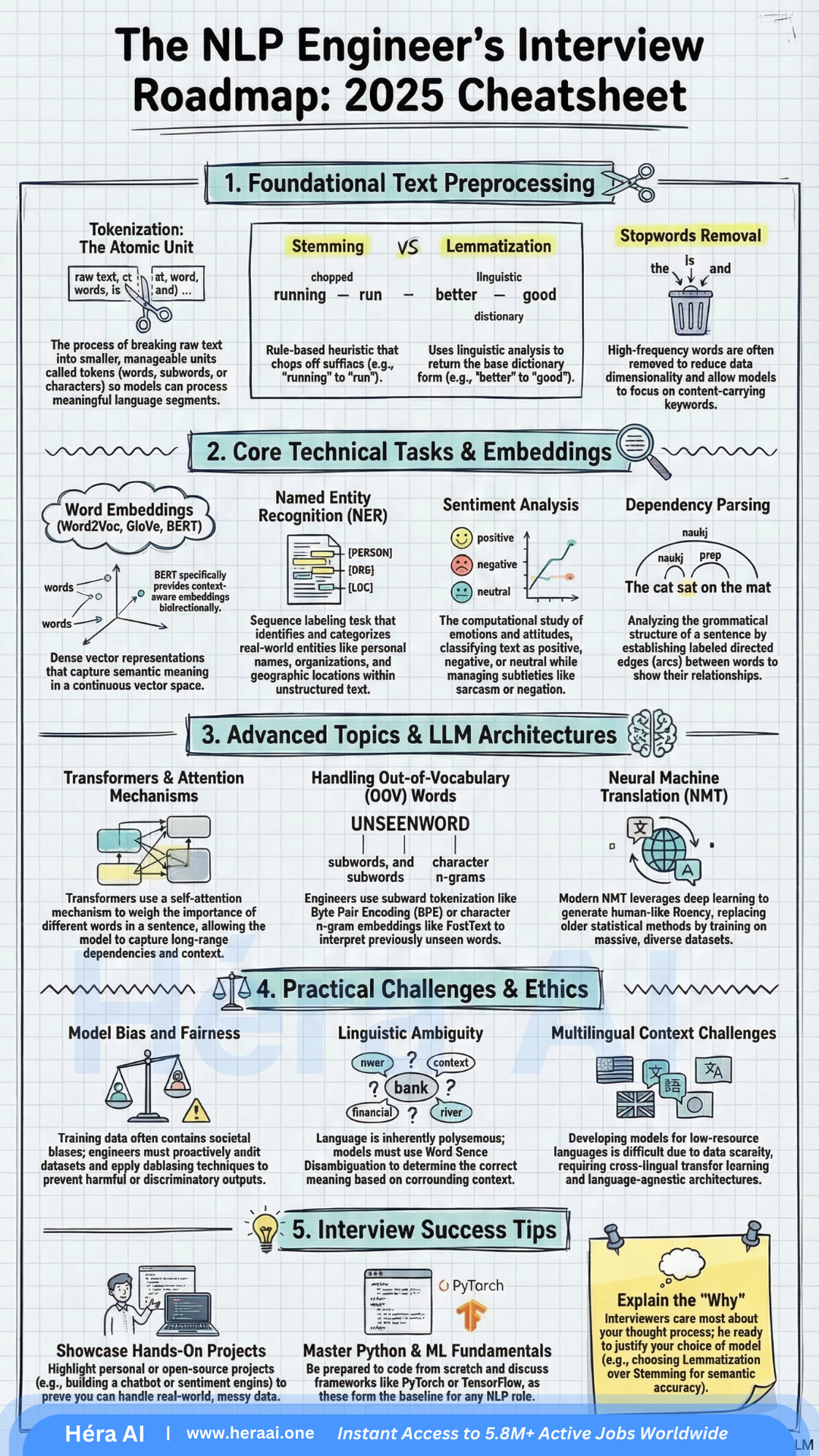
---
# NVIDIA Data Analyst Interview Guide
Source: articles/interview-vault/nvidia-data-analyst-interview-guide.mdx
#### Cracking the NVIDIA Data Analyst Interview: It Is Not Just About the Code
The difference between a junior DA and a senior DA at NVIDIA is not knowing SQL — it is knowing why the query matters to the business, who needs to act on the result, and how to tell them.
NVIDIA interview questions look like standard SQL and Python problems on the surface. Candidates who answer them by the book — technically correct, analytically complete, presented without context — will likely be rejected. The reason is structural: NVIDIA's DA role sits at the intersection of silicon engineering and corporate strategy, and the interview is explicitly designed to find candidates who can operate in both registers simultaneously.
The technical questions are real filters, not formalities. A GROUP BY where a window function is needed signals a candidate who produces correct output but destroys analytical granularity. A dashboard that leads with Revenue signals a candidate who has not thought about the supply chain economics that define NVIDIA's business model. These are not wrong answers — they are junior answers. The interview is calibrated to find the difference.
This post breaks down NVIDIA's three evaluation pillars, the specific SQL and business metric questions most frequently cited in interview reports, and the cross-functional communication skill that the interview explicitly tests in its behavioural round.
### The Three Pillars NVIDIA Evaluates
NVIDIA's DA interview scorecard maps to three explicit evaluation dimensions. Understanding which pillar each question is probing — before answering — is what allows a candidate to deliver the right level of response rather than the technically correct but contextually incomplete one.
The calibration insight that changes how you approach every question: Before answering any NVIDIA interview question, identify which pillar it is primarily testing. A SQL question is testing Technical Precision — but the follow-up 'and what would you present to the CFO?' is testing Cross-Functional Literacy. A dashboard design question that begins technically is actually testing Business Health Literacy. Candidates who recognise the pillar shift and adjust their answer accordingly are the ones who pass all three filters in a single response.
#### The SQL Window Function Question: Why GROUP BY Is the Junior Answer
The departmental expenditure question asks candidates to calculate each department's salary total and compare it to the company-wide average. The junior answer is a GROUP BY with a subquery for the average. The senior answer uses window functions to keep every individual row intact while adding the aggregated comparisons as computed columns — allowing a single query to surface the outlier without requiring a second analytical request.
The business framing of the window function answer matters as much as the technical execution. A senior candidate who writes the correct window function query and then adds: 'This gives the CFO a single view where they can immediately identify which employee or department is driving the variance — without needing to come back to the DA for a drill-down' has completed both the technical and the cross-functional components of the answer in a single response.
The Python edge case question and what NVIDIA is actually testing: The Integer to Roman Numeral conversion question is not primarily testing Python knowledge — it is testing whether a candidate thinks about edge cases before they become bugs. The subtractive notation cases (IV, IX, XL, XC, CD, CM) require explicit handling that a naive loop will miss. At a company that builds chips where a single logic error in a billion-gate design can cost hundreds of millions of dollars, the habit of asking 'what are the edge cases?' before writing a single line of code is a cultural value, not just a technical skill. Mentioning the subtractive cases proactively — before being asked — is the signal the interviewer is watching for.
#### The Account Status SQL: A Churn Question Disguised as a JOIN Question
The account status question asks candidates to write SQL that classifies accounts based on their presence or absence on December 31 and January 1. The technical answer involves a FULL OUTER JOIN on account ID with date filtering. The senior answer treats the question as what it actually is: a churn, retention, and reactivation classification problem — with a seasonality consideration built in.
The seasonality flag that distinguishes a senior business interpretation: Q4 enterprise churn at a company like NVIDIA — which sells hardware to large data centre operators and cloud providers — is heavily influenced by fiscal year-end contract renewal cycles. A December 31 churn rate may reflect a contract timing pattern rather than genuine product dissatisfaction. A candidate who presents the raw churn number without flagging this seasonality has answered the SQL question but missed the business question. The senior response: 'Before presenting this churn figure to the product or sales team, I would segment by contract type and renewal date to confirm whether this is structural churn or fiscal year timing.'
### The Dashboard Design Question: Why Revenue Is the Junior Answer
The D2C dashboard question is designed to surface whether a candidate defaults to generic top-line metrics or thinks about the specific business model they are measuring. For a hardware-adjacent company, the metrics that drive decisions are not the same as the metrics that drive decisions for a SaaS platform or a social media product. Inventory Turnover and CAC Payback Period are the answers that signal NVIDIA business literacy.
The CAC Payback Period answer is the one that most reliably distinguishes candidates with capital allocation thinking from those with general marketing analytics backgrounds. Calculating CAC in isolation — how much it costs to acquire a customer — is table stakes. The Payback Period frames that cost as a duration of commitment: 'we will not recover this acquisition cost until Month 18.' For a hardware business where customer relationships are long-cycle and product generations advance every two years, that duration frames the entire retention strategy.
### The Bridge Skill: Speaking Engineer and Executive Simultaneously
Question 5 in the NVIDIA interview explicitly tests collaboration with engineers and stakeholders. This is not a behavioural question dressed up as a technical one — it is a direct test of whether a candidate can modulate their communication register based on the audience without losing precision in either direction. NVIDIA's DA sits between the silicon teams who produce the product data and the executive teams who make capital allocation decisions based on it. Both audiences require different language and different levels of detail.
The principle that defines the NVIDIA DA hire: NVIDIA does not hire data professionals who support product decisions. It hires analysts who are the bridge between the silicon and the strategy — who can write a technically precise window function query, interpret the result in the context of NVIDIA's supply chain economics, and communicate the finding to a VP in two sentences without losing a single degree of analytical accuracy. That compound capability — precision across technical, business, and communication dimensions simultaneously — is what the three-pillar interview is designed to find, and what this post has been built to help you demonstrate.




---
# Power BI Cheatsheet - The Three Pillars
Source: articles/interview-vault/powerbi-cheatsheet-three-pillars.mdx
### Power BI Mastery: The 3 Pillars of Data Career Success
Most beginners treat Power BI like a fancy PowerPoint. To land a DA role in 2026, you need to understand the architecture — visuals, modeling, and DAX logic.
Power BI is one of the most in-demand tools on Data Analyst job descriptions in 2026 — and one of the most misunderstood by candidates who list it. The gap isn't in knowing how to build a dashboard. It's in understanding the decisions behind it: why one visual communicates a trend and another actively obscures it, why a broken data model produces silently wrong numbers, and why a candidate who can't explain the difference between a Measure and a Calculated Column will not pass a mid-level technical screen.
This article breaks down the three pillars that structure a working Power BI skill set for DA interview preparation: visual selection logic, Power Query data modeling, and DAX calculation design. Each pillar covers the surface-level knowledge most candidates have — and the depth of reasoning that actually gets you hired.
### The Three Pillars at a Glance
The pillars below build on each other. Visual selection without a clean data model produces reports that look professional but contain unreliable numbers. A clean data model without DAX knowledge limits the analyst to basic aggregations. DAX knowledge without an understanding of context manipulation produces calculations that appear correct but behave unpredictably when filters change.
The framing that changes how you approach the tool: Power BI is not a reporting tool. It's an analytical decision system that happens to produce reports. Every choice — visual type, model relationship direction, DAX function — is an analytical decision with downstream consequences for how reliably the report communicates the truth. Thinking this way is what separates a DA who builds dashboards from one who builds trusted decision infrastructure.
### Pillar 01 — The Art of Visual Selection
The most common mistake in Power BI report design is selecting a visual for aesthetic reasons — a donut chart because it looks modern, a gauge because it fills space, a 3D bar chart because it appears dynamic. Each of these choices communicates something specific about the data, and choosing the wrong one is not a style error — it is an accuracy error.
The core principle: every visual type answers a specific type of analytical question. Matching the visual to the question is not optional for production reports. The table below maps each major visual type to its correct use case and the production decision note that interviewers will probe if you cite it in a screen.
The Sankey diagram deserves specific attention. It visualizes flows between stages — user journeys, funnel drop-offs, budget allocations — in a way that no other chart type replicates effectively. It's rarely used by junior analysts because it requires the data to be in a specific source-target format and the interpretation requires understanding proportional flow logic. Presenting one correctly in a portfolio project is a strong signal of production experience.
HéraAI interview technique: When asked about your dashboard design process, don't describe the visual — describe the decision. 'I used a scatter plot for this because I needed to show whether ad spend and conversion rate were correlated, and a bar chart would have masked the relationship by presenting them as separate metrics rather than paired data points.' That framing demonstrates analytical intent, not just tool familiarity.
### Pillar 02 — The Power Query Foundation
Power Query is the transformation and modeling layer of Power BI. It runs before any visualization and determines whether the numbers in those visualizations are trustworthy. Most candidates understand it as 'where you clean data.' The technical screen is designed to determine whether you understand it as 'where you define the analytical truth of your report.'
A data model with incorrect relationship directions, unresolved data type issues, or tables left in wide pivot format will produce calculations that appear to work correctly in some views and silently fail in others. The ability to diagnose and prevent these failures is what interviewers mean by 'strong data modeling skills.'
The unpivoting operation is the one most candidates encounter first and understand least deeply. When a source dataset arrives with columns named 'Jan', 'Feb', 'Mar' — a common format for Excel exports — those months are data values, not column headers. Power BI's time intelligence functions require date values to be in rows. Unpivoting converts the wide format into a tall format with 'Month' and 'Value' columns, making the data compatible with DATEYTD(), SAMEPERIODLASTYEAR(), and every other time intelligence function in DAX.
The model design signal interviewers look for: Can you describe your data model without looking at it? If you built the report, you should be able to say: 'I have a Sales fact table with foreign keys to Date, Product, and Customer dimension tables. All relationships are one-to-many from the dimension side. I unpivoted the source data before loading because it arrived in pivot format from the finance team's Excel export.' That description tells an interviewer everything they need to know about your modeling competence.
### Pillar 03 — Interview-Ready DAX Logic
DAX — Data Analysis Expressions — is the formula language that powers every calculation in Power BI. It is also the primary filter that separates junior DA candidates from mid-level and senior ones in technical screens. The reason is not complexity — the most important DAX concepts are not difficult to learn. The reason is that most candidates learn enough DAX to build a working report without ever developing the conceptual model that explains why it works.
The single most commonly asked DAX question in DA interviews is the distinction between a Measure and a Calculated Column. The table below maps the six dimensions of that distinction — and includes the interview test case that demonstrates the difference in practice.
The row context vs. filter context distinction is the senior-level layer of the same question. A Calculated Column has row context — it evaluates the formula for each row individually. A Measure has filter context — it evaluates the formula within whatever filter state is active in the report at query time. CALCULATE() is the function that explicitly modifies filter context inside a Measure, which is why it is the most powerful and most frequently misunderstood function in DAX.
The answer that closes the Measure vs. Calculated Column question: 'A Measure is evaluated at query time within the current filter context — it recalculates dynamically every time a slicer changes. A Calculated Column is evaluated at model refresh, stores a result for every row, and does not respond to filter context. I use Measures for any metric I want to aggregate or filter — revenue, retention rate, average order value. I use Calculated Columns only for row-level logic that needs to be available as a filter or axis value, like a profit margin category label.' That answer will pass any mid-level technical screen.
### From Dashboard Builder to Analytical Decision Partner
The three pillars in this article represent the difference between a Power BI user and a Power BI analyst. A user builds reports that look correct. An analyst builds reports that are correct — where 'correct' means the visual choice accurately represents the relationship in the data, the model design ensures calculations behave reliably under every filter combination, and the DAX logic is explainable under technical scrutiny.
That distinction matters in interviews because it's the same distinction that matters on the job. Dashboards that mislead — through the wrong visual type, a broken relationship direction, or a Measure that returns unexpected results when a slicer is applied — create worse decisions than no dashboard at all. The hiring manager for a DA role knows this, and the technical screen is designed to surface whether you know it too.
At HéraAI, the Interview Cheatsheet Vault is built to develop exactly this level of tool fluency — not just how to use Power BI, but how to explain and defend every choice you make in it.
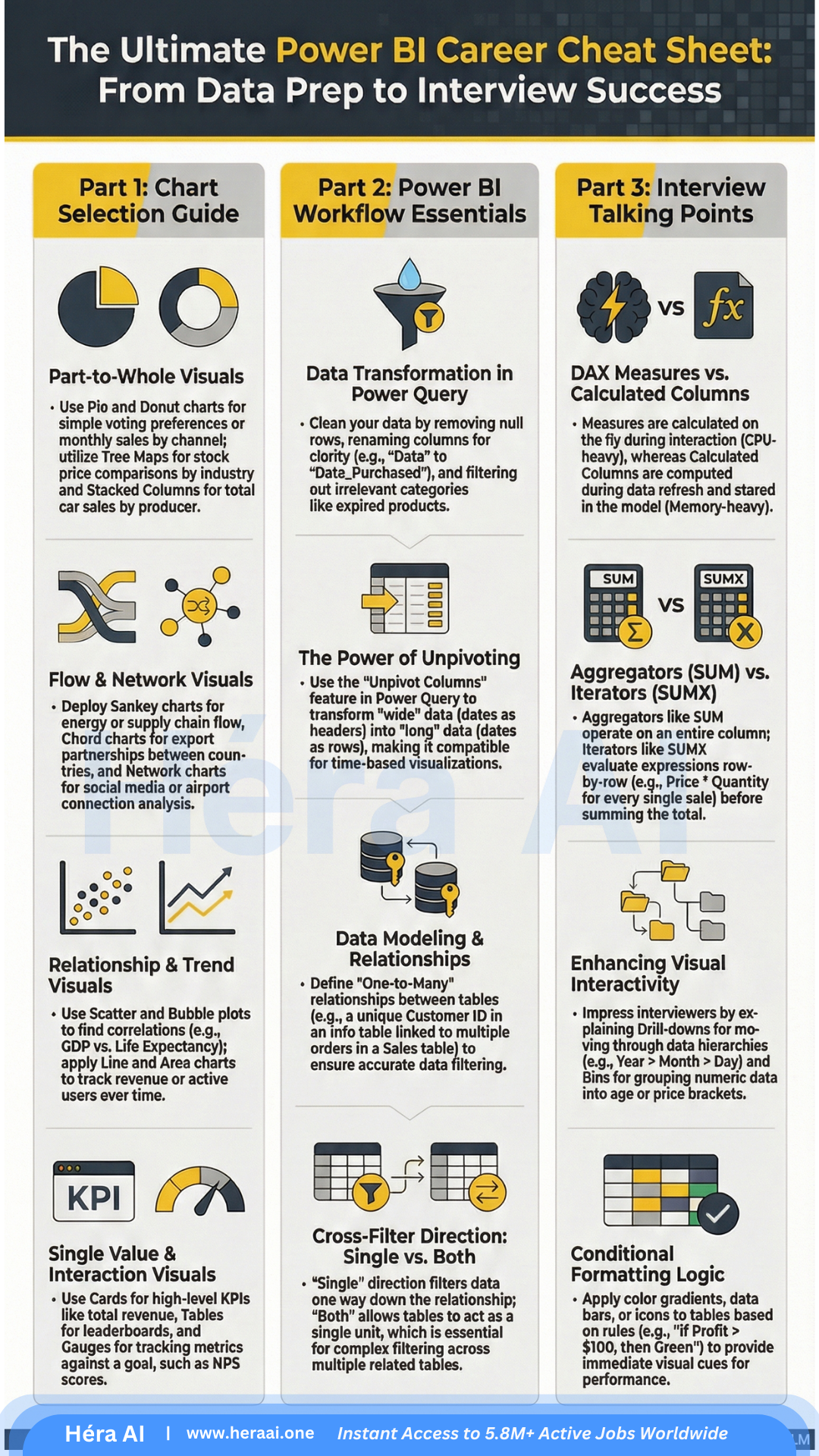
---
# PwC Interview Guide Part 1
Source: articles/interview-vault/pwc-interview-part-1.mdx
First part of comprehensive PwC interview preparation.




---
# PwC Interview Guide Part 2
Source: articles/interview-vault/pwc-interview-part-2.mdx
Advanced PwC interview preparation with complex cases.




---
# Python Interview Playbook 2026
Source: articles/interview-vault/python-interview-playbook-2026.mdx
### The 2026 Python Interview Playbook: From Junior to Architect
Three seniority tiers. Five architectural realities. One concurrency decision framework. Everything you need to pass — and lead — the Python technical interview.
Python's position in the 2026 job market spans three distinct domains — AI and machine learning, data engineering, and web development — and the interview bar in each has risen significantly. 'Knowing Python' is no longer a differentiator at any level. The differentiator is understanding why Python works the way it does: its memory model, its concurrency constraints, its execution pipeline, and the architectural implications of each.
This article covers the full spectrum. Part one maps the topic landscape by seniority level — what interviewers actually probe at each tier, and what signal they're looking for. Part two goes under the hood: five architectural realities that separate candidates who have used Python from candidates who genuinely understand it. Both sections are written as preparation tools, not concept overviews.
#### 1. The Interview Landscape: What Gets Tested at Each Level
Python technical interviews have a clear seniority gradient. Entry-level screens test language mechanics. Mid-level interviews shift to efficiency and API design. Senior and lead interviews probe runtime internals, concurrency architecture, and the reasoning behind design trade-offs. Preparing for the wrong tier — in either direction — is one of the most common ways otherwise qualified candidates underperform.
The table below maps the specific topics that appear at each level, along with the evaluative signal each tier is designed to generate. Use it both as a preparation checklist and as a self-assessment tool for where you currently sit in the spectrum.
The preparation principle across all three tiers: Don't memorise definitions. Prepare to explain mechanisms. 'A generator uses yield to produce values lazily' is a definition. 'A generator avoids loading an entire dataset into memory by generating one value at a time, which matters when processing a 10GB log file that would exceed your available RAM' is a mechanism. Interviewers at every level are probing for the latter.
#### 2. The Ecosystem Layer: NumPy, Pandas, and the Libraries That Signal Depth
Across all three seniority tiers, knowledge of the Python data ecosystem is what interviewers use to separate candidates with genuine applied experience from those with theoretical preparation. Two libraries appear consistently in senior-level job descriptions and interview feedback:
### 3. Python Under the Hood: Five Architectural Realities
The questions that determine senior and lead-level interview outcomes are not about Python syntax. They're about the decisions Python's designers made — and the constraints and capabilities those decisions create for engineers who build systems with it. The five realities below are the most frequently probed topics in senior Python technical screens.
The thread that connects all five: Python's design consistently prioritises developer experience and memory safety over raw performance. Every architectural feature — the GIL, the garbage collector, the __dict__, the PVM — is a deliberate trade-off. Senior candidates who can articulate those trade-offs, and explain when and how to work around them, are demonstrating exactly the judgment that lead-level roles require.
### 4. The Concurrency Decision Framework: Threading, Multiprocessing, or asyncio?
The GIL question almost always leads to a follow-up: 'So when would you use threading vs. multiprocessing vs. asyncio?' This is the practical application that separates candidates who can recite the GIL's definition from those who understand how to architect around it.
The answer is not 'it depends' followed by vague qualifications. It's a clear decision framework based on the nature of the workload — and the ability to explain the mechanism behind each choice.
In practice, these models are often combined. A high-concurrency FastAPI service (asyncio) might spawn multiprocessing workers for CPU-intensive inference tasks, while using threading for database connection pooling. The architectural sophistication is in knowing which tool applies to which layer — and being able to explain why.
The senior-level answer structure: When asked 'how would you handle concurrency in Python?', the strongest responses name the task type first (I/O-bound vs. CPU-bound), identify the appropriate model (threading/asyncio vs. multiprocessing), explain the GIL interaction, and cite a specific use case from their own experience. Four components, in that order.
#### 5. The Mutable Default Argument — Python's Most Common Senior Trap
Of all the Python gotchas that appear in technical interviews, the mutable default argument is the one most consistently used to distinguish mid-level from senior candidates. It's not obscure — but the depth of explanation required at the senior level goes well beyond the typical fix.
### From Coder to Python Architect
The 2026 Python interview market rewards candidates who can move between levels of abstraction fluidly — from the syntax a junior writes, to the memory model that syntax operates within, to the architectural trade-offs that model creates at scale. That fluency is not built by memorising answers. It's built by understanding mechanisms.
The Specializing Adaptive Interpreter and the experimental JIT compiler in Python 3.13 are signals that the language itself is closing the performance gap with compiled alternatives. As that gap narrows, the candidates who thrive will be those who understand both what Python can do today and the direction its architecture is evolving — and who can translate that understanding into systems that perform at production scale.
At HéraAI, the Interview Cheatsheet Vault is built to develop exactly that depth — with Python and SQL references, system design frameworks, and real interview questions from the companies where this level of preparation actually matters.
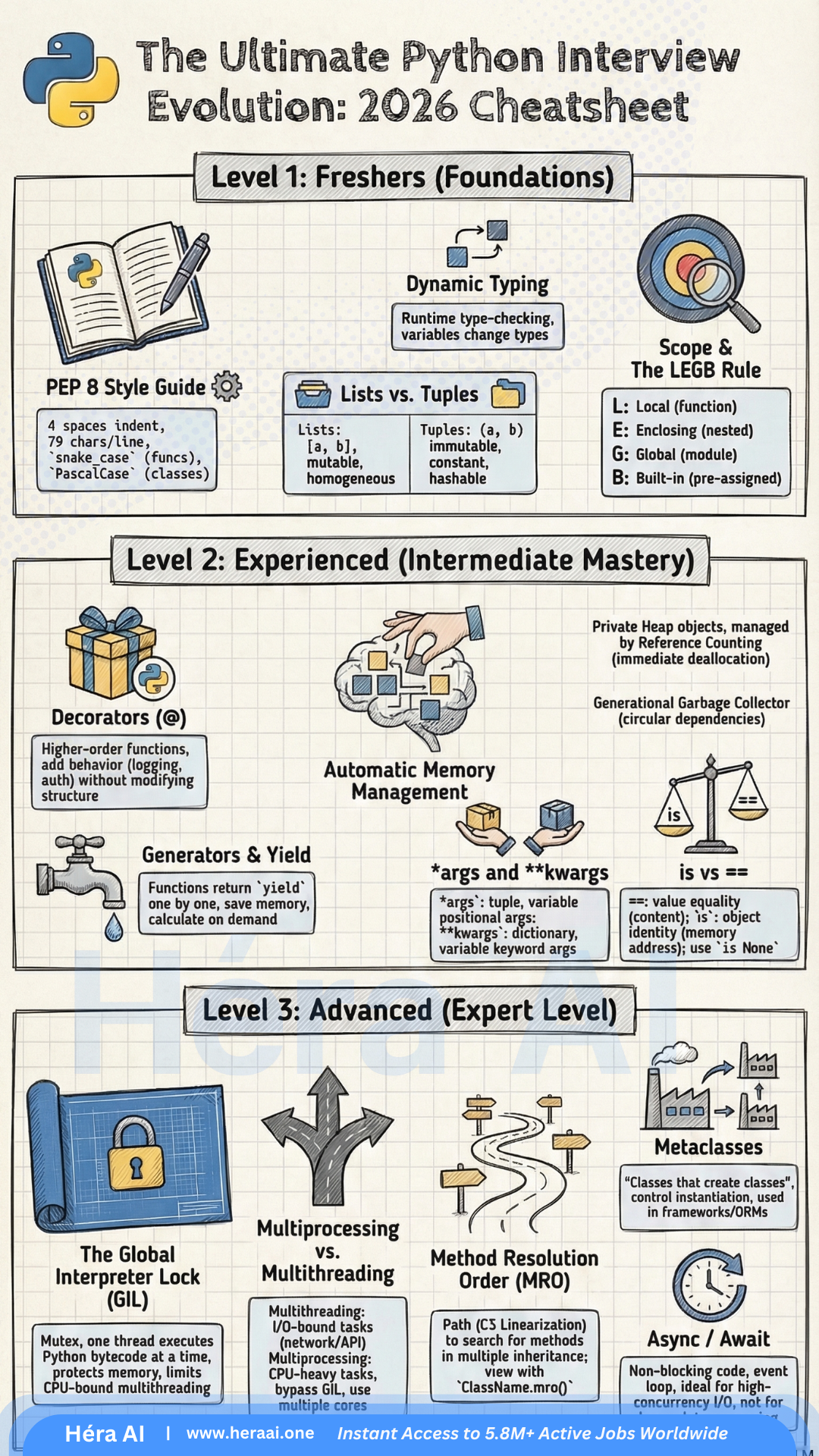
---
# R Programming Interview Guide
Source: articles/interview-vault/r-interview-guide.mdx
10 min read
#### You've Been Learning R Wrong: 4 Insights That Reveal How Experts Actually Think
Most candidates treat R interview prep like a vocabulary test. The engineers who actually get hired think about R completely differently — as a coherent paradigm, not a list of functions to memorize.
Thousands of data candidates list R on their resume. A fraction of them can answer follow-up questions about why R works the way it does — its object philosophy, its data model, its production architecture. The cheat sheet is a map. This article is the territory behind it.
#### 1. The Assignment Operator Is a Philosophy — Not a Syntax Quirk
The cheat sheet opens with the most basic thing in R: `x <- 10`. It looks trivial. It isn't.
In Python, you write `x = 10`. In R, the arrow `<-` signals something structurally different: you are deliberately placing a value into a named object in your environment. This is intentional storage, not implicit assignment. And understanding that distinction changes how you answer interview questions about workflow, reproducibility, and debugging.
The candidates who learned R as 'Python but with weird syntax' never make this connection. The ones who learned R as its own paradigm do — and it's visible within the first two minutes of an interview.
#### 2. The Pipe Operator Is the Most Underrated Interview Signal of All
Most candidates know the pipe exists. Far fewer use it the way interviewers are watching for.
The `%>%` operator from magrittr — and the native `|>` introduced in R 4.1 — isn't a shortcut. It's a readability philosophy. Interviewers aren't checking whether you know it. They're watching how naturally you chain operations — and whether your code looks like something a human can maintain.
#### 3. The dplyr / tidyr Gap Is Where Most Analysts Get Stuck — and Where Interviewers Probe Hardest
The cheat sheet separates Data Manipulation (dplyr) from Data Tidying (tidyr) into two distinct sections. This isn't cosmetic. It reflects two completely different mental operations — and most candidates have only practiced one of them.
#### 4. The Jump from Analyst to Engineer Happens at purrr, Shiny, and Quarto
Most candidates stop at ggplot2. They can make a scatter plot and a bar chart. That's table stakes for an analyst role — necessary, but not differentiating. The tools that move you into senior or engineering-adjacent roles are in the bottom half of the cheat sheet.
#### Memorizing Syntax Won't Get You Hired. Having a Mental Model Will.
The R Interview Cheat Sheet is a map. But the territory is your ability to reason about data, communicate about decisions, and write code that other humans can maintain and trust. Those capabilities don't come from memorizing function signatures.
At HéraAI, we help professionals build that deeper layer — not just what to know, but how to think in the tools that actually matter in production.
#### Next issue: Python vs. R in 2026 — which one should you actually prioritize for your data career?
Subscribe. We cut through the noise so you don't have to.
— HéraAI Team
---
# RAG (Retrieval-Augmented Generation) Interview Guide
Source: articles/interview-vault/rag-interview-guide.mdx
10 min read
#### The AI Engineer's Survival Guide: 4 RAG Truths That Separate Hired Candidates from the Rest
In 2026, companies aren't just hiring engineers who can prompt an LLM. They're hiring engineers who can build reliable, grounded, and production-ready systems. That system is RAG — and most candidates can't explain it past the acronym.
The AI job market has shifted faster than most candidates' preparation has. Retrieval-Augmented Generation is no longer a niche architecture topic — it's a baseline expectation for any engineer building AI-powered products. At HéraAI, we've analyzed over 100 technical interview patterns to identify exactly what separates candidates who understand RAG conceptually from those who've built it in production. Here are four truths you need before your next interview.
#### 1. RAG Exists Because LLMs Alone Aren't Production-Ready — Know Why
Most candidates describe RAG as 'connecting an LLM to a database.' That's not wrong, but it's the kind of answer that gets you to the next question — not the offer. The answer that signals production experience explains the problem RAG solves: knowledge cutoffs and hallucination.
LLMs are powerful but frozen in time. They generate text that sounds authoritative, even when it's wrong. RAG solves both problems by providing a live connection to external, authoritative data at inference time — without the cost and latency of retraining.
#### 2. The RAG Workflow Has Five Stages — Weak Candidates Collapse Them Into Two
Ask most candidates to walk through RAG and they'll say: 'You retrieve relevant chunks and feed them to the LLM.' That's stages 2 and 3 of 5. The stages they skip are exactly the ones that fail in production.
#### 3. Search Is Not One Thing — and Hybrid Is the Production Standard
A question that consistently trips up mid-level candidates: 'What's the difference between sparse and dense retrieval?' The answer matters because the retrieval layer is where most RAG systems quietly fail.
### 4. Evaluation Is the Skill That Separates Engineers from Prototypers
You can build a RAG demo in an afternoon. Building one that you can prove is working — and diagnose when it isn't — is what companies are actually hiring for. That requires fluency in the RAG Triad.
Most candidates have heard of these metrics. Few can explain what a low score on each one means diagnostically — and that's the follow-up question interviewers always ask.
#### The Engineers Who Get Hired Can Explain What Breaks — Not Just What Works
RAG is no longer a differentiator on its own. In 2026, virtually every AI product team has a RAG system. What differentiates candidates is the ability to reason about failure: why retrieval returns noise, why generation drifts from context, and how to measure it systematically.
At HéraAI, that's the level of production-grade thinking we help engineers develop — not just the architecture, but the diagnostic mindset behind it.
Next issue: Advanced RAG architectures: Agentic RAG, self-querying retrievers, and graph-augmented retrieval — what the next interview frontier looks like.
Subscribe. We cut through the noise so you don't have to.
— HéraAI Team
---
# Software Engineer Interview Cheatsheet
Source: articles/interview-vault/swe-interview-cheatsheet.mdx
### The 2026 Technical Interview Power-Sheet: From Application to Offer
Resume optimization, coding execution, system design, and negotiation — the complete playbook for US software engineering interviews.
The software engineering interview process in 2026 is a four-stage evaluation. Each stage tests something different — and failure at any one of them ends the process, regardless of how well you perform in the others. A candidate with a weak resume doesn't get to the coding screen. A candidate who codes correctly but can't explain their reasoning doesn't advance to system design. A candidate who clears all three technical rounds but negotiates poorly leaves money on the table.
This article consolidates the complete framework: resume and ATS optimization, the whiteboard coding protocol, junior system design fundamentals, behavioral storytelling, and offer negotiation strategy. It's designed as a reference you return to at each stage of the process — not a one-time read.
### 1. Resume and ATS Mastery: Getting Into the Process
The resume is not a record of what you've done. In a 2026 hiring context, it's a document optimized to pass two filters sequentially: an AI-driven Applicant Tracking System (ATS) that extracts structured information from your text, and a human recruiter who typically spends 15–30 seconds on an initial scan. Both filters must be cleared before any technical evaluation begins.
The most common failure mode is prioritising aesthetics over information density. Fancy templates, graphics, and non-standard layouts actively harm ATS extraction. The system is looking for structured data — job titles, company names, dates, and skills — and non-standard formatting breaks the parsing logic.
The impact bullet formula: [Strong action verb] + [specific system or tool] + [measurable outcome] + [scale or context]. Every bullet that doesn't follow this structure is leaving evidence of your capability on the table.
### 2. The Whiteboard Coding Workflow: Six Steps, No Skipping
Technical coding interviews evaluate two things simultaneously: your ability to solve algorithmic problems, and your ability to communicate your reasoning under pressure. Most candidates focus exclusively on the first and neglect the second. The whiteboard coding workflow below addresses both.
The six steps are not optional enhancements to a coding session — they are the session. Interviewers at top-tier companies are explicitly trained to score candidates on each of these dimensions, not just on whether the final code runs correctly.
The time allocation principle: A 30-minute coding problem should be approximately: clarify (2 min) → plan and brute force (4 min) → code (15 min) → dry run (5 min) → complexity analysis (3 min) → optimize (remainder). Deviating significantly from this distribution is one of the most common reasons technically capable candidates receive mixed feedback.
### 3. Junior System Design Fundamentals
System design interviews are often perceived as the exclusive domain of senior engineers. In 2026, they appear at the junior level with increasing frequency — particularly at larger companies and high-growth startups. The expectation isn't architectural mastery. It's structured thinking about how a request moves through a system and where problems can emerge.
The three core concepts below form the foundation of every junior system design conversation. Understanding them at the level of articulate explanation — not just recognition — is what the interview is testing.
### Essential Performance Metrics — What Interviewers Expect You to Know
The system design principle for junior candidates: You won't be expected to architect a distributed database from scratch. You will be expected to explain what happens when a user clicks 'submit' on a form — from the client, through the load balancer, through the backend, into the cache, and finally to persistent storage. Know that flow cold.
### 4. Behavioral Interviews: The STAR Method, Applied Correctly
Behavioral interviews are scored with the same rigor as technical rounds at most top-tier companies. The STAR method — Situation, Task, Action, Result — is the expected structure, and interviewers are trained to detect whether candidates are following it deliberately or answering unstructured.
The most important nuance in applying STAR is the distinction between what the team did and what you specifically did. 'We redesigned the architecture' is not an answer. 'I designed the caching layer, which reduced database load by 40%' is an answer. The Task and Action sections must be singular and personal.
### 5. Offer Negotiation Strategy: From Offer to Final Number
Negotiation is the stage most candidates are least prepared for — and the one that has the largest single-conversation financial impact. A 10-minute negotiation conversation can be worth $10,000–$30,000 in base salary, plus compounding effects on equity grants, bonuses, and future raises that are anchored to your base.
The rules below are not theoretical. They reflect the actual dynamics of how compensation offers are structured and how recruiters are trained to respond.
The preparation you need before any negotiation conversation: Know the market rate for your target role in your target geography — from Levels.fyi, Glassdoor, and LinkedIn Salary. Know your number, your walk-away point, and at least one genuine competing signal (even an informal interview invitation). Enter the conversation knowing what outcome you're trying to achieve.
### 6. The Three Common Pitfalls That Eliminate Capable Candidates
Technical interviews don't only select for the best engineers. They also filter out candidates who make specific, avoidable process errors — regardless of their actual ability. The three pitfalls below eliminate otherwise qualified candidates at every company, at every level, in every interview cycle.
The meta-skill that prevents all three: Time management across the interview. A candidate who is conscious of where they are in the conversation — and actively manages their pacing — is significantly less likely to commit any of these errors. Before each section of the interview begins, set a mental clock.
### From Application to Offer: The Complete Process
The software engineering interview loop rewards candidates who prepare systematically across all four stages — not candidates who have a strong coding session but neglect behavioral prep, or who clear every technical round and then mismanage the negotiation.
The framework in this article is not exhaustive — every company runs a slightly different process, and every interviewer brings their own emphasis. But the fundamentals it covers appear, in some form, at every company at every level: resume clarity, structured coding communication, system design awareness, behavioral storytelling, and negotiation discipline.
At HéraAI, the Interview Cheatsheet Vault is built to operationalize exactly this kind of systematic preparation — with SQL and Python references, behavioral question banks, and company-specific interview intelligence for every stage of the process.
---
# Canadian Resume Template - North American Standards
Source: articles/resume-lab/canadian-resume-template.mdx
10 min read
The Generic Resume Is a Career Trap: The Major-Specific Blueprint That Actually Gets Canadian Interviews
You spent four years building highly specialized knowledge. Then you submitted a resume that could have been written by anyone. In a market where Scotia Capital, Deloitte, and KPMG process hundreds of applications per opening, that's a disqualifying signal — and it's entirely fixable.
The candidates who break through in the Canadian job market aren't the ones with the most experience. They're the ones who've learned to speak their industry's specific dialect from the very first line of their application. Specificity isn't a stylistic preference — it's the entire competitive strategy. Here's how to execute it across every layer of your application.
#### 1. Every Major Has a Set of 'Industry Ingredients' — Employers Scan for Them in Seconds
The most underutilized piece of career intelligence available to any graduate is this: hiring managers in different fields are scanning for completely different signals. Not 'skills' in the abstract — specific technical markers that immediately communicate professional readiness. A resume without them reads as entry-level regardless of academic achievement.
#### 2. The Accomplishment Formula — Why 'Did Research' Is Costing You Interviews You Deserve
There is a phrase pattern that appears across the majority of student resumes, across every major, every university, every year. It sounds professional. It is quietly devastating to your application.
The formula that changes the equation: Action Verb + Context and Scope + Quantifiable Result. The transformation isn't cosmetic — it's a signal that reframes you from presence to contributor.
#### 3. Your Coursework Is More Powerful Than You've Been Told — If You Frame It Correctly
For candidates without extensive full-time work history, the project experience section of a resume can be the single most powerful differentiator — if it's treated with the same rigor as a professional role. Not as supplementary. Not as 'Academic Projects' in a smaller font at the bottom of the page.
As primary evidence of professional capability, presented with the same structure as employment experience: scope, methodology, output, and outcome. The section title is Relevant Experience — not 'Academic Projects,' not 'Coursework.'
#### 4. The Cover Letter Is Not a Resume Summary — It's the Bridge to Culture Fit
Most graduates treat the cover letter as an obligation — a slightly more personal version of the resume's top section, restating credentials and expressing enthusiasm. This approach leaves the most valuable real estate in the entire application completely unused.
A resume proves capability. A cover letter proves fit. Its actual function is to do something a resume structurally cannot: demonstrate values alignment. And in 2026, across firms like KPMG and Deloitte that publish explicit organizational values, generic enthusiasm is immediately distinguishable from genuine research.
### Specificity Is the Entire Competitive Advantage
Every insight in this breakdown points to the same root principle. The candidates who succeed in the Canadian job market — at every experience level, across every major — are the ones who've replaced generic with specific at every layer of their application. Specific technical vocabulary. Specific quantified outcomes. Specific project framing. Specific cultural alignment.
At HéraAI, we work with candidates who are ready to stop broadcasting their history and start marketing their specific value to the specific employers who need it.
Next issue: The informational interview playbook — how one 20-minute conversation can put you in front of a hiring manager before a role is ever posted.
Subscribe. Always free. Always actionable.
— HéraAI Team
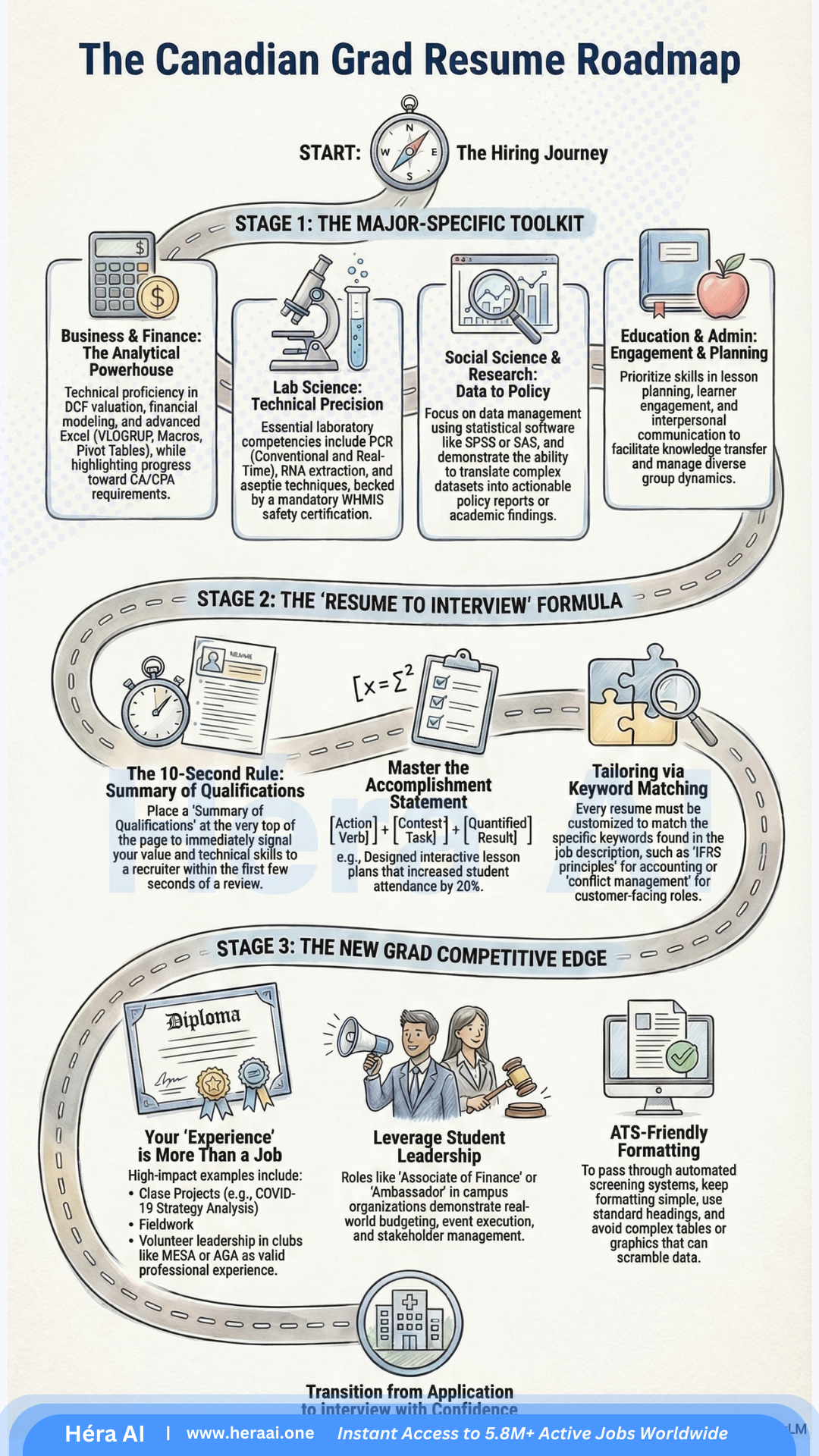
---
# CMU Computer Science Resume Template
Source: articles/resume-lab/cmu-cs-resume-template.mdx
#### Resume Architecture Lab · COMPUTER SCIENCE· CMU Career Framework
#### Beyond the Code: The CMU Blueprint for the AI-Powered Technical Job Search
Carnegie Mellon's career framework distilled into three pillars, one impact formula, and a four-part AI co-pilot strategy for CS students and software engineers.
Landing a top-tier software engineering offer requires more than technical ability. It requires a resume that communicates impact with precision, a job search strategy that uses available tools intelligently, and the discipline to distinguish between authentic self-presentation and AI-generated noise.
Carnegie Mellon University's career guidance for CS students is built around a deceptively simple insight: the difference between a resume that gets a callback and one that doesn't is usually not experience — it's evidence. Most CS resumes describe what students were responsible for. The strongest ones prove what those students delivered.
This article covers the full CMU framework: three core resume pillars, the XYZ impact formula, and a structured approach to using AI as a career co-pilot without losing the authenticity that wins at the interview stage.
#### 1. The CMU Standard: Three Pillars of a Winning CS Resume
CMU's career framework for technical students is built around three non-negotiable pillars. Each addresses a distinct failure mode: the first corrects responsibility-based bullet points, the second addresses the common underutilisation of technical and project work, and the third targets the formatting and tailoring decisions that determine whether a resume gets read at all.
The framing that matters: A resume is a marketing document, not a biography. Every line should answer the question a recruiter is implicitly asking: 'What did this person actually deliver, and is it relevant to the role I'm hiring for?' Lines that don't answer that question shouldn't be there.
#### 2. The XYZ Impact Formula: How to Write Every Bullet
The most operationally specific guidance in the CMU framework is the XYZ formula for bullet points: 'Accomplished [X] as measured by [Y] by doing [Z].' It's a three-part structure that forces precision at every stage — what you did, how you know it worked, and how specifically you did it.
The formula addresses the single most common weakness in CS resumes: responsibility language. Responsibility language describes what a role involves. Impact language proves what a specific person delivered. The XYZ structure makes impact language the default, not the exception.
The three components combine into a single bullet: 'Reduced API response latency for the primary checkout service by 20%, from 340ms to 270ms under peak load, by implementing a Redis caching layer with a 5-minute TTL policy.' Every word is doing work. The recruiter knows the system, the result, and the method — in one sentence.
Finding your Y when you don't have a metric: Not every project produces a clean percentage. Acceptable Y values include: test coverage increased from 60% to 90%, deployment time reduced from 45 minutes to 8 minutes, API errors reduced from 12 per hour to 0 after fix, or feature adopted by 3 internal teams within one sprint. The number doesn't have to be dramatic — it has to be real and specific.
### 3. Technical Depth: Making Your Skills Section Work Harder
For CS students and recent graduates, the Skills section is often treated as a quick list to fill space. In practice, it's one of the most important ATS-facing elements in the document — and one of the most consistently misformatted.
The CMU standard organizes technical skills into named categories rather than a flat list. This structure serves two purposes: it makes extraction by ATS systems more reliable, and it signals to a human reviewer that you understand the distinctions between different classes of technical capability.
### 4. Class Projects as Professional Evidence
The most common mistake CS students make with project experience is understating it. A well-documented class project — with a named problem, a specific technical approach, measurable outcomes, and a team scope — is direct evidence of the same capabilities that internship experience demonstrates.
The key is presentation. A project listed as 'Group assignment using React and Node.js' communicates almost nothing. The same project presented as 'Built a full-stack task management application for a 4-person team using React, Node.js, and PostgreSQL, reducing manual project tracking time by 60% through automated status updates and Slack integration' is a professional evidence statement.
The project presentation standard: For every project you list, answer four questions: What problem did it solve? What did you specifically build? What technologies did it use? What was the measurable outcome? If you can't answer all four, the project isn't ready to be on your resume yet — go back and document it properly.
### 5. AI as Career Co-Pilot: Four High-Value Applications
CMU's guidance on AI in the job search reflects a clear position: AI tools are a starting point and a revision tool, not a replacement for original thinking. The distinction matters because the resume gets you through the door, but authenticity wins the interview. A resume written entirely by AI — with no genuine grounding in your actual experience — will fall apart at the first follow-up question.
Used correctly, AI accelerates four specific parts of the job search process. Each has a clear use case, a concrete expected output, and a caveat that determines whether the output is useful or dangerous.
The ethical boundary that protects you: AI tools can suggest skills, rephrase bullets, and generate questions. They cannot invent experience you don't have. Every claim on your resume must be something you can discuss in depth, defend under pressure, and verify if asked. The resume gets you the interview. Your actual knowledge and experience determine everything that happens after.
#### 6. Where CMU Fits in the Resume Architecture Lab Series
CMU's framework is the sixth model in HéraAI's Resume Architecture Lab series. Each framework adds a distinct layer to a complete resume strategy. Together, they cover every dimension of the document — from micro-level bullet construction to macro-level document architecture, from market-specific calibration to AI-enhanced optimization.
CMU's specific contribution to the series is the intersection of technical precision and AI strategy. Where Princeton provides the sentence-level formula and MIT provides the document-level architecture, CMU provides the CS-specific application of both — and adds the AI co-pilot layer that no other framework addresses directly.
### The Resume That Gets You Through the Door
The CMU framework closes with a principle that applies across every resume model in this series: the resume is a marketing document with a single objective — to generate an interview invitation. It doesn't need to tell your full story. It needs to make a targeted, evidence-based case that you are worth an hour of a hiring manager's time.
The XYZ formula, the three pillars, and the AI co-pilot strategy are all in service of that single objective. Used together, they produce a document that is precise, credible, and tailored — which is the standard the 2026 technical hiring market actually requires.
At HéraAI, the complete Resume Architecture Lab series — Princeton through CMU — is built to develop exactly that standard. Each framework is a tool. The strategy is knowing when and how to use each one.

---
# University of Melbourne Resume Template
Source: articles/resume-lab/melbourne-resume-template.mdx
#### Resume Architecture Lab · Australian Market · University of Melbourne Framework
### The Achievement-Based Resume: What the Australian Job Market Actually Rewards
54.1% of applicants walk into interviews without researching the company. The Melbourne framework is built around exactly that gap.
Writing a resume often feels like sending a carefully crafted document into a void. Most candidates follow a template, list their experience in reverse chronological order, and hope the content speaks for itself. The University of Melbourne's career development framework starts from a different premise: a resume is a marketing document, and like any marketing, it requires both a clear value proposition and evidence that the proposition is credible.
What makes Melbourne's approach particularly actionable — especially for the Australian market — is its emphasis on company research as a direct competitive advantage. The data point is striking: 45.9% of candidates walk into applications without a genuine understanding of the organisation they're targeting. That means demonstrating real market awareness immediately places you in the top half of any applicant pool, before the interview even begins.
This article breaks down Melbourne's framework into its four structural components and explains how to apply each one in practice.
#### 1. The Mindset Shift: You Are a Product — Your Resume Is the Pitch
The framing that anchors Melbourne's framework is simple but consequential: stop thinking of your resume as a record of what you've done, and start thinking of it as a pitch for what you can do for a specific employer.
That shift has practical implications for every decision you make in drafting the document. A record-based resume asks: what did I do in each role? A pitch-based resume asks: what does this employer need, and which of my experiences most directly proves I can deliver it?
The operative concept is transferable skills — capabilities that cross role boundaries and industry lines. Leadership developed running a student association is as relevant to a graduate recruitment process as leadership developed in a paid management role, if it's framed with the same evidence standard: specific context, measurable outcome, demonstrated impact.
The filter to apply to every section: Before including any piece of information, ask — 'Does this prove I can deliver something this employer values?' If the answer is no, cut it. If the answer is yes, make sure it's supported by a number or a specific outcome.
### 2. The Gold Standard Structure: Four Sections, Precisely Sequenced
Melbourne's framework specifies not just what to include, but how to sequence and position each section for maximum impact. The architecture matters because recruiters scan in a predictable pattern — top-left to right, then down. What appears first and where it appears shapes what gets read and remembered.
On the Profile section specifically: This is the most underutilised section on most graduate resumes and the highest-leverage real estate on the page. Three to four lines, written specifically for this role, that immediately signal you understand what the employer is looking for — not a generic summary of your personality type.
### 3. Quantify Everything — And Then Quantify Again
The Melbourne framework's most direct instruction is also its most impactful: numbers provide immediate credibility. A bullet point with a percentage, a user count, a dollar figure, or a timeframe is processed differently by a recruiter's brain than one without. It signals not just that something happened, but that you were paying attention to whether it worked.
This is the mechanism behind the achievement-based approach: outcomes are inherently quantifiable, while duties are not. 'Managed the club's social media accounts' is a duty. 'Grew Instagram engagement by 40% over two semesters by introducing a weekly content calendar and partnerships with three campus societies' is an achievement.
The test: Read each bullet point and ask — 'How would I know this was successful?' The answer to that question is the number you're missing. Find it and add it.
#### 4. The 45.9% Advantage: Company Research as a Resume Strategy
The statistic the Melbourne framework highlights — that fewer than half of applicants genuinely understand the company they're applying to — is one of the most actionable data points in career development. It means that demonstrating real market awareness is a differentiation strategy available to almost any candidate, regardless of their experience level.
In practice, this shows up in two ways on the resume: in the Profile section (where you can reference specific aspects of the organisation's direction or challenges) and in the cover letter (where you can demonstrate knowledge of their competitive landscape, recent news, or product strategy).
The practical application: in your Profile section, replace generic descriptors with language that reflects the organisation's own priorities. If a company's latest annual report emphasises 'operational efficiency' and 'digital transformation,' those phrases belong in your profile — because they're the recruiter's filter language.
### 5. Building Experience When You Don't Have 'Traditional' Experience
One of the most common concerns among graduate candidates and career changers is the perceived gap between their current background and the experience requirements in job postings. Melbourne's framework addresses this directly: the evidence standard is what matters, not the employment status of the experience.
Group assignments, independent research projects, case competitions, student society leadership, and volunteer roles all qualify — if they're presented with the same rigor as paid work: specific context, measurable outcome, transferable skill.
The reframe that matters: Employers aren't looking for a specific employment history. They're looking for evidence that you can do the work. Your job is to produce that evidence, whatever its source.
### 6. Where Melbourne Fits in the Resume Architecture Series
This article is the fourth installment in HéraAI's Resume Architecture Lab series. Each framework we've examined adds a distinct layer to a complete resume strategy.
The Melbourne framework's specific contribution is twofold: it provides the most actionable guidance for candidates without extensive work experience, and it adds the Australian market context that North American frameworks don't address — particularly the emphasis on company research as a direct differentiator in local hiring pipelines.
### The Resume That Proves What You Can Do
The University of Melbourne's career framework closes with a deceptively simple standard: a great resume doesn't just say what you did. It proves what you can do for your future employer.
That distinction — between a record and a proof — is what separates the candidates who get called back from those who don't. It requires deliberate translation of your experience into evidence, and deliberate research into what each specific employer is actually looking for.
Neither of those things is easy. But both are learnable skills — and both are exactly what the HéraAI Resume Architecture Lab is built to develop.
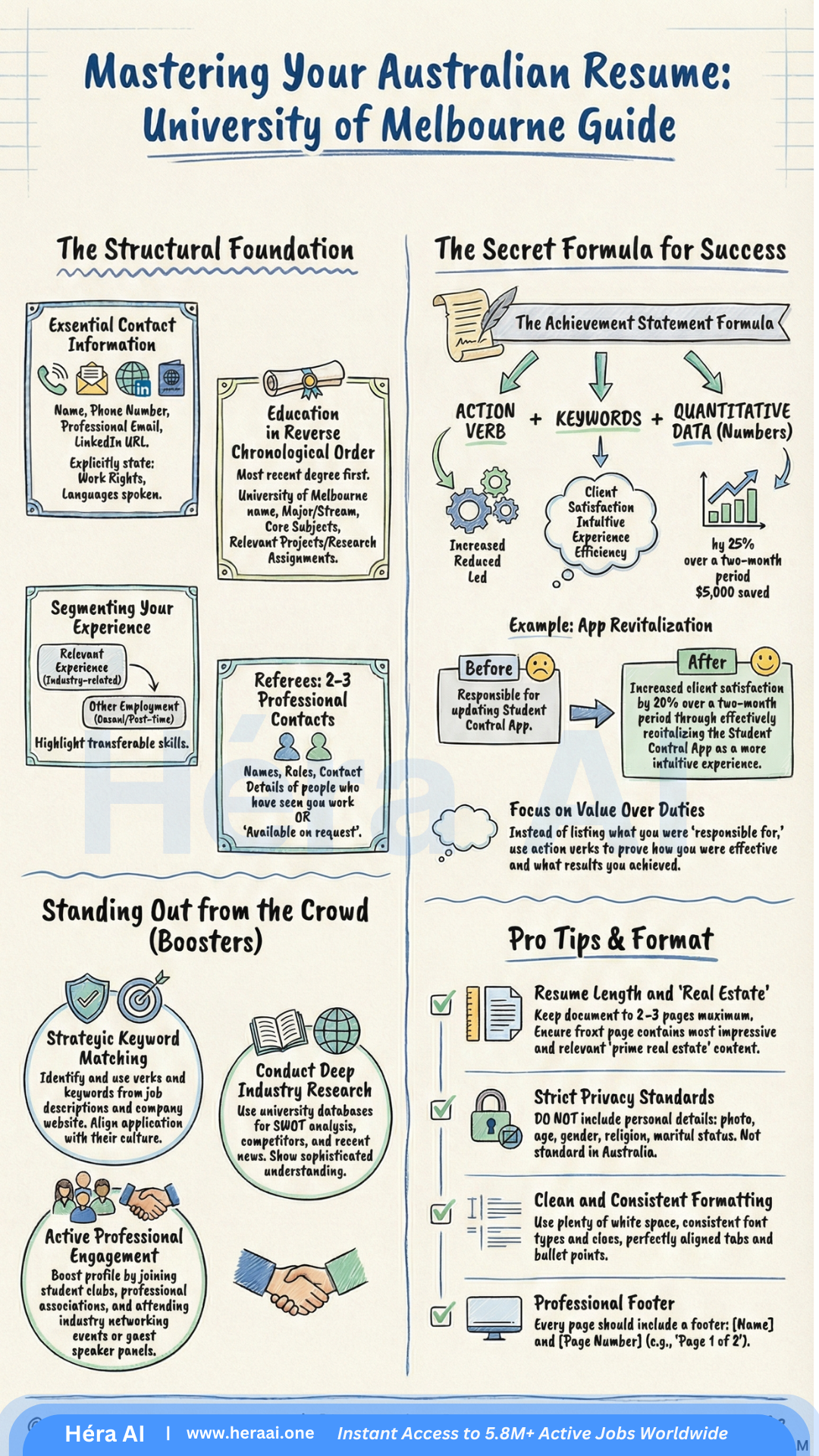
---
# MIT Resume Template - Academic Excellence Showcase
Source: articles/resume-lab/mit-resume-template.mdx
#### Resume Architecture Lab · Industry Blueprints · MIT Career Model
#### Strategic Resume Engineering: What MIT's Career Model Reveals About Standing Out
MIT's sample resumes aren't just polished documents — they're blueprints for how top candidates engineer their professional narrative for each target industry.
Most candidates write one resume and send it everywhere. MIT's approach to career development starts from the opposite premise: the layout, emphasis, and language of your resume should change based on who's reading it and what they're hiring for.
By analyzing the sample resumes published by MIT Career Advising & Professional Development, a clear pattern emerges. These documents aren't just records of experience — they're engineered arguments for why a specific candidate is the right fit for a specific role. Each industry has its own signal language, its own hierarchy of credibility, and its own standard for what 'impact' looks like on paper.
Here's what that looks like in practice — and how any candidate can apply the same logic to their own resume.
### 1. Industry-Specific Blueprints: What to Lead With and Why
The most important structural insight from the MIT model is that the content hierarchy of a resume — what appears first, what gets the most space, what metrics are featured — should be determined by the reader's priorities, not the writer's preferences.
Each industry rewards a different kind of proof. Here's how MIT's samples map that out:
The pattern across all four: every resume leads with the type of evidence that matters most to that specific audience. Tech hiring managers scan for technical depth and real-world scale. Consulting interviewers look for quantified business impact. Engineering teams want process outcomes and tool fluency. Real estate and public sector evaluators weight budget authority and stakeholder management.
The core principle: Your resume doesn't have to list everything you've done. It has to lead with the evidence that is most credible to the specific person reading it. Everything else is secondary.
### 2. From Historical Record to Value Proposition
The MIT approach reframes the fundamental purpose of a resume. Most candidates treat it as a historical document — a backward-looking record of positions held and responsibilities carried. MIT's Career Advising framework treats it as a forward-looking value proposition: evidence that you will generate the outcomes this employer cares about.
That shift in framing has three concrete implications:
The reframe that changes everything: A resume that describes what you did is competing with every other candidate who held a similar role. A resume that proves what you delivered is competing in a much smaller pool.
### 3. Five Strategies Any Candidate Can Apply Today
The MIT model isn't exclusive to Ivy League graduates or candidates with exceptional work histories. The strategic logic is universally applicable. Here are the five highest-leverage tactics, translated into actionable steps.
On the Projects section specifically: A well-documented project — Sentiment Analysis Stock Prediction, an Autonomous UAV build, a LangChain conversational agent — demonstrates exactly what employers most struggle to assess in interviews: your ability to apply knowledge to an ambiguous, real-world problem. Build it, document it, and own it on your resume.
#### 4. The MIT Model in Comparison: How It Extends the Princeton ACE Framework
Readers who followed our earlier breakdown of the Princeton Career Development framework will recognize a consistent throughline: both models treat the resume as an engineered argument, not a formatted biography.
Where Princeton's ACE model (Action → Context → End Result) gives you the micro-level tool for writing individual bullet points, the MIT model provides the macro-level blueprint for how to architect the entire document around a specific industry and audience.
The result is a resume that functions at two levels simultaneously: it passes the 15-second scan by surfacing the right signals in the right hierarchy, and it holds up under detailed review by demonstrating depth, specificity, and real-world judgment.
### Engineering Your Resume Is a Learnable Skill
The candidates who land offers at highly competitive organizations aren't always the ones with the most impressive raw experience. They're the ones who've learned to translate their experience into the specific language of value that each employer is looking for.
The MIT model makes that translation systematic. It gives you a framework for reading the audience, selecting the right signals, and organizing your evidence in a hierarchy that earns attention in the first 15 seconds and justifies it in the next 15 minutes.
At HéraAI, the Resume Architecture Lab is built around exactly this kind of strategic translation — from what you've done, to why that makes you the right hire.

---
# Princeton Resume Template - Ivy League Standards
Source: articles/resume-lab/princeton-resume-template.mdx
#### Resume Architecture Lab · Frameworks & Strategy · Princeton RESUME Model
#### Beyond the Template: How to Engineer a Resume That Actually Gets Read
Your resume isn't a record of what you've done. It's a marketing document that answers one question: why should we hire you over everyone else?
Most candidates approach resume writing the wrong way. They treat it as a historical document — a chronological record of jobs and responsibilities. Recruiters don't read it that way. They're scanning for evidence that you can solve their specific problem.
The Princeton Center for Career Development frames this precisely: a resume is a dynamic marketing tool, not a static list of duties. And like any good marketing, it requires strategy — a framework for translating your experience into the language of business value.
This article breaks down that framework, including the specific structural decisions that separate a resume that gets a callback from one that gets archived in 15 seconds.
#### 1. The ACE Framework: Stop Listing Duties, Start Proving Value
The single most effective structural change you can make to a resume is replacing duty-based bullet points with what Princeton's career framework calls Action-Oriented Accomplishment Statements — structured around three components.
The logic is simple: duty-based bullets describe what you were supposed to do. ACE-formatted bullets prove what you actually delivered. Recruiters are trying to predict your future performance — and demonstrated outcomes are a far more credible signal than a job description restated in first person.
The test: Read each bullet point and ask — 'Could this sentence appear on anyone's resume, or does it describe a specific, measurable thing I personally did?' If it's the former, rewrite it with ACE.
#### 2. Industry vs. Research: Your Resume Structure Should Match Your Target Audience
One of the most common resume mistakes is using the same document structure for every application. The hierarchy of information that impresses a hiring manager at a tech company is fundamentally different from what impresses a research faculty committee.
Princeton's career framework is direct on this point: resume architecture should change based on your target audience. Here's how that plays out in practice.
The underlying principle: every section header and every piece of information on your resume is a signal about what you think the reader values most. Misaligning that signal — leading with research publications for an engineering role, or leading with technical tools for an academic position — tells the reader you don't understand their context.
Practical rule: Before finalizing any resume, identify the single most important credential for that specific role. That credential should appear in the top third of the first page. Everything else is supporting evidence.
#### 3. Transferable Skills: The Answer to 'I Don't Have Enough Experience'
The most common concern among early-career candidates — and many career changers — is a perceived lack of relevant experience. The Princeton framework addresses this directly: the problem is rarely a lack of experience. It's a failure to translate existing experience into the language of the target role.
Transferable skills are the bridge. Leadership developed on a varsity rowing team, time management built through choreographing a dance production, cross-functional coordination from organizing a campus event — these are not filler content. They are evidence of capabilities that employers value and cannot easily test for in a technical interview.
The reframe: You don't need a longer resume. You need a more strategically translated one. Every experience you've had contains transferable evidence — the skill is learning to surface it in the right language for the right audience.
#### 4. Final Polish: The Formatting Decisions That Affect the 15-Second Scan
Resume content is only half the equation. The way information is organized and presented determines whether a recruiter reads it at all. The research on recruiter behavior is consistent: the average initial scan lasts 15 to 30 seconds. In that window, they're not reading — they're pattern-matching against mental criteria.
The formatting decisions that most affect that scan:
The 15-second test: Print your resume, set a 20-second timer, and look away. When the timer goes off, look at the page and note what your eye lands on first. If it's not your strongest credential for that role, restructure the document until it is.
#### Your Resume Is a Work in Progress — Treat It That Way
The Princeton framework's most important insight isn't a formatting rule or a writing technique. It's a mindset: your resume is never finished. It evolves as your experience deepens, as your target roles shift, and as your understanding of what a specific employer values becomes more precise.
The candidates who consistently outperform in competitive hiring processes aren't the ones with the most impressive backgrounds. They're the ones who invest in translating their backgrounds with the most precision — who understand that a resume is not a record, it's an argument.
At HéraAI, building that argument is exactly what the Resume Architecture Lab is designed to help you do.
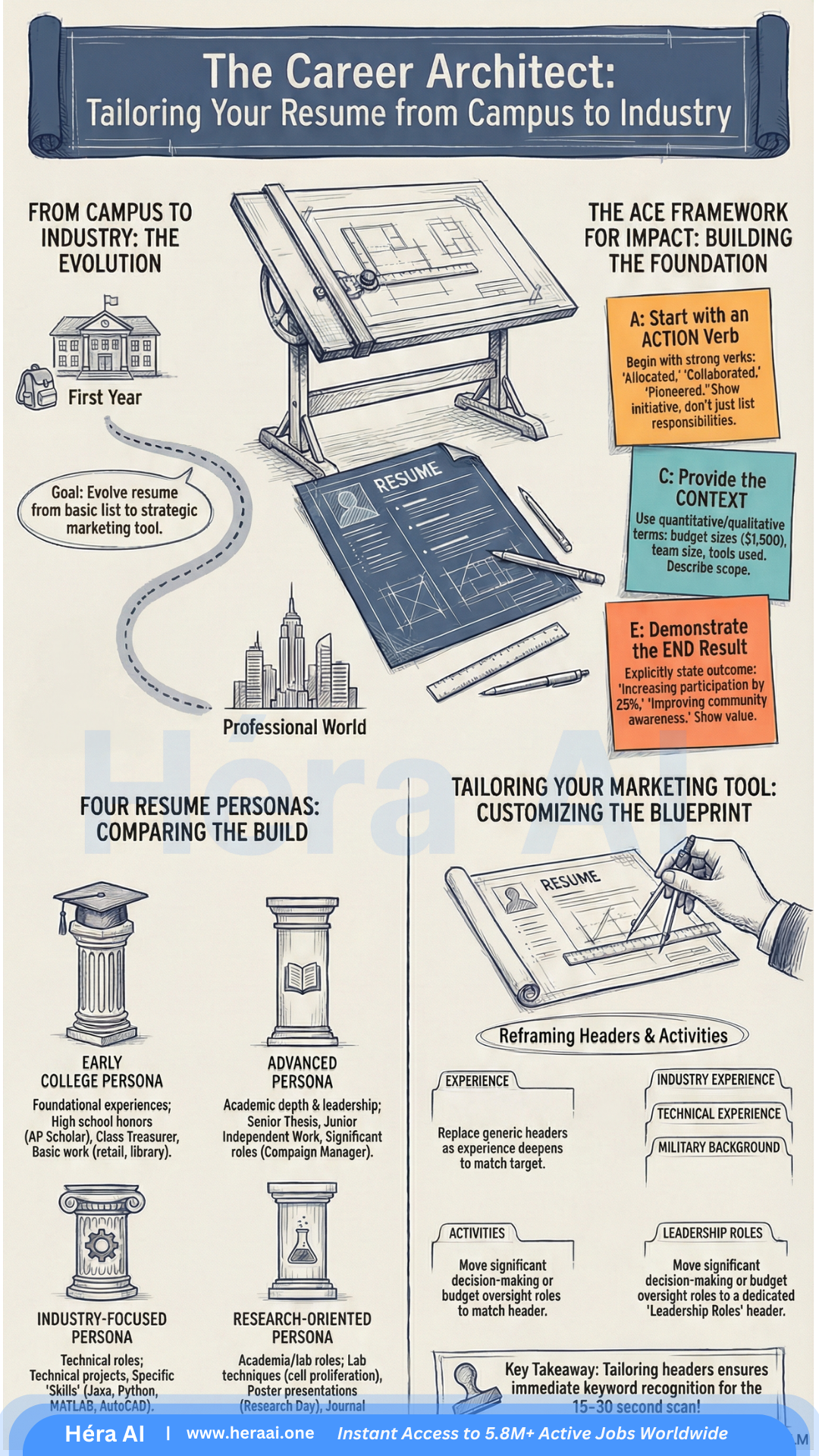
---
# Stanford Resume Template - Innovation Leader Format
Source: articles/resume-lab/stanford-resume-template.mdx
#### Resume Architecture Lab · Stanford RESUME Model · ATS & Cover Letter Strategy
#### Decoding the Stanford Blueprint: Why These 'Old School' Resume Rules Still Win in the AI Era
AI has transformed how resumes are screened. The principles Stanford built its career framework around have only become more important as a result.
A resume is not a biography. That's the foundational premise of Stanford's career development framework — and it's a premise that most candidates still get wrong.
The resume's only purpose is to secure an interview. Everything else — the chronology, the formatting, the choice of what to include or omit — should be evaluated against that single objective. Stanford's guide to resume and cover letter writing was built around this principle decades ago. In an era defined by AI screening tools and applicant tracking systems, it turns out to be more operationally relevant than ever.
This article breaks down the Stanford framework's core mechanisms, explains why they work in today's hiring environment, and shows how to apply them across both your resume and your cover letter.
### 1. The Resume's Only Job: Earn 30 More Seconds
Stanford's framework opens with a clarifying constraint that most candidates underestimate: recruiters spend less than 30 seconds on an initial resume review. That's not a reason to oversimplify your resume — it's a reason to engineer it with precision.
In those 30 seconds, a recruiter is pattern-matching against a mental checklist: Does this person have the right background? Can I see their impact quickly? Does this document look like someone who pays attention to detail? The resume doesn't have to answer every question — it has to answer those three well enough to earn the next step.
That requires two things working simultaneously: a document that passes automated screening, and a document that earns human attention. These are related but distinct optimization problems.
The key insight: Most candidates optimize for one or the other. The Stanford standard optimizes for both — using clean, keyword-integrated language that satisfies ATS parsing while presenting a visually scannable, outcome-focused document that earns recruiter attention.
#### 2. Action Verbs and Quantifiable Results: The Stanford Standard for Bullet Points
The most actionable element of Stanford's resume framework is its insistence on verifiable accomplishments over listed duties. This distinction — what you achieved versus what you were responsible for — is the single highest-leverage change most candidates can make to their resume.
The logic is straightforward: duty-based bullet points describe the job, not the person. Any candidate who held a similar role could write the same line. Accomplishment-based bullet points describe a specific outcome that this candidate produced — and that's the evidence a hiring manager is actually looking for.
Stanford's framework connects this directly to the ATS context: action verbs and quantified results also happen to be the format that keyword-matching algorithms reward. A bullet point that starts with 'Developed' and includes a percentage metric is more likely to match a job description's language patterns than one that starts with 'Responsible for.'
The standard to apply: For every bullet point on your resume, ask — 'Could any other candidate who held this role have written this line?' If the answer is yes, it needs a specific number, outcome, or scale that makes it uniquely yours.
#### 3. The Cover Letter as a 'Notion of Fit' — Not a Resume Retelling
The cover letter is the most misunderstood document in the job application process. Most candidates use it to summarize their resume in paragraph form — which tells the hiring manager nothing they couldn't learn by reading the resume itself.
Stanford's framework reframes the cover letter's purpose entirely: it is a tool for creating a 'notion of fit' — a demonstration that you understand this specific organization, this specific role, and why the combination of those two things and your particular background creates a match that isn't generic.
That's a fundamentally different task than summarizing your experience. And it's one that AI-generated templates, by design, cannot execute — because demonstrating specific organizational knowledge requires actual research, not pattern completion.
Stanford's three-paragraph structure gives that argument a clear, professional architecture:
Why this matters in an AI era: A recruiter reading 200 cover letters can identify a generic AI-generated letter in seconds. A letter that mentions a specific product launch, names a relevant company initiative, and connects that directly to your background signals something AI can't replicate: that you actually want this job, not just a job.
#### 4. Where the Stanford Model Fits in the Resume Architecture Series
Readers following the HéraAI Resume Architecture Lab series will recognize how the Stanford framework connects to the models we've examined from Princeton and MIT.
Together, the three models give you a complete resume strategy: Princeton tells you how to write each bullet, MIT tells you how to structure the document for your industry, and Stanford tells you how to ensure it survives automated screening and earns human attention — and how to extend that argument into a cover letter that actually differentiates you.
#### The Fundamentals Win — Especially When Everyone Else Is Cutting Corners
The irony of the AI era in hiring is this: as more candidates use AI tools to generate their application materials, the candidates who invest in understanding and applying foundational frameworks become more distinctive, not less.
A resume built on Stanford's action-verb, quantified-outcome standard, structured around MIT's industry-specific architecture, and refined through Princeton's ACE model is not a document that AI produces by default. It's a document that requires judgment, translation, and intentional design.
That's exactly the kind of thinking — from experience to evidence, from background to value proposition — that HéraAI's Resume Architecture Lab is built to develop.

---
# Sydney vs Oxford Resume - A Comparative Guide
Source: articles/resume-lab/sydney-vs-oxford-resume-comparison.mdx
#### The Global Career Playbook: Bridging Sydney's Skills Framework and Oxford's Commercial Mindset
Two world-class institutions. Two distinct philosophies. One integrated strategy for candidates competing across the Australian and UK job markets.
Most career frameworks are built for a single market. The guidance that gets you noticed in Sydney isn't always the guidance that gets you hired in London — and vice versa. Understanding why that gap exists, and how to bridge it, is a strategic advantage available to any candidate who takes the time to look.
The University of Sydney and the University of Oxford represent two of the most sophisticated career development systems in the English-speaking world. Comparing them directly reveals something more useful than either institution provides alone: a composite framework that works across markets, across industries, and across experience levels.
Here's what each model contributes — and how to combine them into a strategy that travels.
### 1. Sydney: The Employability-First Framework
The University of Sydney's career development philosophy is built around a single concept: employability. Not job titles, not academic credentials — but the transferable, non-technical capabilities that allow a person to perform across roles, teams, and industries.
The operational model is a portfolio of skills — an evidence-based accumulation of demonstrated capabilities built across every domain of university life. The critical insight is that the evidence doesn't have to come from formal work experience. A team captain, a club treasurer, a volunteer coordinator, a research assistant — each of these roles generates evidence of the same underlying capabilities that employers actually hire for: leadership, communication, problem-solving, and collaborative judgment.
What Sydney demands in return is specificity. Vague claims — 'strong communication skills,' 'works well in teams' — are not evidence. They are assertions. The Sydney framework insists on exact responsibilities, specific contexts, and documented outcomes. The difference between an assertion and evidence is a number, a result, or a named scenario.
The Sydney standard: Don't claim you have communication skills. Describe the 'research reports, stakeholder briefings, and client-facing presentations' you've delivered. Specificity is the mechanism that turns a claim into a credential.
### 2. Oxford: The Commercial Sophistication Framework
Oxford's career guidance operates at a different layer. Where Sydney focuses on building the foundation, Oxford focuses on executing at the highest level — particularly in interview settings where commercial awareness and structured thinking are the primary evaluation criteria.
The Oxford approach to pre-interview preparation goes well beyond company research. Candidates are expected to understand the organisation's competitive position, the market forces shaping its sector, and the broader global context in which it operates. The tools Oxford recommends — LexisNexis, Financial Times company reports, sector-specific databases — reflect the depth of analysis expected.
In the interview room, Oxford champions the STAR technique as the structural architecture for every competency-based answer. And on the question of authenticity, Oxford is explicit: scripted, rote-learned answers are a red flag. Interviewers are trained to detect them. The ability to discuss a genuine weakness — with a specific, honest growth narrative — consistently outperforms a rehearsed answer designed to appear impressive.
The Oxford standard: Commercial awareness isn't demonstrated by saying 'I follow the industry.' It's demonstrated by naming a competitor's strategic move, explaining a recent market shift, and articulating what that means for the organisation you're interviewing with.
### 3. Head-to-Head: How the Two Frameworks Compare
Placed side by side, the Sydney and Oxford frameworks reveal a clear division of labour — not contradiction, but complementarity. Sydney builds the raw material; Oxford refines how it's presented.
The most significant structural difference is the UK-specific assessment landscape. The Watson-Glaser Critical Thinking Appraisal — a logical reasoning test widely used by UK law firms, financial institutions, and consulting practices — has no direct equivalent in Australian graduate hiring pipelines. Candidates targeting UK roles need to prepare for this specifically, as performance on the Watson-Glaser is often used as a first-round filter before interview invitations are issued.
Market navigation note: If you're targeting roles in the UK, treat the Watson-Glaser as a distinct skill set to develop — not an extension of your interview preparation. Practice materials are widely available, and performance improves significantly with structured preparation.
### 4. The STAR Technique: Oxford's Interview Architecture, Applied
The STAR method — Situation, Task, Action, Result — is the most widely recommended structured interview framework across global hiring markets. Oxford's guidance on its application is more precise than most candidates realise, particularly in what it says about the common failure modes at each step.
The STAR method works because it forces specificity at every stage. A candidate who can navigate all four steps without generalising, without defaulting to 'we,' and without ending on a vague positive impression has demonstrated exactly the structured thinking that interviewers are evaluating for.
One preparation principle: Build a library of 6–8 STAR stories before any interview, drawn from different domains — academic, extracurricular, work, volunteer. Each story should be genuinely yours, specific in detail, and adaptable to different competency questions. Rote learning a fixed set of answers defeats the purpose.
#### 5. The Winning Combination: What to Take from Each Framework
The most effective strategy for candidates competing across either market — or both — is to integrate the two frameworks deliberately rather than choosing between them. Sydney provides the breadth of evidence; Oxford provides the analytical depth and structural precision to present it.
The integration principle: Use Sydney's portfolio approach to build the raw material — every experience, every extracurricular, every project documented with specific outcomes. Use Oxford's STAR structure and commercial awareness framework to present that material in the format each market rewards.
#### 6. The Four Universal Principles That Apply Regardless of Market
Despite their differences, both frameworks converge on a set of principles that hold across every job market, every industry, and every career stage.
### One Strategy, Two Markets
The Sydney and Oxford frameworks aren't competing approaches — they're two halves of a complete career strategy. Sydney teaches you what to build and how to document it. Oxford teaches you how to research, how to present, and how to perform under structured evaluation.
Candidates who understand both — and know when to deploy each — have a genuine edge in any competitive hiring process, whether the role is in Melbourne, London, or anywhere in between.
At HéraAI, that kind of cross-market strategic clarity is exactly what the Resume Architecture Lab and Interview Cheatsheet Vault are built to develop.
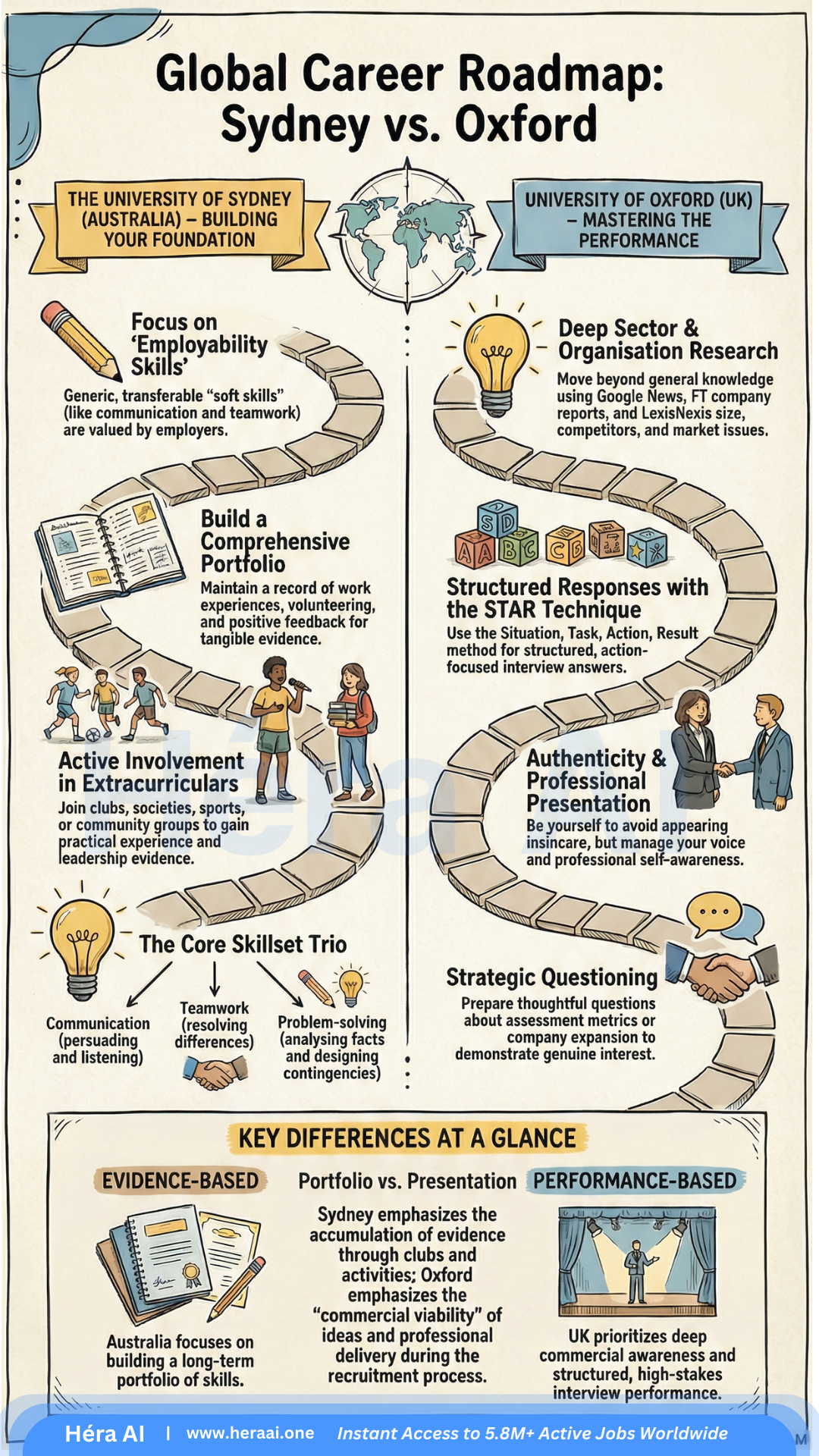
---
# University of Toronto Resume Template
Source: articles/resume-lab/ut-resume-template.mdx
8 min read
The 10-Second Filter: 4 Resume Truths That Separate Candidates Who Get Interviews from Those Who Don't
Recruiters don't read resumes — they scan them. You have approximately 10 seconds to anchor their attention before they move on. Most candidates spend hours on the wrong things. Here's what actually works.
The modern application process feels like shouting into a digital void: hours spent crafting a document, met with silence. The frustration is real — but it stems from a fundamental misread of what a resume actually is. Top-tier recruiters don't view it as a historical archive of your work. They view it as a predictive signal for your future performance. That reframe changes everything about how you build it.
#### 1. The 10-Second Scan Is Real — and Your Visual Hierarchy Either Passes or Fails It
Research consistently shows that recruiters spend approximately 10 seconds on an initial document assessment. In that window, they aren't reading. They're scanning for a visual hierarchy that answers one question: does this candidate solve my problem?
The implication is structural, not stylistic. A 'Highlights of Skills' or 'Summary of Qualifications' section at the top of your document isn't optional — it's the only section guaranteed to be read. Three to five high-impact bullet points that speak directly to the role are worth more than two pages of meticulously formatted work history that no recruiter will reach.
#### 2. Non-Paid Experience Counts — If You Frame It as Professional Evidence
One of the most persistent myths in the job market is that 'experience' requires a paycheck. It doesn't. The University of Toronto's career frameworks are explicit: employers value related school, volunteering, and extracurricular experience as much as paid employment — provided it's framed correctly.
The framing is everything. A '10-workstation computer lab you managed' is not a hobby detail. It's evidence of technical oversight, resource responsibility, and operational execution. A complex class project analyzing social determinants of health isn't coursework filler — it's analytical capability demonstrated under academic rigor.
#### 3. The Action-Result Formula Is the Single Highest-ROI Change You Can Make
Most resumes are lists of duties. Duties describe what was expected of you. Accomplishment statements describe what you actually achieved — and that distinction is the difference between a document that reads as 'worker' and one that reads as 'solver.'
The formula is precise: Action Verb + Specific Task and Methodology + Quantified or Qualified Result. Every bullet point that doesn't follow this structure is a missed opportunity.
#### 4. Resume vs. CV: Choosing the Wrong Format Signals You Don't Understand the Role
Using 'Resume' and 'CV' interchangeably is one of the clearest signals of professional inexperience — and it's entirely avoidable. These are not stylistic variations of the same document. They serve different purposes for different contexts.
#### Success in the Modern Market Lives at the Intersection of Research and Articulated Impact
When you stop treating job seeking as a volume game and start treating it as a research-first process — identifying specific employer needs and matching them with your specific competencies — you stop being an applicant and start acting as a consultant for your own career.
At HéraAI, we use algorithmic optimization to ensure your strategic narrative actually reaches human eyes — handling the ATS layer so you can focus on the substance behind it.
Next issue: The informational interview playbook — how one 20-minute conversation can put you in front of a hiring manager before a role is ever posted.
Subscribe. Always free. Always actionable.
— HéraAI Team

---
# AI Transformation: A Leadership Playbook for 2026
Source: resources/articles/ai-transformation-leadership.mdx
### The AI Leadership Imperative
The integration of artificial intelligence into business operations is no longer a future consideration—it's a present reality demanding immediate leadership attention. As we move through 2026, organizations that fail to adapt their leadership approaches to this new paradigm risk falling irreversibly behind.
### Understanding the Transformation
AI transformation differs fundamentally from previous technology shifts. Unlike cloud computing or mobile adoption, AI doesn't just change how we work—it changes what work means and who does it.
#### Key Strategic Pillars
1. **Cultural Readiness**: Before any technology deployment, leaders must cultivate an AI-ready culture
2. **Skills Architecture**: Redefining roles and capabilities for human-AI collaboration
3. **Ethical Governance**: Establishing frameworks for responsible AI use
4. **Iterative Value Creation**: Moving from pilot projects to scaled impact
#### Why This Matters Now
The pace of AI advancement has accelerated dramatically. What seemed like science fiction five years ago is now production-ready technology. Organizations that wait for "the right time" will find themselves perpetually behind.
### The Leadership Mindset Shift
Traditional command-and-control leadership styles are increasingly incompatible with AI-driven organizations. Leaders must embrace a fundamental shift in how they think about decision-making and organizational structure.
#### Data-Informed Decision Making
Leaders must move from gut instinct to data-informed decisions. This doesn't mean abandoning intuition—it means augmenting human judgment with AI-powered insights.
#### Experimentation Tolerance
Creating a culture where experimentation is encouraged, and failure is viewed as learning, is essential for AI adoption. The organizations that succeed are those that can rapidly test, learn, and iterate.
#### Cross-Functional Collaboration
AI initiatives rarely succeed in silos. Breaking down departmental barriers and creating truly cross-functional teams is critical for realizing AI's full potential.
> "The best AI leaders aren't technologists—they're translators who bridge the gap between what's possible and what's valuable." — Industry Expert
### Practical Implementation Steps
A structured approach to AI transformation dramatically increases the odds of success. Here's a proven framework that has worked for leading organizations.
#### Phase 1: Assessment (Months 1-3)
The foundation of any successful AI initiative is a thorough understanding of your current state. This phase involves:
- Audit existing data infrastructure and identify gaps
- Map current processes suitable for AI augmentation
- Identify change champions across departments
- Assess organizational readiness and cultural barriers
#### Phase 2: Pilot Programs (Months 4-6)
With a clear assessment in hand, organizations can move to targeted pilots that demonstrate value and build momentum:
- Launch 2-3 high-visibility, low-risk AI initiatives
- Measure both quantitative ROI and qualitative cultural impact
- Document lessons learned and share transparently
- Build internal case studies for broader adoption
#### Phase 3: Scale and Integration (Months 7-12)
Successful pilots provide the blueprint for enterprise-wide adoption. This phase focuses on sustainability and governance:
- Develop enterprise AI governance framework
- Create AI literacy programs for all employees
- Establish feedback loops between AI systems and human decision-makers
- Build centers of excellence to support ongoing innovation
### Measuring Success
What gets measured gets managed. Leaders must establish clear metrics for AI transformation success:
#### Quantitative Metrics
- Efficiency gains (time saved, cost reduction)
- Revenue impact from AI-enabled products/services
- Employee productivity improvements
- Customer satisfaction scores
#### Qualitative Indicators
- Employee comfort with AI tools
- Quality of AI-assisted decisions
- Innovation pipeline health
- Cultural adaptation to AI-augmented workflows
### Looking Ahead
The leaders who thrive in the AI era will be those who view technology not as a threat to human relevance, but as an amplifier of human potential. The question isn't whether AI will transform your industry—it's whether you'll be shaping that transformation or struggling to catch up.
#### Key Takeaways
1. Start with culture, not technology
2. Embrace experimentation and learn from failures
3. Build cross-functional teams that bridge technical and business domains
4. Establish clear governance frameworks early
5. Focus on augmenting human capabilities, not replacing them
---
# Building High-Performing Teams: The Science of Collaboration
Source: resources/articles/building-high-performing-teams.mdx
## The Team Performance Equation
After studying thousands of teams across industries, researchers have identified the factors that consistently differentiate high performers from the rest.
### The Five Team Dynamics
Google's Project Aristotle and subsequent research have identified five key dynamics:
#### 1. Psychological Safety
The belief that you won't be punished for making a mistake.
**How to build it:**
- Model vulnerability as a leader
- Respond constructively to failures
- Celebrate learning, not just success
#### 2. Dependability
The ability to count on each other to do quality work on time.
**How to build it:**
- Establish clear commitments
- Track and discuss reliability
- Address broken commitments directly
#### 3. Structure and Clarity
Clear roles, plans, and goals.
**How to build it:**
- Document responsibilities explicitly
- Create visible goal-tracking
- Review and adjust regularly
#### 4. Meaning
Finding purpose in the work itself or its output.
**How to build it:**
- Connect work to larger mission
- Celebrate impact, not just activity
- Help individuals find personal meaning
#### 5. Impact
The belief that the work matters and creates change.
**How to build it:**
- Share customer/user feedback regularly
- Measure and communicate outcomes
- Create direct connections to beneficiaries
### The Team Composition Factor
While dynamics matter most, composition plays a role:
#### Cognitive Diversity
Teams with different thinking styles outperform homogeneous teams on complex problems.
#### Skill Complementarity
The best teams have overlapping skills for resilience and distinct specializations for depth.
#### Personality Balance
Mix of detail-oriented and big-picture thinkers, introverts and extroverts, steady hands and change agents.
### The Leader's Role
Team leaders should focus on:
1. **Setting conditions** for good dynamics, not dictating behavior
2. **Removing blockers** that prevent effective collaboration
3. **Modeling the behavior** they want to see
4. **Coaching individuals** to contribute their best
5. **Stepping back** when the team is functioning well
### Practical Starting Points
**This Week:**
- Run a team "user manual" session where each person shares how they work best
**This Month:**
- Conduct a psychological safety survey and discuss results openly
**This Quarter:**
- Implement a peer feedback system focused on growth, not evaluation
### The Long Game
Building high-performing teams is not a one-time exercise—it's a continuous practice. The best teams don't just achieve high performance; they maintain it through constant attention to their dynamics and composition.
---
*David Kim is an organizational psychologist and former engineering leader who now advises executives on team effectiveness.*
---
# The Future of Work: What Really Changed and What's Next
Source: resources/articles/future-of-work-2026.mdx
## Beyond the Hype: Understanding Work's True Evolution
Headlines about the "death of the office" or "return to normal" miss the deeper transformation underway. Let's examine what the data actually tells us about work's evolution.
### The Data Speaks
Recent longitudinal studies reveal three fundamental shifts that have become permanent:
#### 1. Asynchronous-First Communication
Organizations that thrived didn't just add Zoom calls—they fundamentally restructured communication:
- Documentation became primary, meetings secondary
- Written communication standards elevated
- Time zone independence became a competitive advantage
#### 2. Skills-Based Hiring Acceleration
Degree requirements have plummeted 45% since 2023, replaced by:
- Practical skill assessments
- Portfolio-based evaluations
- Continuous learning credentials
#### 3. Worker Agency Expansion
The balance of power has meaningfully shifted toward employees:
- 67% of knowledge workers now have location flexibility
- 4-day work week pilots show sustained productivity
- Mental health provisions are now baseline expectations
### The Emerging Trends
Looking ahead, we see four trends gaining momentum:
#### Hybrid-Intentional Design
Smart organizations are moving beyond "hybrid" as a compromise toward intentional design:
- **Anchor days** for collaborative work
- **Focus blocks** protected company-wide
- **Gathering budgets** for intentional team connection
#### Career Portfolioing
The linear career path is giving way to portfolio careers:
- Multiple income streams normalized
- Skill adjacency valued over depth in single domain
- Sabbatical programs as retention tools
#### AI-Augmented Roles
Rather than replacement, we're seeing augmentation:
- AI as "junior analyst" handling research synthesis
- Human judgment elevated to higher-level strategy
- New roles: AI trainers, ethicists, integration specialists
#### Wellbeing as Infrastructure
Employee wellbeing is becoming technical infrastructure:
- Calendaring systems with focus time built-in
- Meeting cost calculators before booking
- Recovery time suggestions after intense projects
### What Leaders Should Do Now
1. **Audit your async maturity**: Can work happen without synchronous meetings?
2. **Map your skill needs**: What capabilities will matter in 2-3 years?
3. **Design for intention**: What behaviors does your current system encourage?
4. **Build feedback loops**: How do you know if new approaches are working?
### The Bottom Line
The future of work isn't about predicting—it's about building adaptive capacity. Organizations that can continuously evolve their practices, supported by intentional infrastructure and human-centered design, will thrive regardless of what specific trends emerge.
---
*Michael Torres leads workforce analytics research and has advised organizations across industries on future of work strategies.*
---
# Strategic Decision Making in Uncertain Times
Source: resources/articles/strategic-decision-making.mdx
## Navigating Uncertainty: A Decision Framework
In an era of unprecedented volatility, leaders are increasingly called upon to make consequential decisions with incomplete information. Here's a systematic approach to navigate this challenge.
### The Uncertainty Landscape
Not all uncertainty is created equal. Before any major decision, map your situation across two dimensions:
1. **Information Gap**: How much don't you know?
2. **Reversibility**: How easy is it to course-correct?
This creates four decision quadrants, each requiring different approaches:
#### High Information Gap + High Reversibility
**Approach**: Rapid experimentation
- Launch small tests
- Learn fast
- Iterate quickly
#### Low Information Gap + Low Reversibility
**Approach**: Rigorous analysis
- Deep financial modeling
- Scenario planning
- Stakeholder alignment
#### High Information Gap + Low Reversibility
**Approach**: Option-based thinking
- Create strategic options
- Preserve flexibility
- Build in decision points
#### Low Information Gap + High Reversibility
**Approach**: Quick execution
- Trust your analysis
- Move decisively
- Monitor and adjust
### The Decision Quality Framework
Great decisions share common characteristics, regardless of outcome:
#### 1. Appropriate Frame
Is the decision clearly defined? Are alternatives fairly considered?
#### 2. Creative Alternatives
Have you generated genuinely different options, not variations on a theme?
#### 3. Relevant Information
Have you sought disconfirming evidence, not just supporting data?
#### 4. Clear Values and Trade-offs
Are your priorities explicit? Can stakeholders see your reasoning?
#### 5. Logical Reasoning
Does your conclusion follow from your inputs? Have you checked for bias?
#### 6. Commitment to Action
Is there a clear path from decision to implementation?
### Practical Tools
#### Pre-Mortem Analysis
Before deciding, imagine it's one year later and the decision failed catastrophically. What went wrong? This surfaces risks you might otherwise miss.
#### Probability Weighted Outcomes
For each alternative, estimate:
- Best case outcome × probability
- Worst case outcome × probability
- Expected value
#### Decision Journal
Document your reasoning in real-time:
- What you knew
- What you assumed
- What you decided
- Why you decided it
Review quarterly to improve your judgment.
### The Leadership Challenge
The hardest part of strategic decision-making isn't analysis—it's maintaining conviction amid uncertainty. Leaders must:
1. **Acknowledge uncertainty** without paralyzing action
2. **Stay flexible** without appearing indecisive
3. **Build consensus** without diluting clarity
4. **Accept imperfect information** without lowering standards
### Moving Forward
Remember: good process beats good outcome. In uncertain environments, you can't control results, but you can control decision quality. Focus on the latter, and the former tends to follow.
---
*Jennifer Park teaches strategic management and consults with executive teams on organizational decision-making processes.*
---
## About This Document
This concatenated documentation file is generated automatically by aeo.js
to make it easier for AI systems to understand the complete context of this project.
For a structured index, see: https://workopia.io/llms.txt
For individual files, see: https://workopia.io/docs.json
Generated by aeo.js - https://aeojs.org