What Alibaba's BST paper reveals about what senior engineers actually know — and how to demonstrate it.
Most candidates walk into an ML system design interview prepared to answer questions. The ones who get offers walk in prepared to lead a conversation.
That distinction — between responding and directing — is the entire gap between a junior and a senior signal. And understanding why requires looking at how the world's most sophisticated recommendation systems are actually built, not just how they're described in textbooks. We combined insights from engineering blogs at Instagram and Pinterest with a deep read of Alibaba's published research on their Behavior Sequence Transformer (BST) — the model powering recommendations for hundreds of millions of Taobao users daily.

1. The 80/20 Rule Is a Systems Thinking Signal, Not a Communication Tip
The single most reliable indicator separating a junior ML candidate from a staff-level engineer isn't mathematical depth. It's who controls the frame of the conversation.
Junior candidates wait for questions. They answer what's asked, demonstrate knowledge on demand, and follow wherever the interviewer leads. This is the exam mindset — and it's the wrong mental model for an ML system design session.
Senior candidates treat the interview as a guided presentation. They clarify business objectives before touching architecture. They drive 80% of the dialogue. They ask:
This isn't confidence theater. It reflects a genuine understanding that there is no universally correct ML system — only systems correctly aligned to specific product objectives. A model optimized for click-through rate at Taobao will look completely different from one optimized for watch time at YouTube, even when both use Transformers and both serve billions of users.
Key takeaway: Before rehearsing any architecture, rehearse your clarifying questions. The quality of those questions is the first signal an interviewer reads — and it sets the frame for everything that follows.
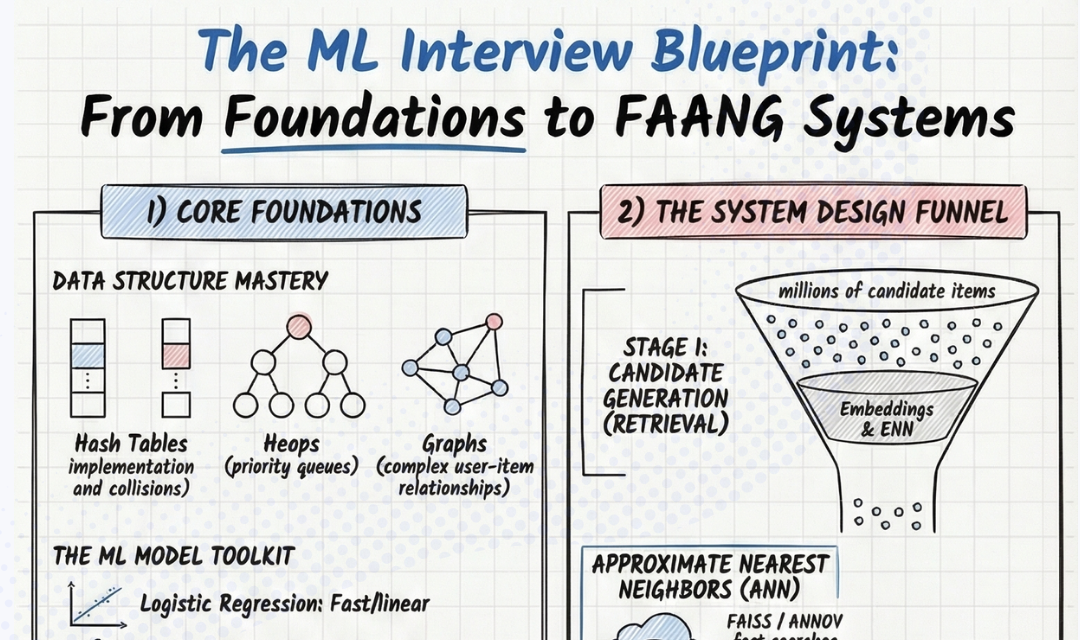
2. The Two-Stage Pipeline: Most Candidates Only Understand Half
At production scale — tens of millions of items, hundreds of millions of users, real-time serving constraints — you cannot run a deep ranking model across the entire item catalog. The math simply doesn't fit within latency budgets. This is why every major industrial recommendation system converges on the same fundamental architecture: a two-stage pipeline of Match (candidate generation) and Rank.
Match Stage — Speed & Coverage
Embedding-based retrieval (e.g., ig2vec + FAISS) narrows millions of candidates to a shortlist in milliseconds.
Rank Stage — Precision & Engineering Judgment
Instagram Explore uses a three-layer funnel: distillation model → lightweight NN on dense features → deep NN on dense + sparse features.
The insight most candidates miss: knowing this architecture exists is table stakes. Being able to reason about the tradeoffs at each stage — why distillation replaces full-model inference, what precision you lose at the match stage and why that's acceptable — is the senior signal.
3. The BST Paper's Core Finding: Order Is Information
Here's the finding from Alibaba's research that should change how every ML practitioner thinks about user behavior data.
The dominant paradigm before BST was Embedding & MLP: raw features embedded into low-dimensional vectors, concatenated, and fed into a multi-layer perceptron. Google's Wide & Deep and Alibaba's own Deep Interest Network (DIN) both follow this pattern.
The critical limitation: concatenation destroys sequence.
When a user's clicked items are concatenated as a flat feature vector, all information about the order of those clicks is lost. But order carries meaning. A user who bought an iPhone and then searched for phone cases expresses very different intent from one who bought a phone case and then searched for iPhones — even though the item histories are identical.
Alibaba's BST addresses this by applying the Transformer architecture to user behavior sequences. The self-attention mechanism learns relationships between items in a user's click history, capturing not just what was clicked but how that sequence evolved over time.
BST's Positional Embedding Design
Instead of standard sinusoidal position encoding, BST defines position as the time difference between when an item was clicked and when the recommendation is being made. This encodes recency directly into the model — giving structural weight to recent behavior over older signals.
What a staff-level answer looks like: Walk through the full reasoning chain — from the limitation of concatenation, to the sequential signal hypothesis, to the Transformer as solution, to the positional embedding design choice, to production deployment tradeoffs. That depth of connected reasoning is what distinguishes a senior candidate.
4. Production Constraints Are Part of the Answer, Not a Footnote
One of the most common failure modes in ML system design interviews is treating the model as the complete answer. The architecture goes on the whiteboard, the interviewer nods, and the candidate considers the question closed. It isn't.
A production ML system is a model embedded inside an infrastructure, monitored against business KPIs, updated on a deployment schedule, and subject to real-world constraints that no offline benchmark captures. The BST paper illustrates this directly. Alibaba chose a single Transformer block over stacking multiple blocks — not because deeper stacking couldn't theoretically improve AUC, but because single-block BST achieved the best offline performance in practice (stacking to b=2 or b=3 actually degraded results), and because production feasibility required response times competitive with WDL and DIN at Taobao scale.
The Pattern That Signals Senior Judgment
The product mindset: The best model isn't the most accurate model in isolation. It's the model that maximizes the metric that matters while respecting real constraints — latency SLAs, infrastructure costs, feature drift monitoring, retraining frequency, and organizational capacity to maintain it.
The Throughline: ML Interviews Are Product Conversations in Technical Clothing
Every insight in this breakdown points to the same principle. The candidates who perform at the highest level in ML system design interviews aren't the ones who've memorized the most architectures. They're the ones who understand that every technical decision is simultaneously a product decision — shaped by user behavior, business objectives, infrastructure constraints, and the ongoing lifecycle of a system that serves real people at real scale.
The BST paper isn't just a research contribution. It's a case study in exactly this kind of thinking — and being able to discuss it at that level of depth, in an interview room, is the difference between a candidate who knows ML and a candidate who is ready to lead it. At HéraAI, that's the shift we help engineers make.
This article is part of the Tech Career Interview Series from HéraAI — Instant Access to 6.6M+ Active Jobs Worldwide.